一句话搞定全套设计?Lovart AI 全自动设计实测体验



深圳/产品设计师/1年前/4997浏览
版权
一句话搞定全套设计?Lovart AI 全自动设计实测体验
大家好,我是言川。
设计圈最近终于迎来了第一个真正意义上的 AI 智能体工具——
Lovart AI
。
这款产品在过去两周几乎被刷屏,相信不少朋友已经在社交平台上见过它的身影。我在拿到内测账号后,也立刻开始跑案例、测效果——直接看图吧👇
今天这篇内容,我将带大家全面了解 Lovart AI,包括它的
产品介绍、核心功能、操作示例,以及实际应用场景。
文中还会附上案例的
生成回放链接
,方便大家参考学习。
开篇照例,先厚着脸皮求个三连支持一下!这次我光是跑图测试就花了 30 多个小时......
那我们现在,正式开始👇
一、产品介绍
Lovart AI 是由 Liblib AI 的海外子公司推出的全球首个专注于设计领域的 AI 智能体(Design Agent)。于 2025 年 5 月发布 Beta 版本,用户可通过自然语言交互,实现从创意构想到成品交付的全流程自动化设计。
Lovart AI 地址(需要申请内测资格):https://www.lovart.ai/
二、核心功能
1、自然语言生成设计
用户只需通过对话式指令输入需求,Lovart AI 即可自动生成品牌包装、插画、LOGO 等多种视觉内容。
2、多模态模型集成
平台整合了 GPT image-1、Flux Pro、Gemini Imagen 3 等主流 AI 模型,支持图像、视频、音乐等多种内容的生成,能根据不同的设计需求自动选择最适合的模型。

3、智能任务拆解
Lovart AI 能将用户的需求自动拆解为多个设计步骤,生成详细的设计方案,并支持图文分离,用户可直接在画布中修改文字、调整布局。
4.图像编辑功能
提供放大、扩图、抠图、消除、修复、涂抹模糊等编辑功能,支持对生成图片的二次修改。
三、操作示例
下面我通过一个
汽车宣传物料的实战案例
,来实际演示 Lovart AI 的能力。整个案例将覆盖三个核心板块:
图像创作、视频创作和详情页创作
。
这次的主要目的是——
测试 Lovart AI 是否能真正跑通一整套产品物料设计流程,形成完整的闭环
。
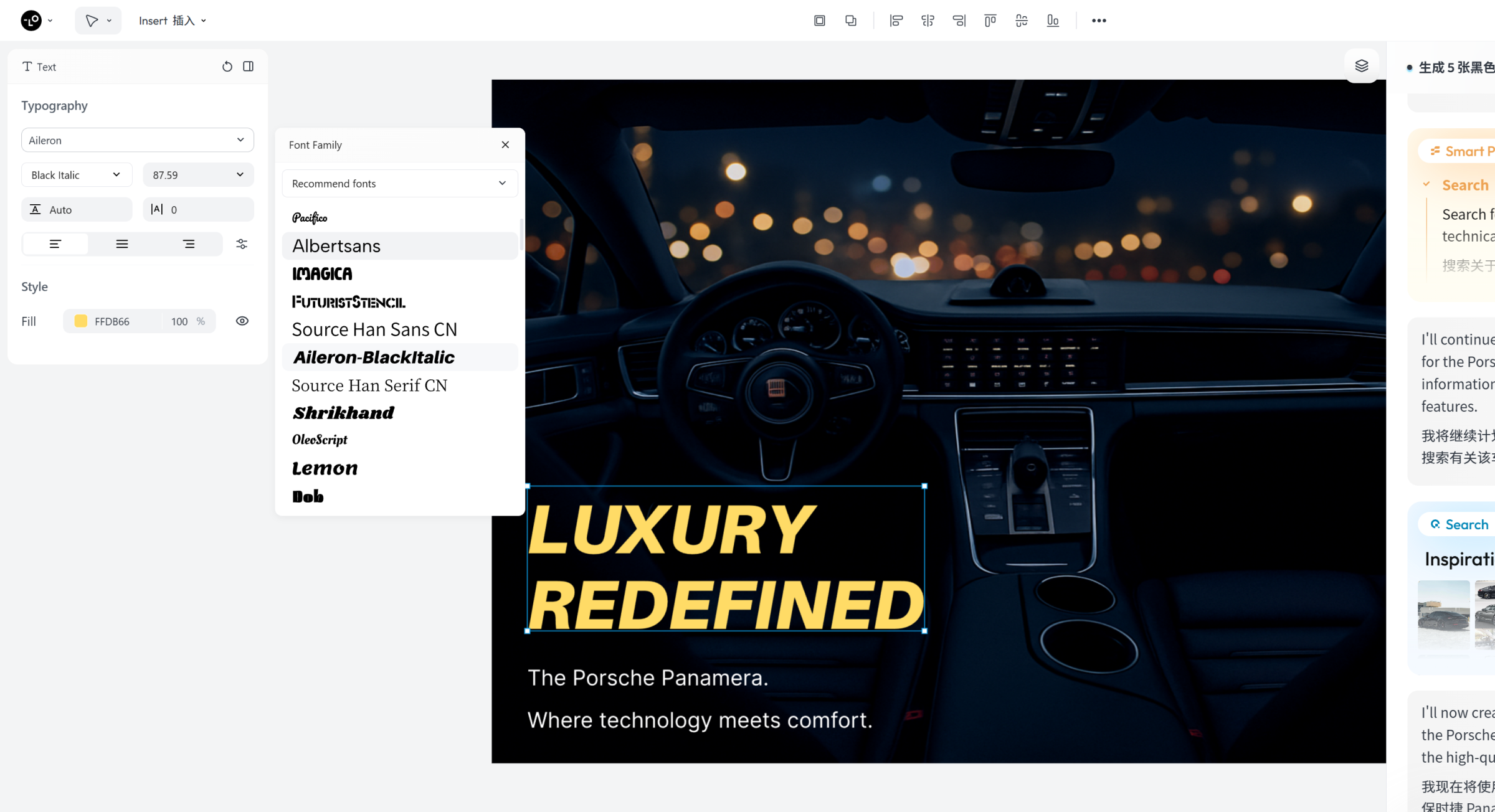
1、图像生成
1.1 产品渲染图
提示词指令:
生成 5 张黑色保时捷帕拉梅拉的高清图片,涵盖正面视角、侧面视角、后部视角、俯视视角、内饰视角,拍摄场景统一是夜晚城市街道,尺寸统一为16:9。

Lovart AI 在接收到指令后,会
自动将整个任务流程拆解为 4 个步骤
:
①
Search
:从网上收集关于帕拉梅拉的车型参数、外观图像等基础信息;

② Smart Plan:
规划图像生成的步骤,分别是 Knowledge 和 ChatGPT Image 。

③ Knowledge:
提供设计参考方向以及撰写提示词。

④ ChatGPT Image:
调用 ChatGPT Image 模型,执行图像生成。

最终输出了 5 张符合描述的汽车渲染图。

整个流程无需人工干预,完全由 AI 自主完成,达成了AI+设计链路的自动化闭环。
但它生成的图像比例并不准确。
我原本的尺寸要求是标准的
16:9
,结果它给我整了个
1024×1536
,直接变成了
2:3 的“竖版图”
。
翻回去看了一眼
Knowledge 阶段的流程拆解
,发现它在那一步就已经
自作主张地推荐了 1024×1536 的尺寸
,导致整个后续流程都跟着这个错误尺寸走了。

所以我再次对它下达了一段指令,让它帮我正确的生成。
提示词指令:
现在生成的5张图像尺寸并未是16:9,请重新生成。
Smart Plan 会重新规划任务,并调用 GPT-4o 模型生成图像。
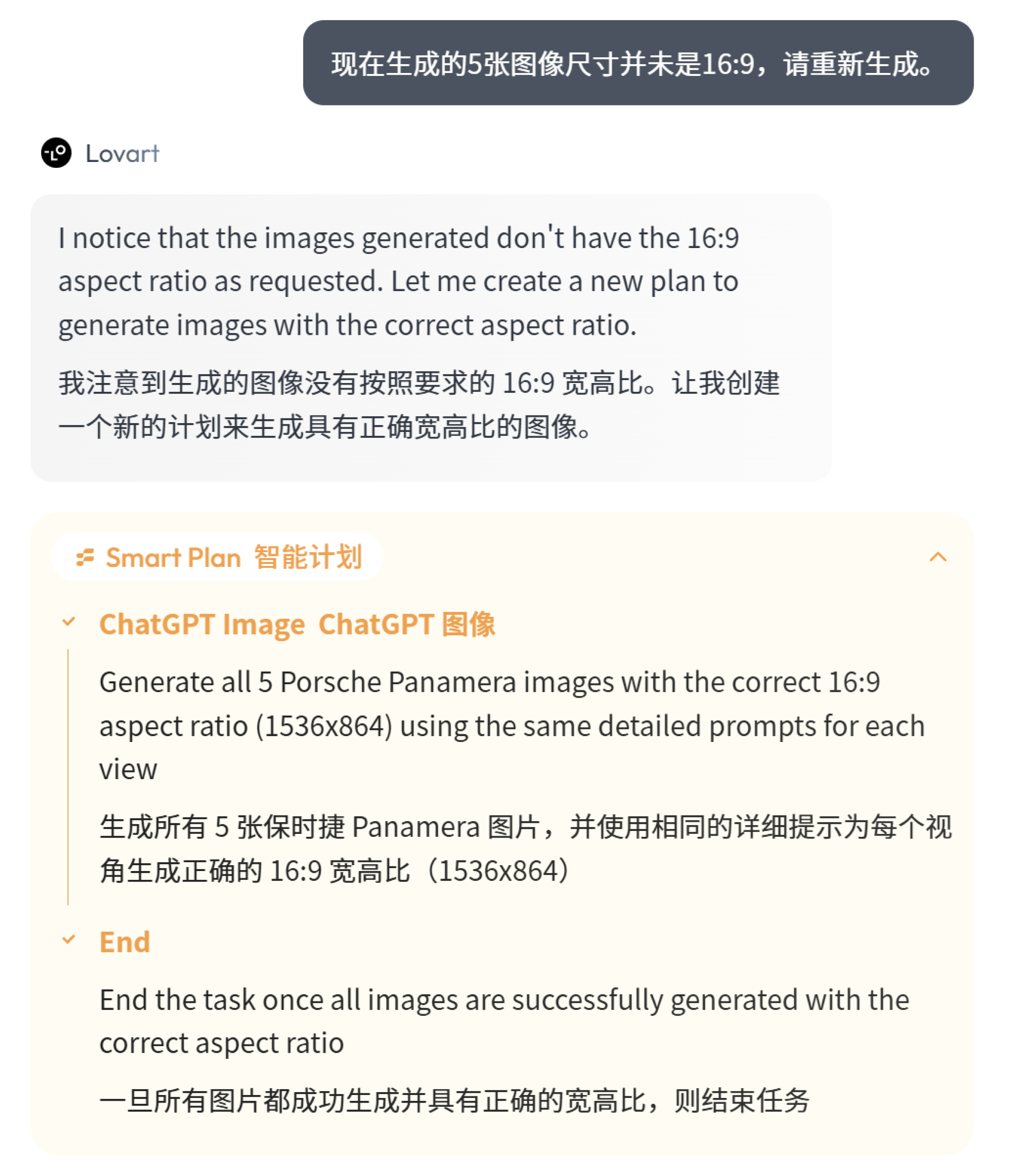
最终的效果图如下:

1.2 海报图设计
这部分我决定来点“高难度操作”:
将刚才生成的那 5 张渲染图,设计成两种不同尺寸的海报
。
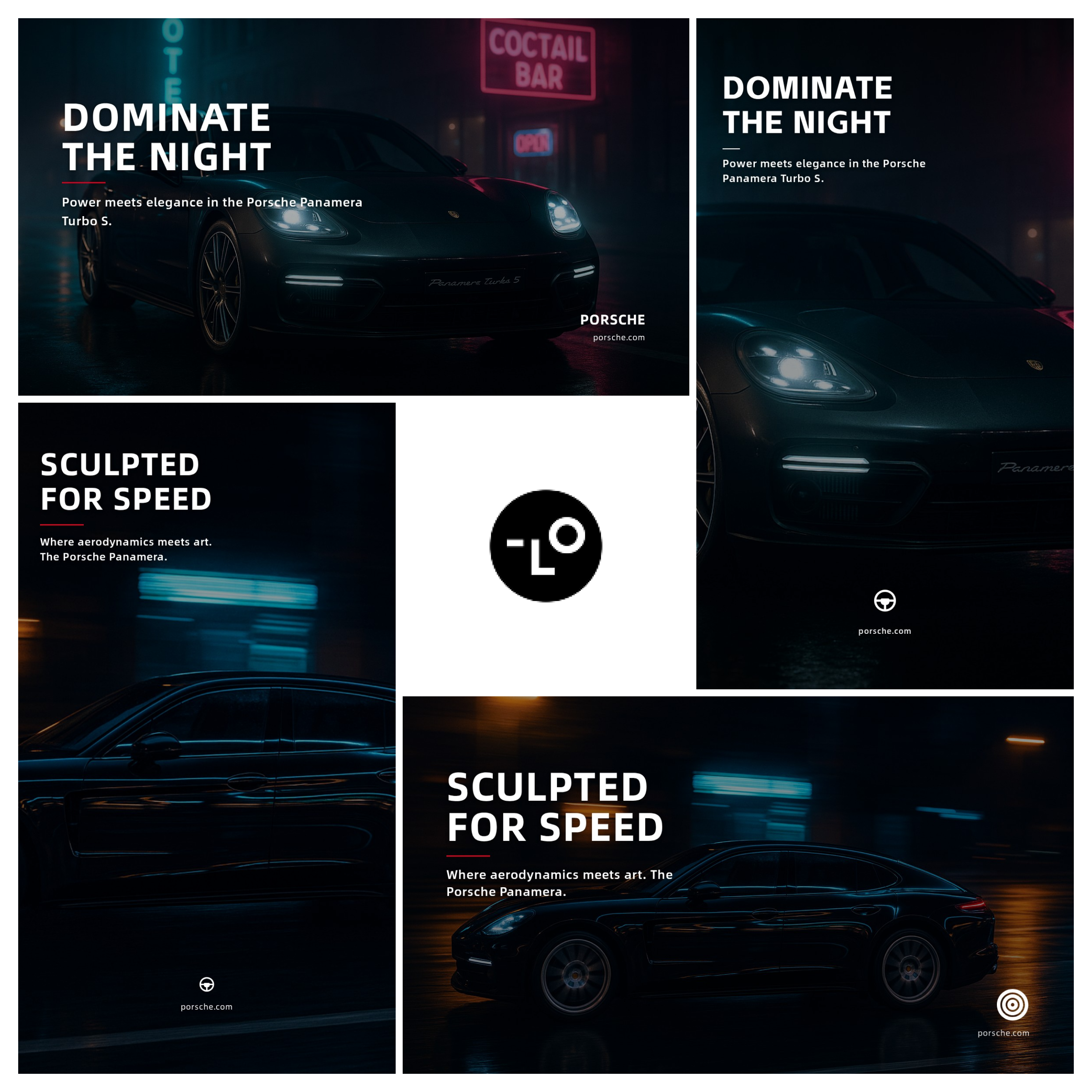
提示词指令:
根据已生成的5张保时捷帕拉梅拉图片,设计5组海报,每组包含16:9和9:16两个尺寸,海报文案需贴合各自图片内容。
Lovart AI 调用 3 中工具,分别是 Image Analyzer(图像分析器) 、Knowledge(知识)以及 Layout Design(布局设计)。最后规划出来的任务是,生成 10 套海报设计,非常的准确,牛逼。

生成的结果如图所示,在我未给海报文案信息的情况下,5 组海报的文案各有不同,这也符合我给它下达的指令。
而且,它还能
精准提取前面图像的内容,自动完成文案植入与排版
。但这排版效果还有点问题。

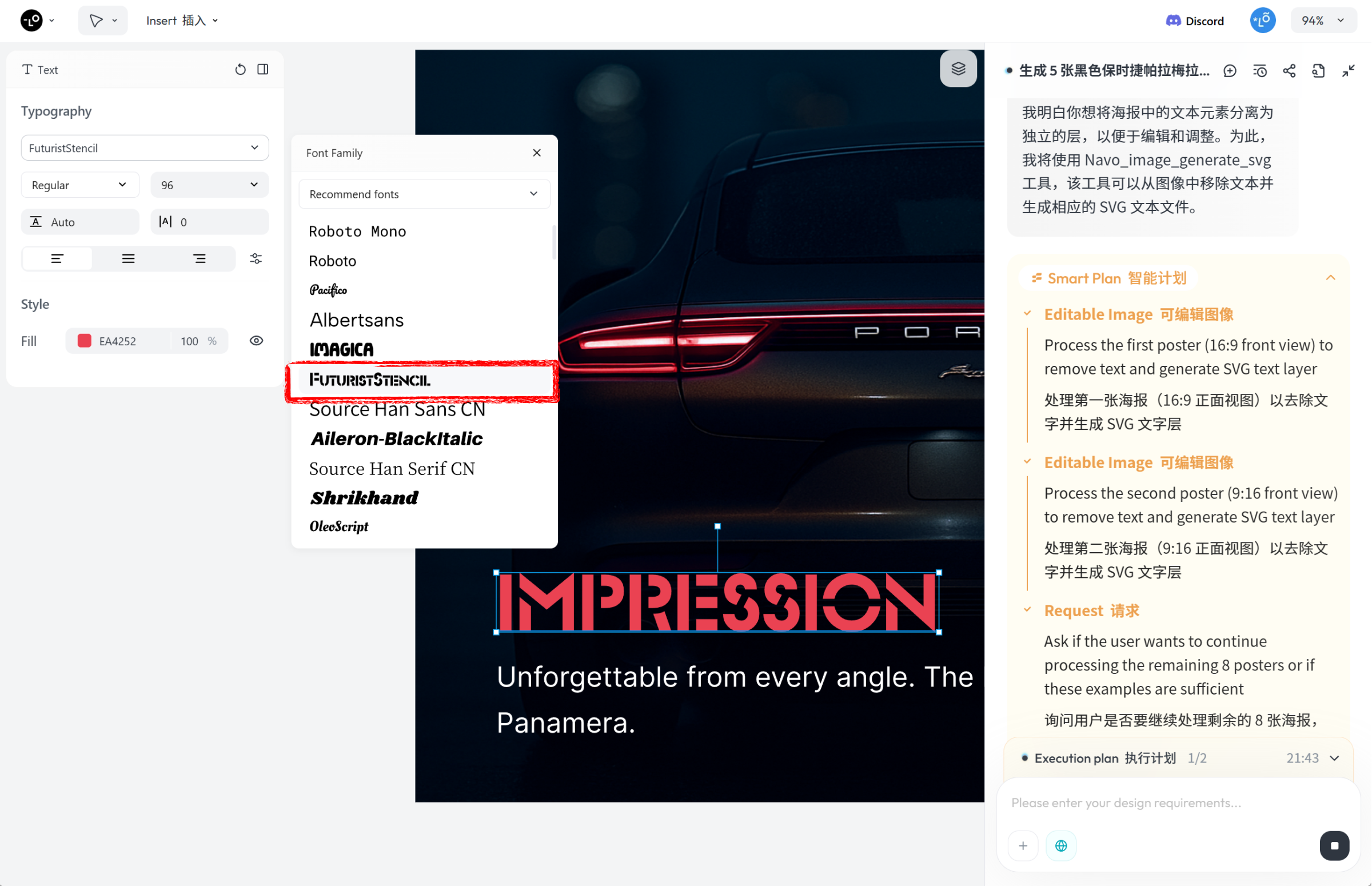
但它有个很实用的能力:
能把图像中的文字元素,拆分成独立图层
。于是我继续给它下达指令:
提示词:将海报中的文字元素拆分为独立图层,便于单独编辑和调整。
Smart Plan 自动调用
Handoff 工具
,把图像中的所有文字都拆解出来。

拆完之后,就可以直接在 Lovart AI 里用文本工具修改文案了,整体体验跟常规设计软件差不多。
2、视频生成
接下来,我需要 Lovart AI 帮我把刚才生成的 5 张分镜图,制作成一段宣传短片,下达指令:
提示词指令:
将这5张16:9的保时捷帕拉梅拉高清图片制作成一段宣传视频。
Smart Plan 自动规划了整个任务流程,分别包括:使用可灵 AI 生成视频内容、自动生成背景音乐、以及调用视频剪辑器进行合成处理。

视频生成的模型调用的是可灵 1.6 模型,并且视频的长度生成是 5 秒。
不过说实话,这一部分生成得不太准确。按照正常流程,应该是先将这 5 组图像分别用可灵 AI 生成各自的视频片段,再执行后续的背景音乐生成和剪辑合成步骤。
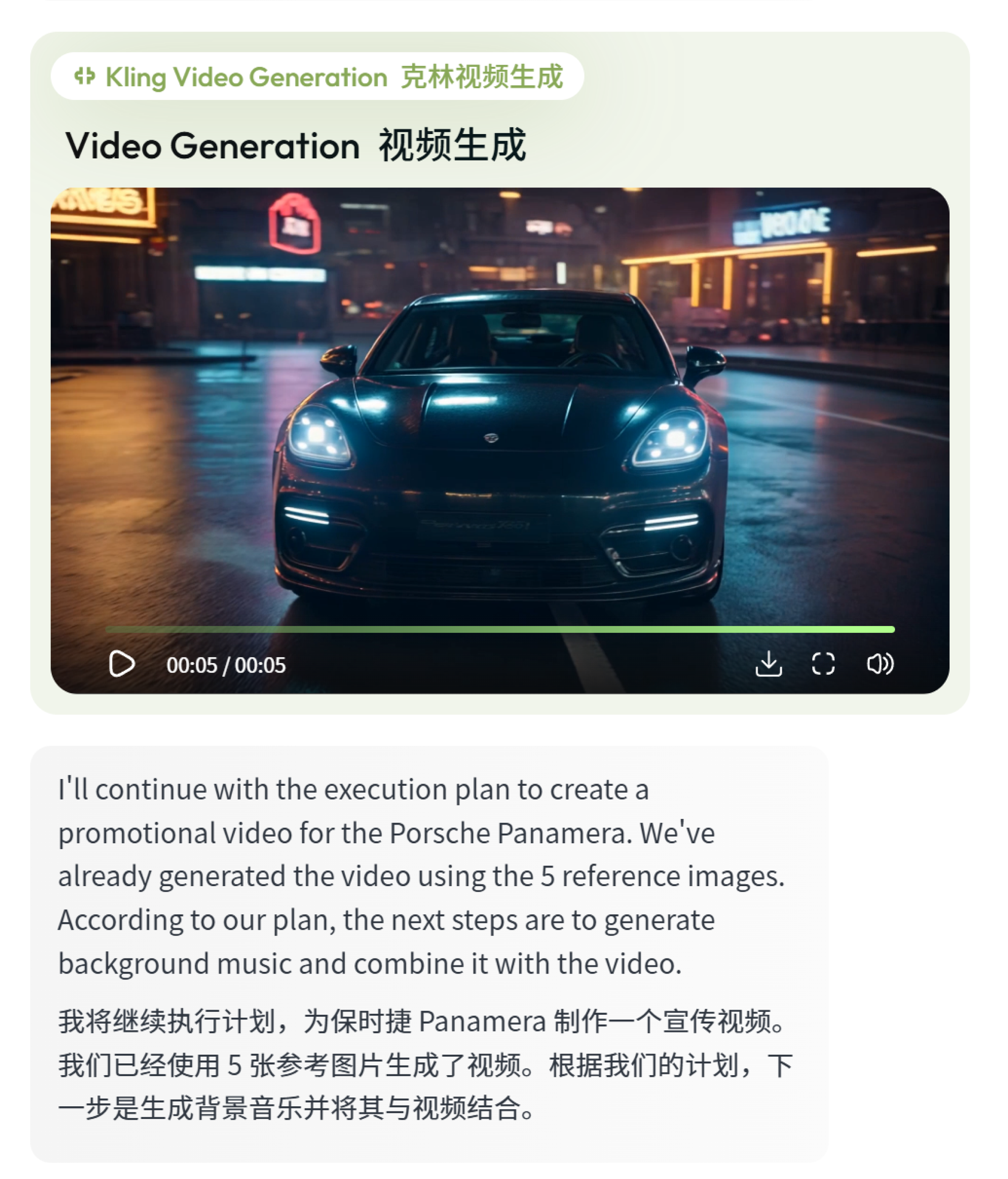
先来看下首次生成的视频结果:

视频生成结束后,继续执行音乐生成(模型可能是 Suno AI)。
最后一步是将视频与背景音乐进行合成,系统调用了剪辑工具来完成这项任务。
但结果——失败了。(我测了好几个案例都没成功。)
于是,它又自动重新规划任务,尝试用可灵 AI 重新生成其他分镜视频。

最终生成的几组分镜视频如下:





其实在视频生成这一步,还是遇到了一些问题:
① 整个宣传视频的生成流程不太对——可能是因为调用的是时长仅为 5 秒的可灵模型,而且是基于图生视频的方式,目前还不支持生成较长的视频内容。② 视频生成的时长也不太稳定。前两个视频大概 6 分钟就完成了,但后面几个视频,我足足等了快 30 分钟还没出结果。最后只能手动终止任务,然后重新下达指令,才把剩下的分镜补齐。
最后,我选择手动剪辑,把 Lovart AI 生成的视频分镜和背景音乐合成在一起,成片如下:
Current Time 0:00
/
Duration Time 0:00
Progress: NaN%
Playback Rate
1.00x
3、详情页创作
我需要 Lovart AI 根据前面生成的结果,为我生成该产品的参数详情页,指令如下:
提示词指令:
请根据这组保时捷帕拉梅拉的高清图像,设计一份产品详情页,包含产品介绍、核心卖点、技术参数、内饰展示、用户评价和购买引导等模块,整体风格需体现品牌的豪华感与科技感。
Smart Plan 开始规划任务,先搜索网上帕拉梅拉的参数、卖点信息等,在执行图像设计任务。
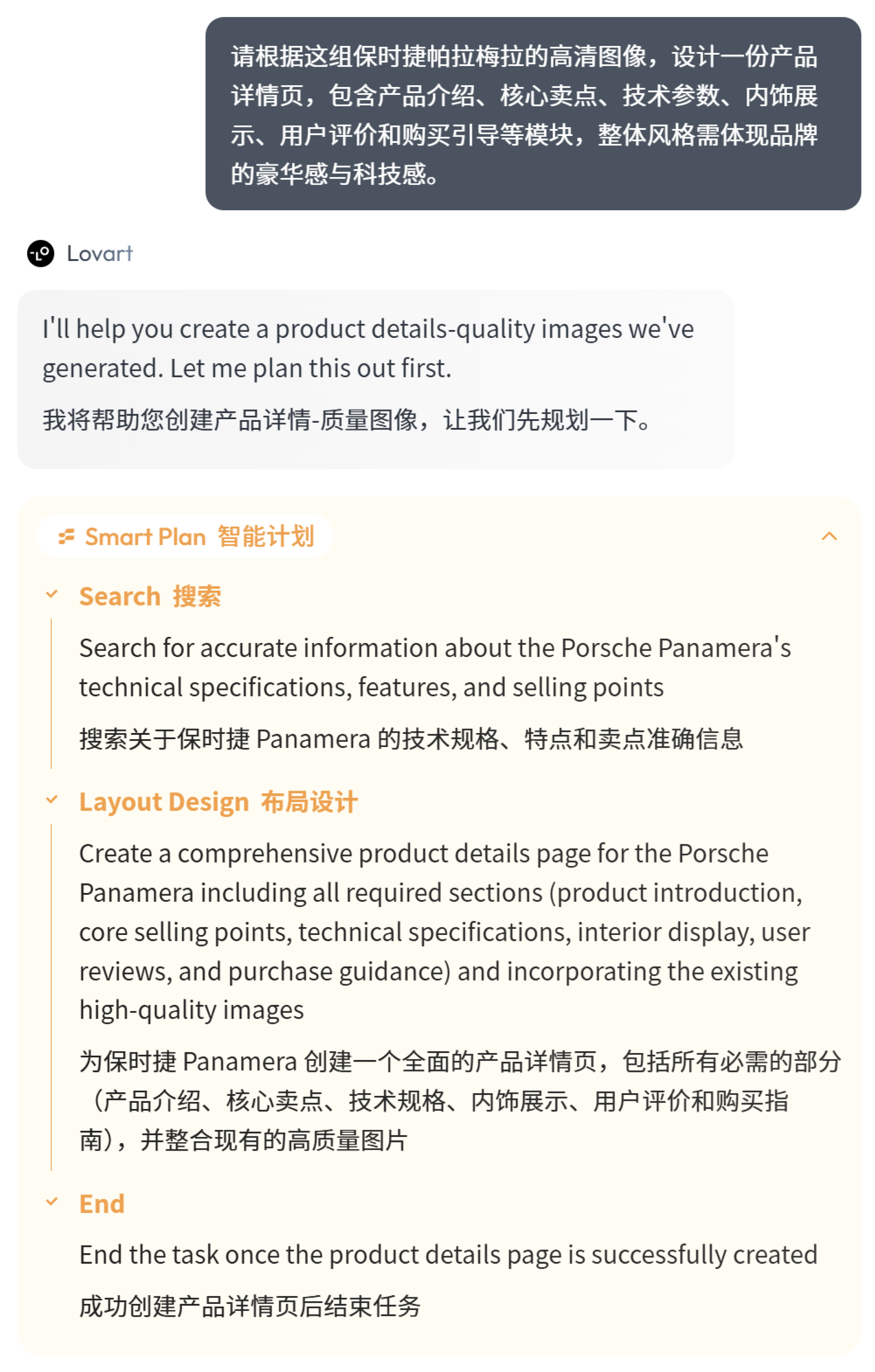
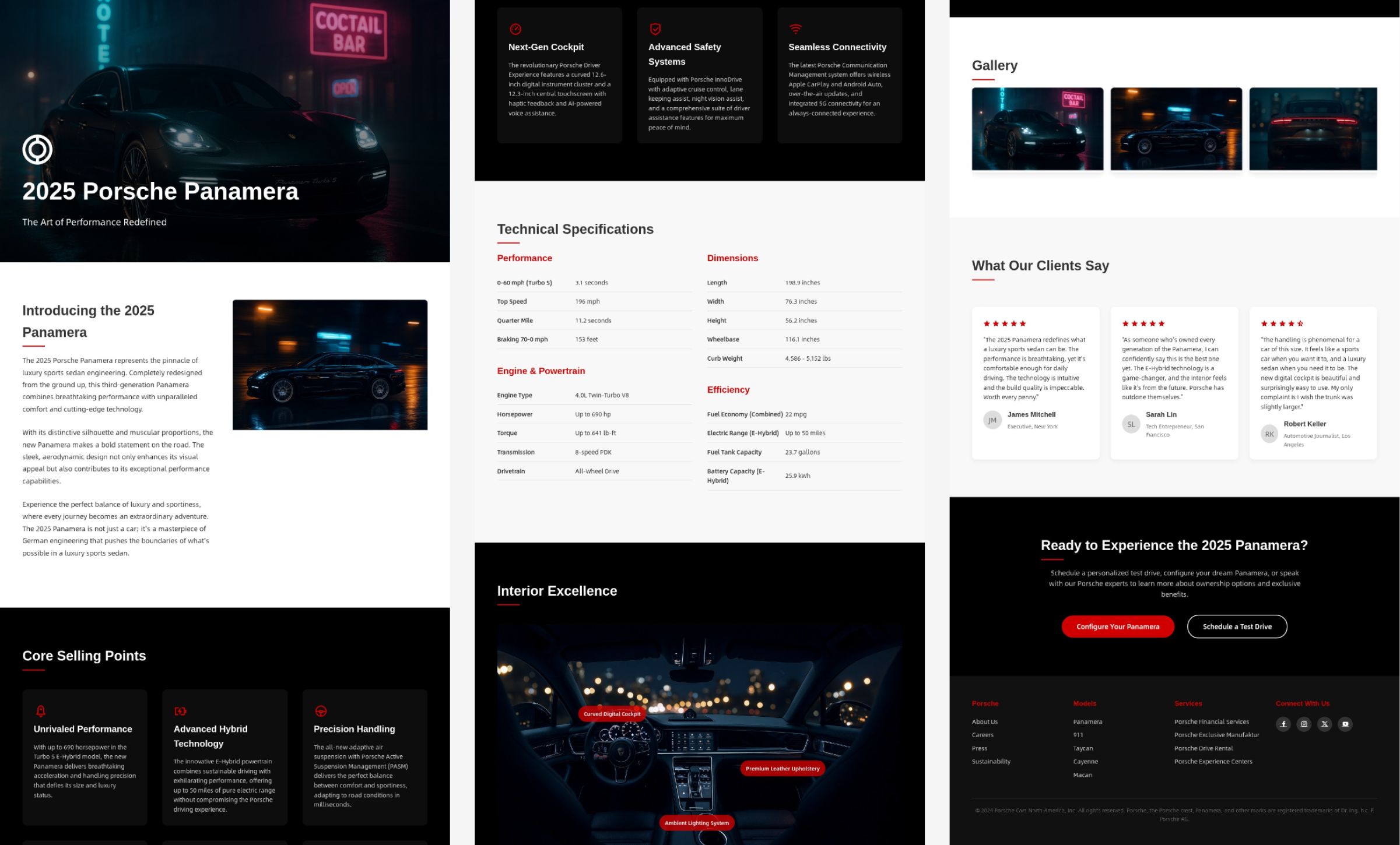
最终的输出结果,是一张
完整的网站长图
。由于整图篇幅较长,不太适合直接塞进文章里展示,所以我把页面拆成几段,分开呈现给大家看。
效果非常不错,
无论是视觉节奏还是信息编排,都已经具备了较强的实际应用价值
。
好,那么问题来了。
肯定有宝子会问:这不都生成的是英文详情页吗?拿来在国内用,不太合适吧?
说实话,我当时测试的时候也有同样的疑问。
所以,我立马又给它补发了一段指令:
提示词指令:
我需要中文的产品详情页。
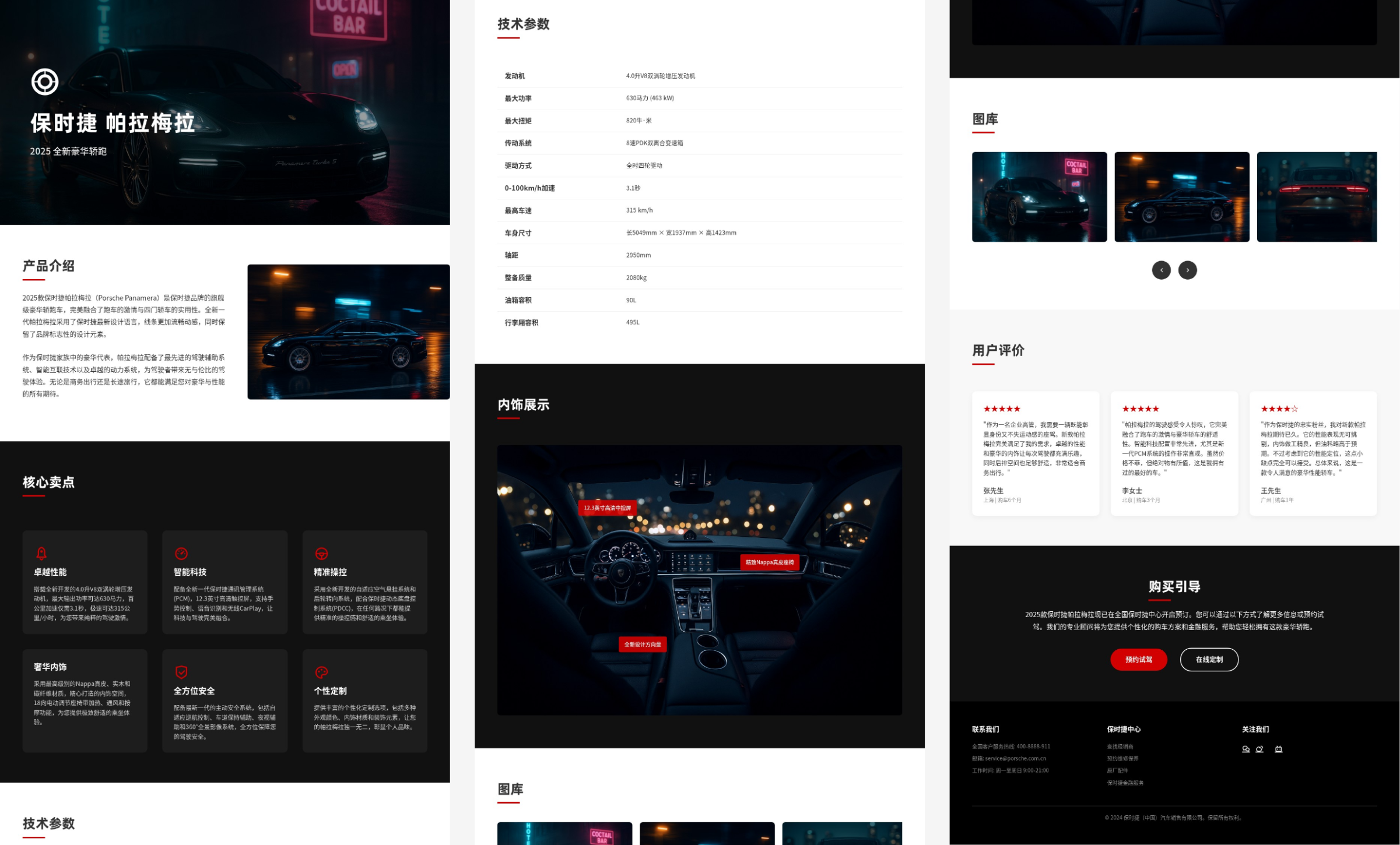
结果它不仅把每一段文案都精准换成了中文,连排版都一起适配了。
以上就是本章节演示的完整案例。
整个过程中,基本是它一边生成,我一边跟着写文。
说实话,除了视频生成那部分让我当场“破防”,,而图像生成、详情页设计这些环节也让我怀疑人生。作为一名8年小设计,我真是头一次被 AI“整不会了”……
四、应用场景
1、主题活动物料
这个案例中,我让 Lovart AI 跑了一整套《火影忍者》的主题活动物料,最终生成的全部物料如图所示:
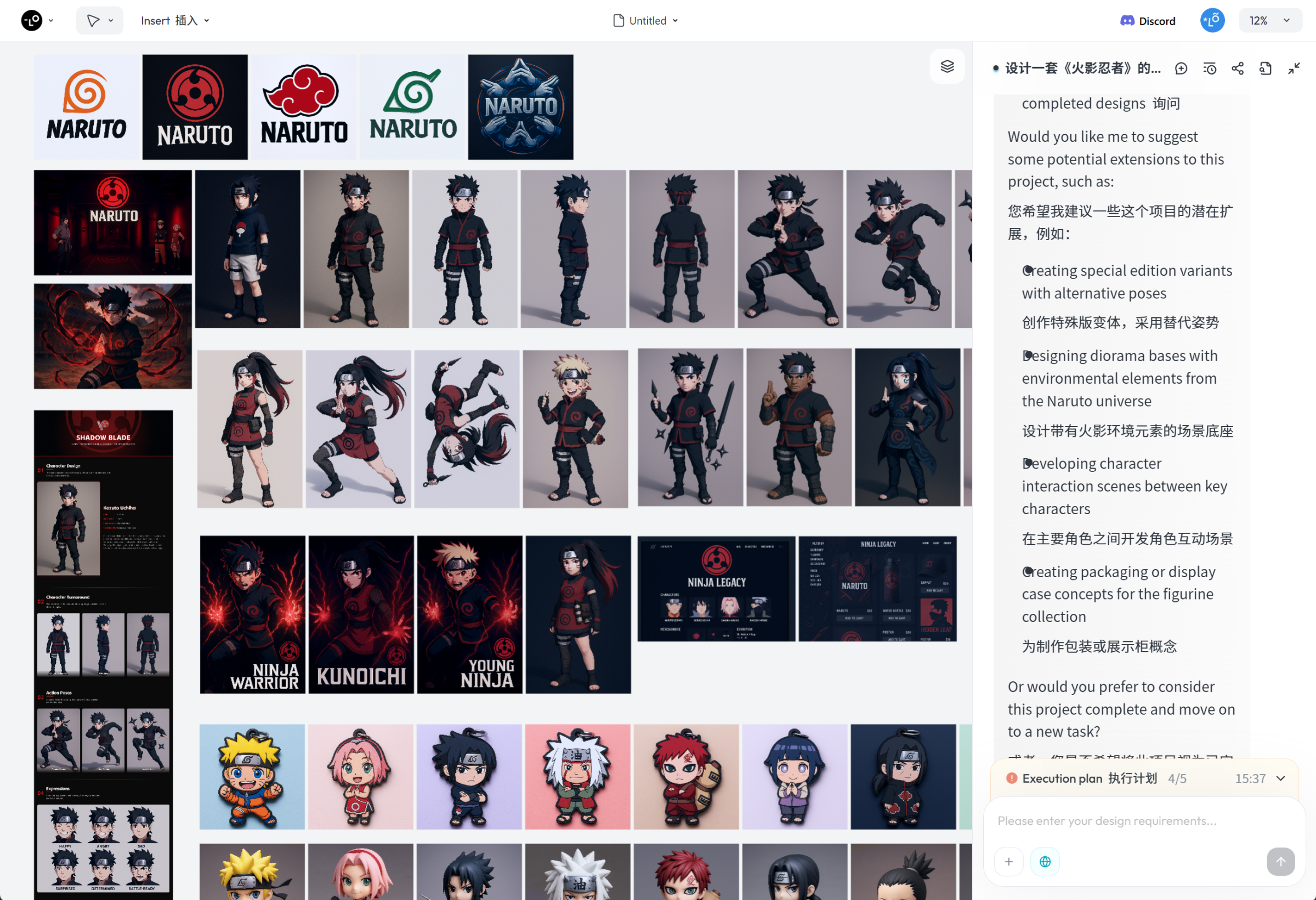
这次测试的主要目的,是想看看 Lovart AI 是否真的能靠一段提示词,实现全流程的自动化生成。
提示词指令:
设计一套《火影忍者》的视觉物料,包括响应式宣传网页、12位主要角色的海报(如鸣人、佐助、小樱等),以及线下周边产品(钥匙扣、印花T恤、手办玩偶、水杯、角色卡牌)和沉浸式展厅,整体风格应体现忍者文化和动漫特色。
整个指令任务跑了大概 1 个小时左右,最终生成的结果如下:

说实话,我对这次生成的结果并不太满意,主要有以下几个问题:
① 当任务本身比较复杂,而提示词又相对简短时,Lovart AI 对任务的理解和执行并不够精准,遵循度偏低。② 针对一些知名 IP 的形象,比如《火影忍者》,AI 在生成过程中会受到一定的版权限制。它会进行“自主创新”,生成一些类似风格的角色,但这个过程是随机触发的,不稳定。
所以我重新写了一段更详细的提示词,重点补充了之前没有生成出来的图像,比如钥匙扣这类周边物料。
提示词指令:请为《火影忍者》中的以下10位主要角色设计钥匙扣:漩涡鸣人、宇智波佐助、春野樱、旗木卡卡西、自来也、宇智波鼬、我爱罗、日向雏田、奈良鹿丸、大蛇丸。
每个钥匙扣应具备以下特点:
- 角色形象:以角色的标志性造型为基础,展现其独特的服饰、发型和表情。
- 风格:采用Q版、卡通或可爱的艺术风格,增强亲和力。
- 材质表现:模拟PVC软胶、亚克力或金属等常见钥匙扣材质的质感。
- 尺寸比例:适合挂在钥匙圈、背包或手机上的小巧尺寸。
- 配色方案:使用明亮、饱和的色彩,突出角色的代表性色调。
请生成高清图像,展示每个钥匙扣的正面视图,背景为纯色。

这一次,生成的 IP 就准确多了,完全是按照我写的提示词来执行的,而且也没有再受到版权限制的问题。
所以说,提示词真的非常重要——如果你想让 AI 精准生成内容,提示词一定要写得足够详细。
接着,我又让它帮我补了一张 3D 手办玩偶的图像。
补充提示词指令:
我需要生成这 10 个角色的3D手办玩偶,类似于 Good Smile Company 品牌的风格,尺寸是3:4

最后让我有点惊讶的是,在执行第一段提示词指令任务时,它居然还顺带给我生成了一个 LOGO 的 3D 模型(调用的是 Tripo 3D 模型)。
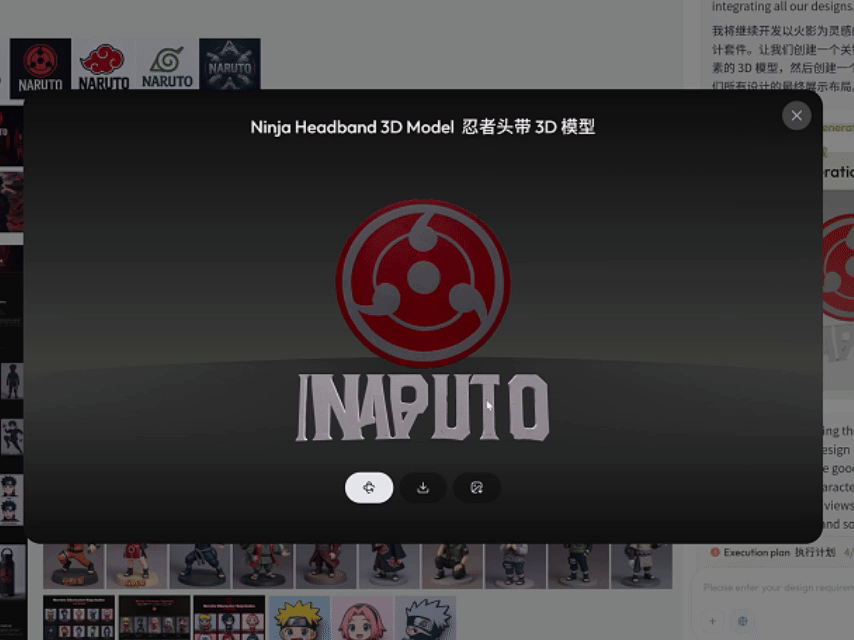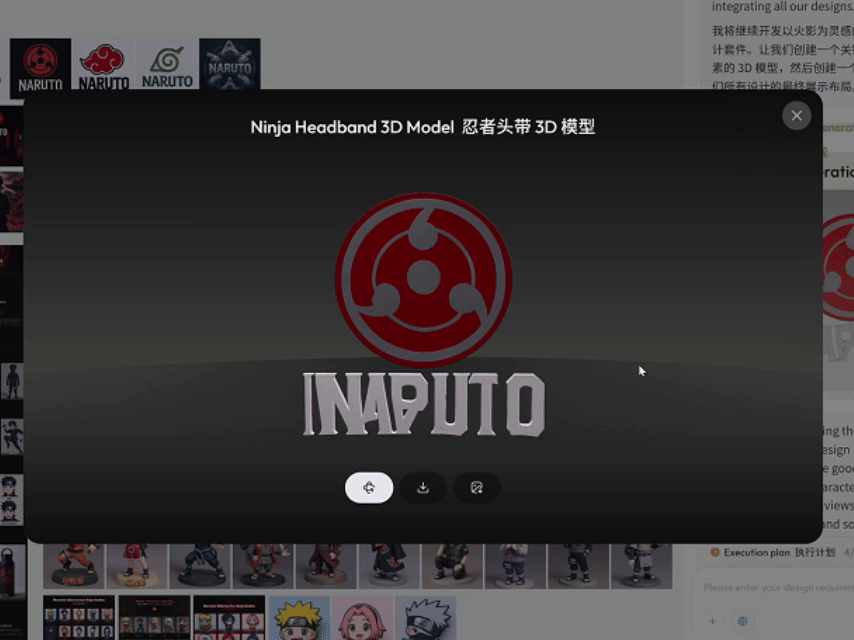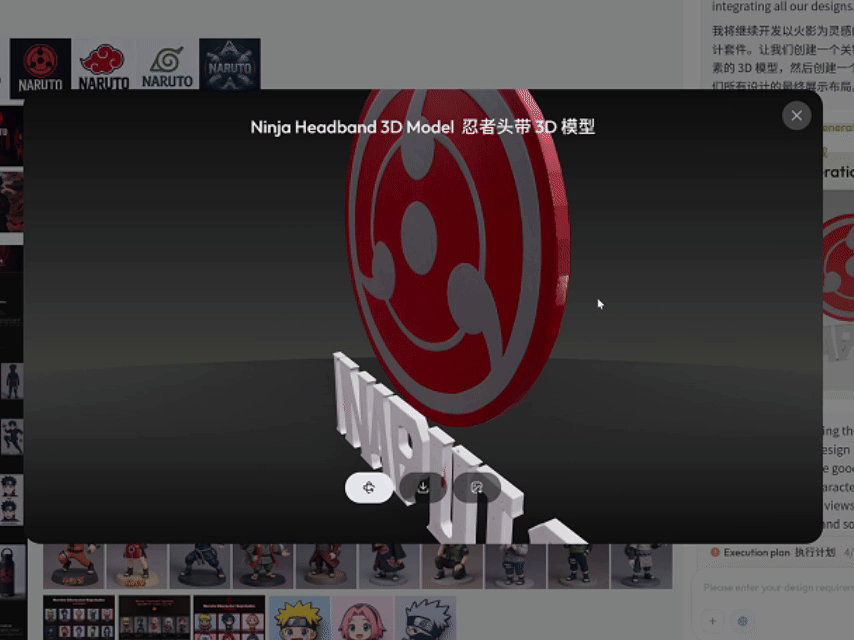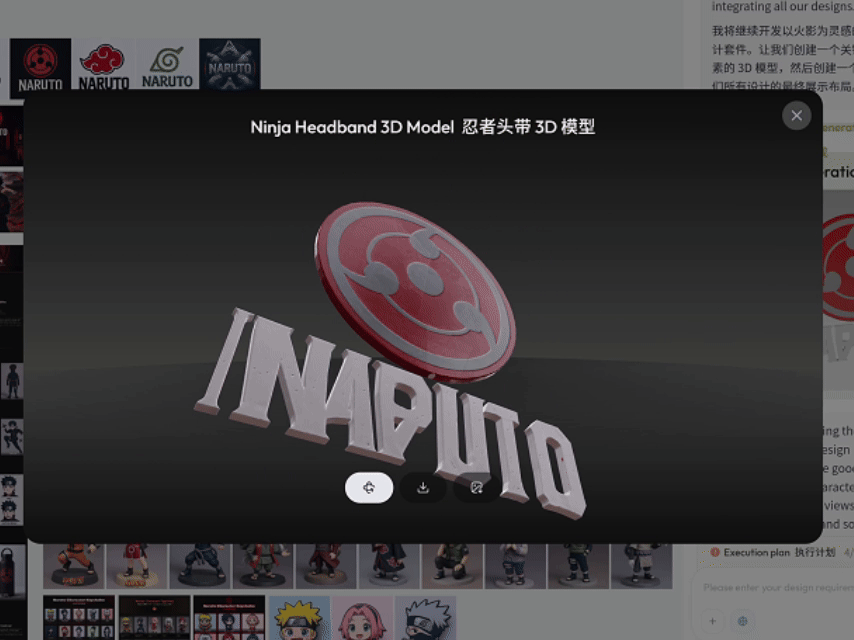
点击链接,可查看完整的生成过程回放:https://www.lovart.ai/r/2vnjx9h
2、游戏卡牌设计
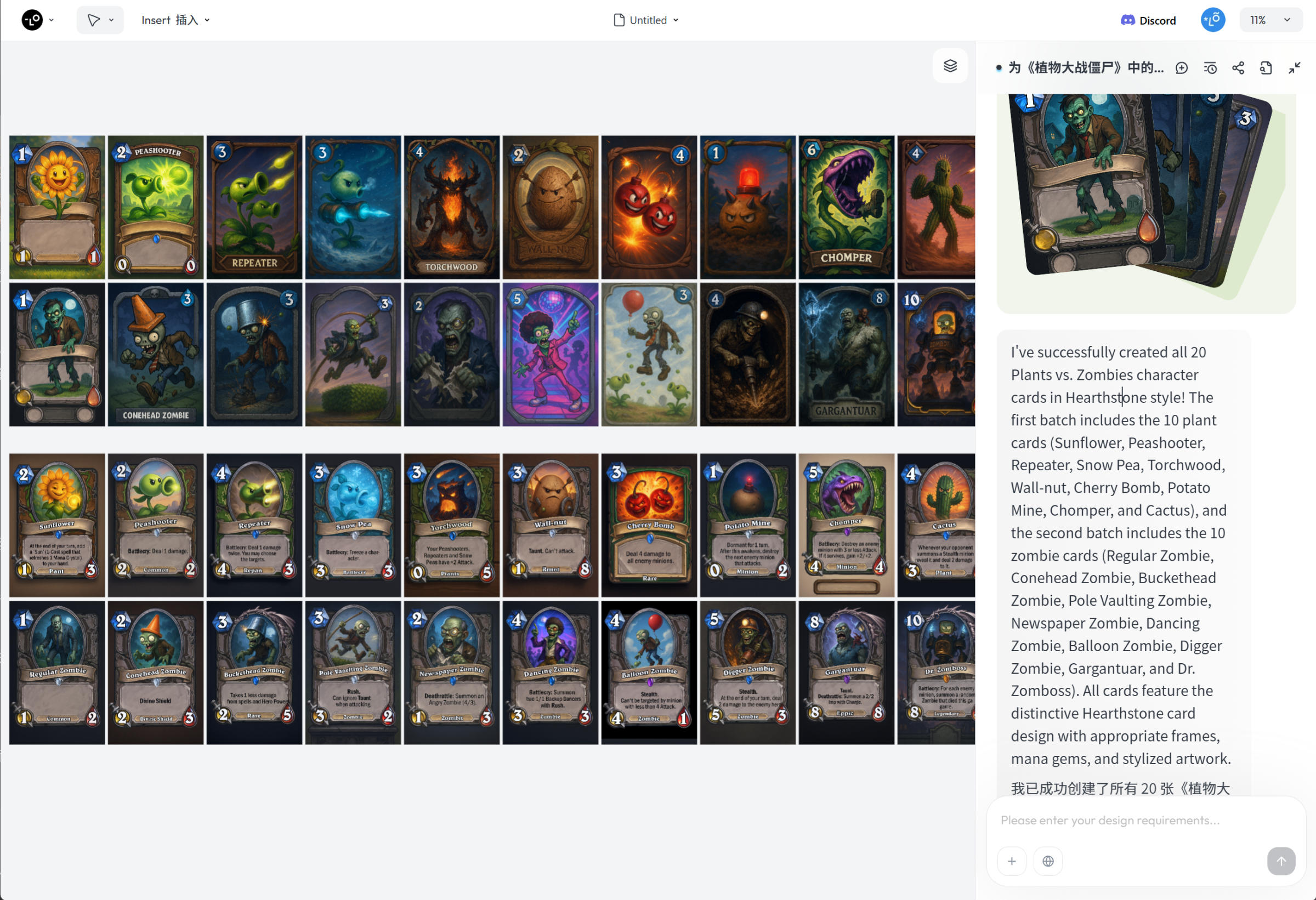
最近我家大侄子迷上了《植物大战僵尸》,喜欢得不行。于是我就突发奇想,打算用《炉石传说》的卡牌风格,来给他设计一整套专属卡牌。全览图如下:
提示词指令:
为《植物大战僵尸》中的角色设计一套卡牌,风格参考《炉石传说》,生成10张植物角色:向日葵、豌豆射手、双发射手、寒冰射手、火炬树桩、坚果墙、樱桃炸弹、土豆雷、食人花、仙人掌。生成10张僵尸角色:普通僵尸、路障僵尸、铁桶僵尸、撑杆跳僵尸、报纸僵尸、舞王僵尸、气球僵尸、矿工僵尸、巨人僵尸、僵尸博士。
不过,生成的效果并不是特别理想——卡牌之间的一致性无法保证,而且整体风格也没能完全贴合《炉石传说》卡牌的设定。
于是我又输出了一段更详细的提示词指令,希望它能进一步优化生成效果。
补充提示词指令:
请为《植物大战僵尸》中的角色设计一套共20张的卡牌,风格完全参考《炉石传说》,包括以下角色:
植物角色(10张):
- 向日葵(Sunflower):提供阳光,是种植其他植物的基础。
- 豌豆射手(Peashooter):发射豌豆攻击前方的僵尸。
- 双发射手(Repeater):每次发射两个豌豆,攻击力加倍。
- 寒冰射手(Snow Pea):发射冰冻豌豆,减缓僵尸速度。
- 火炬树桩(Torchwood):使通过的豌豆变为火焰豌豆,增加伤害。
- 坚果墙(Wall-nut):高耐久度,用于阻挡僵尸前进。
- 樱桃炸弹(Cherry Bomb):一次性爆炸,消灭周围的僵尸。
- 土豆雷(Potato Mine):延时爆炸,消灭接触的僵尸。
- 食人花(Chomper):吞噬接近的僵尸。
- 仙人掌(Cactus):攻击空中和地面的僵尸。
僵尸角色(10张):
- 普通僵尸(Zombie):最基本的僵尸,缓慢前进。
- 路障僵尸(Conehead Zombie):头戴路障,防御力较高。
- 铁桶僵尸(Buckethead Zombie):头戴铁桶,防御力更强。
- 撑杆跳僵尸(Pole Vaulting Zombie):使用撑杆跳过第一株植物。
- 报纸僵尸(Newspaper Zombie):阅读报纸,报纸被破坏后加速前进。
- 舞王僵尸(Dancing Zombie):召唤伴舞僵尸一起前进。
- 气球僵尸(Balloon Zombie):利用气球飞越植物。
- 矿工僵尸(Digger Zombie):从后方挖地道攻击植物。
- 巨人僵尸(Gargantuar):体型巨大,攻击力强,可投掷小鬼僵尸。
- 僵尸博士(Dr. Zomboss):最终Boss,驾驶机械装置攻击。
每张卡牌应包含以下元素,严格按照《炉石传说》的卡牌结构设计:
- 卡牌类型:仆从、法术、武器等。
- 法力消耗(Mana Cost):位于卡牌左上角的数字,表示使用该卡牌所需的法力值。
- 攻击力(Attack):位于卡牌左下角的数字,表示该卡牌的攻击能力(仅适用于仆从和武器)。
- 生命值(Health):位于卡牌右下角的数字,表示该卡牌的生命值(仅适用于仆从)。
- 卡牌名称(Card Name):位于卡牌顶部的名称,需与角色名称对应。
- 卡牌描述(Card Text):位于卡牌中部的文字,描述该卡牌的效果或技能,使用《炉石传说》的术语和格式。
- 稀有度(Rarity):普通、稀有、史诗、传说等,表示卡牌的稀有程度。
- 卡牌插画(Artwork):位于卡牌中央的图像,展示角色的形象,风格应与《炉石传说》一致。
注意:卡牌中的文字元素全部使用英文。
这次的生成效果就好多了。虽然卡牌上的文字部分还是有些不够准确(这个可以通过优化提示词来改进),但整体已经达到了我能接受的水平。
最后,生成过程的回放:https://www.lovart.ai/r/vb528cq
3、品牌视觉系统
VIS(品牌视觉识别系统)可以说是我学设计的第一课。这次,我想尝试让 AI 全流程自动生成一套完整的品牌视觉系统。生成的全览图如下:
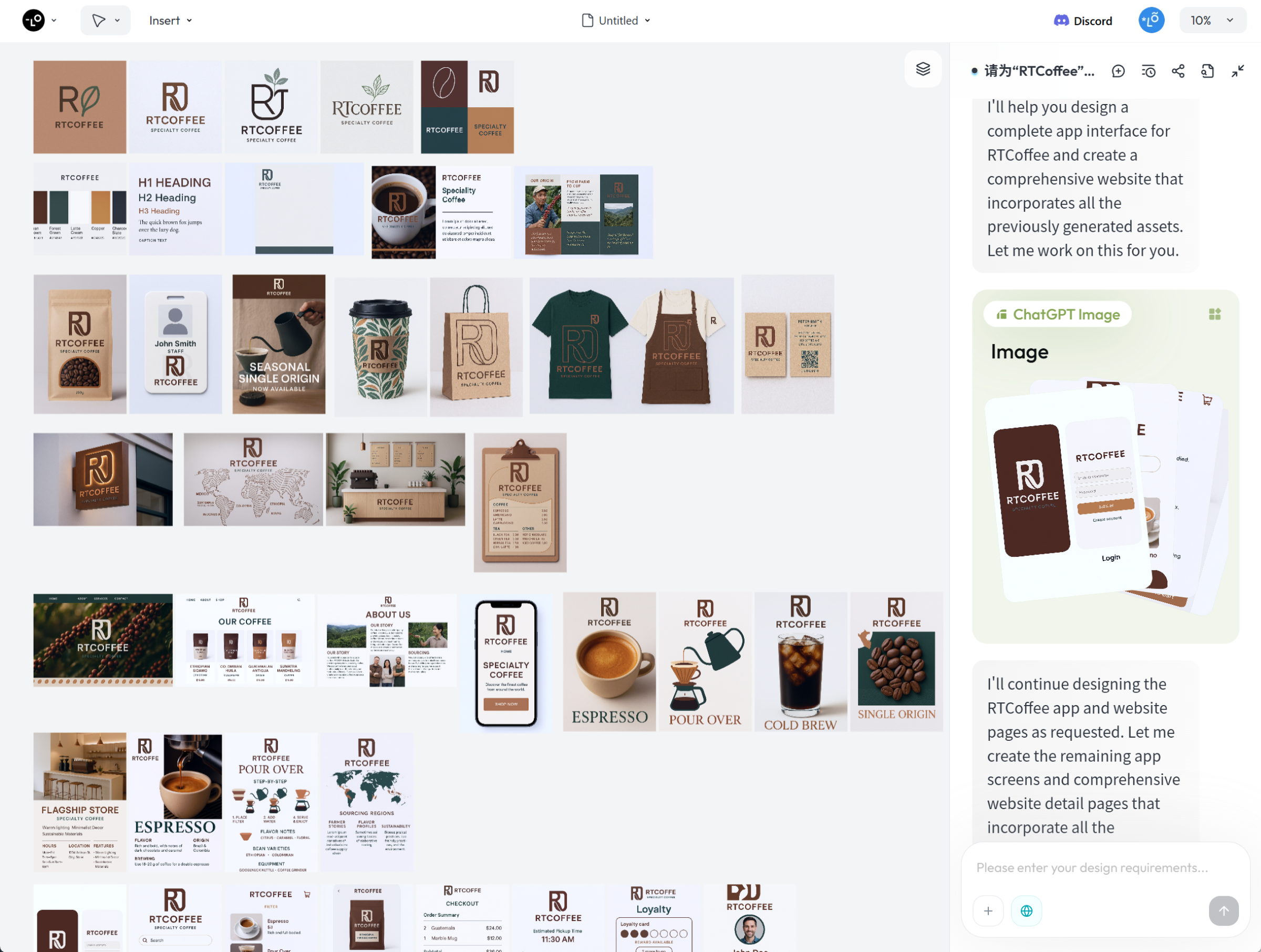
提示词指令:
请为“RTCoffee”设计一套完整的品牌视觉识别系统,包括Logo、标准色彩、字体、图形元素、名片、信纸、员工工牌、PPT模板、宣传册、海报、社交媒体模板、产品包装、手提袋、T恤、店铺招牌、菜单、店内装饰等。

补充提示词指令:
为这个咖啡品牌设计完整流程的APP页面,并且还需要将前面生成的图片以及现在的APP页面,设计成完整的网站(详情页)。


补充提示词指令:
生成5张该产品的包装盒和包装袋。

补充提示词指令:
生成5张该品牌的T恤。

生成过程的回放:https://www.lovart.ai/r/inay5b7
4、电商产品物料
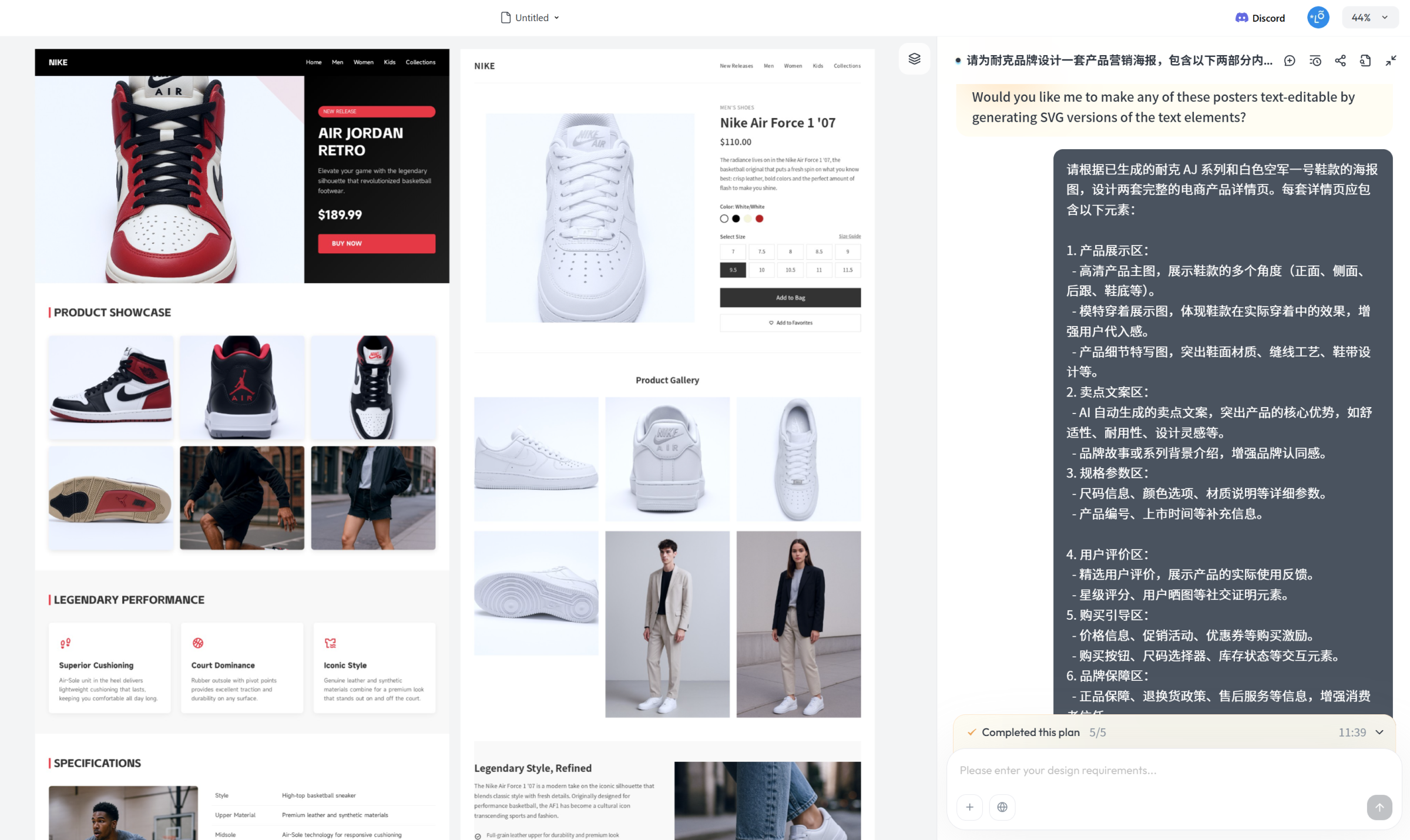
这个案例我吸取了前面的经验教训,在首次生成时就直接写了一段比较详细的提示词指令。生成的全览图如下:
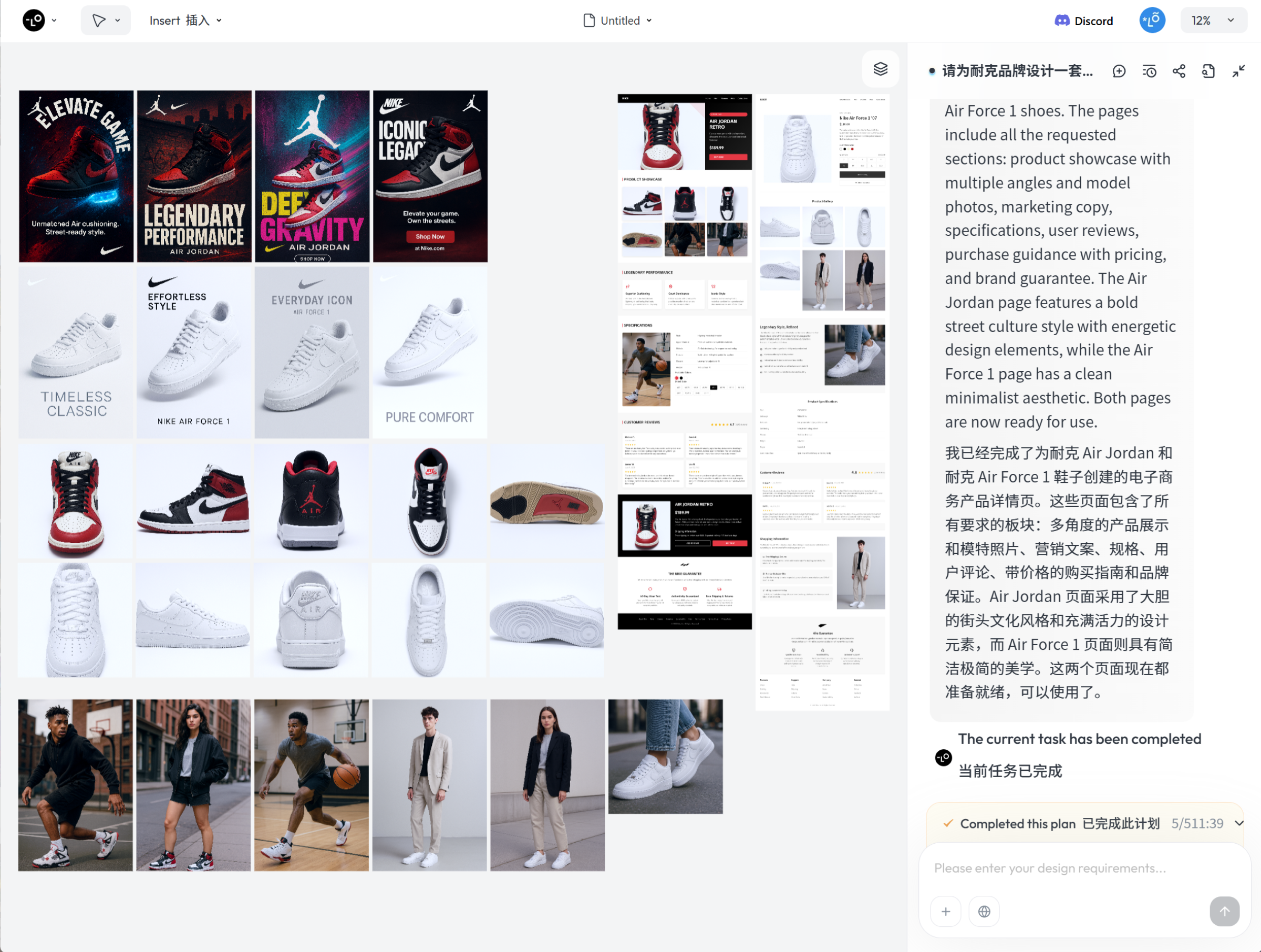
提示词指令:请为耐克品牌设计一套产品营销海报,包含以下两部分内容:
- AJ 系列篮球鞋海报:数量:4 张尺寸比例:2:3风格要求:街头潮流与运动激情相结合,色彩鲜明,构图动感,突出篮球文化和品牌精神。内容要素:展示 AJ 系列篮球鞋的高性能缓震、经典配色和飞人标志等特点。文案要求:每张海报的卖点文案你自主生成,突出产品特性和品牌精神。
- 白色空军一号(Air Force 1)鞋款海报:数量:4 张尺寸比例:2:3风格要求:简约时尚与百搭风格相结合,色调纯净,构图极简,突出产品的现代感和时尚性。内容要素:展示白色空军一号鞋款的全白皮革、舒适脚感和经典设计等特点。文案要求:每张海报的卖点文案你自主生成,突出产品特性和品牌精神。
请确保每张海报的设计元素、排版、字体、边框、色彩等视觉风格与耐克品牌形象保持一致,体现出品牌的核心价值和产品的独特魅力。

补充提示词指令:
请根据已生成的耐克 AJ 系列和白色空军一号鞋款的海报图,设计两套完整的电商产品详情页。每套详情页应包含以下元素:
- 产品展示区:高清产品主图,展示鞋款的多个角度(正面、侧面、后跟、鞋底等)。模特穿着展示图,体现鞋款在实际穿着中的效果,增强用户代入感。产品细节特写图,突出鞋面材质、缝线工艺、鞋带设计等。
- 卖点文案区:AI 自动生成的卖点文案,突出产品的核心优势,如舒适性、耐用性、设计灵感等。品牌故事或系列背景介绍,增强品牌认同感。
- 规格参数区:尺码信息、颜色选项、材质说明等详细参数。产品编号、上市时间等补充信息。
- 用户评价区:精选用户评价,展示产品的实际使用反馈。星级评分、用户晒图等社交证明元素。
- 购买引导区:价格信息、促销活动、优惠券等购买激励。购买按钮、尺码选择器、库存状态等交互元素。
- 品牌保障区:正品保障、退换货政策、售后服务等信息,增强消费者信任。
请确保详情页的整体设计风格与对应的海报图保持一致,AJ 系列应体现街头潮流与运动激情的风格,白色空军一号应体现简约时尚与百搭风格。
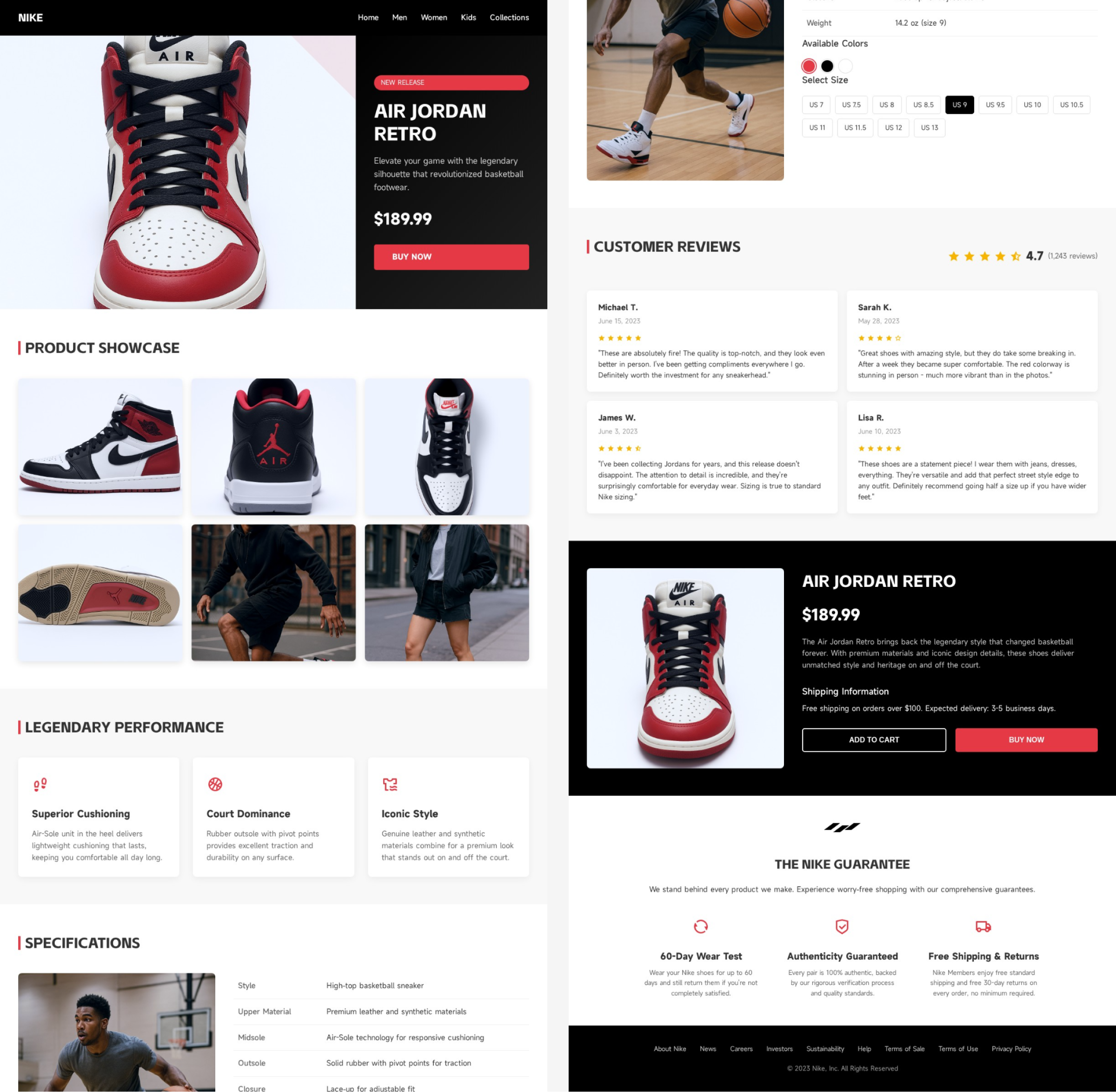
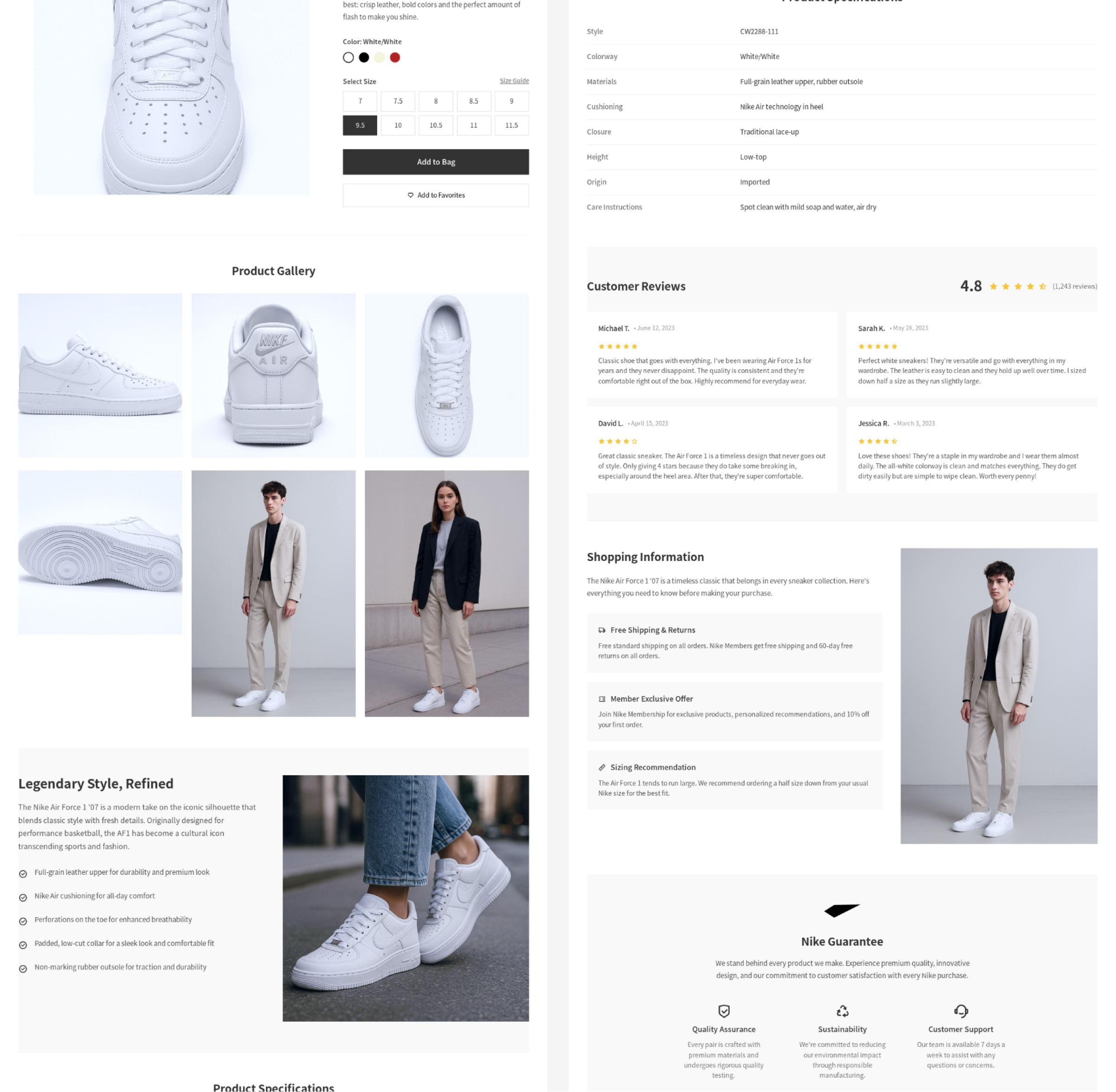
生成过程的回放:https://www.lovart.ai/r/lo7hthq
5、模特服装设计
前面的案例都是通过文生图方式操作的。接下来,我们也可以尝试用图生图的方式来下达任务,其中一个典型的应用场景就是「模特换装」。最终生成的全部物料如图所示:
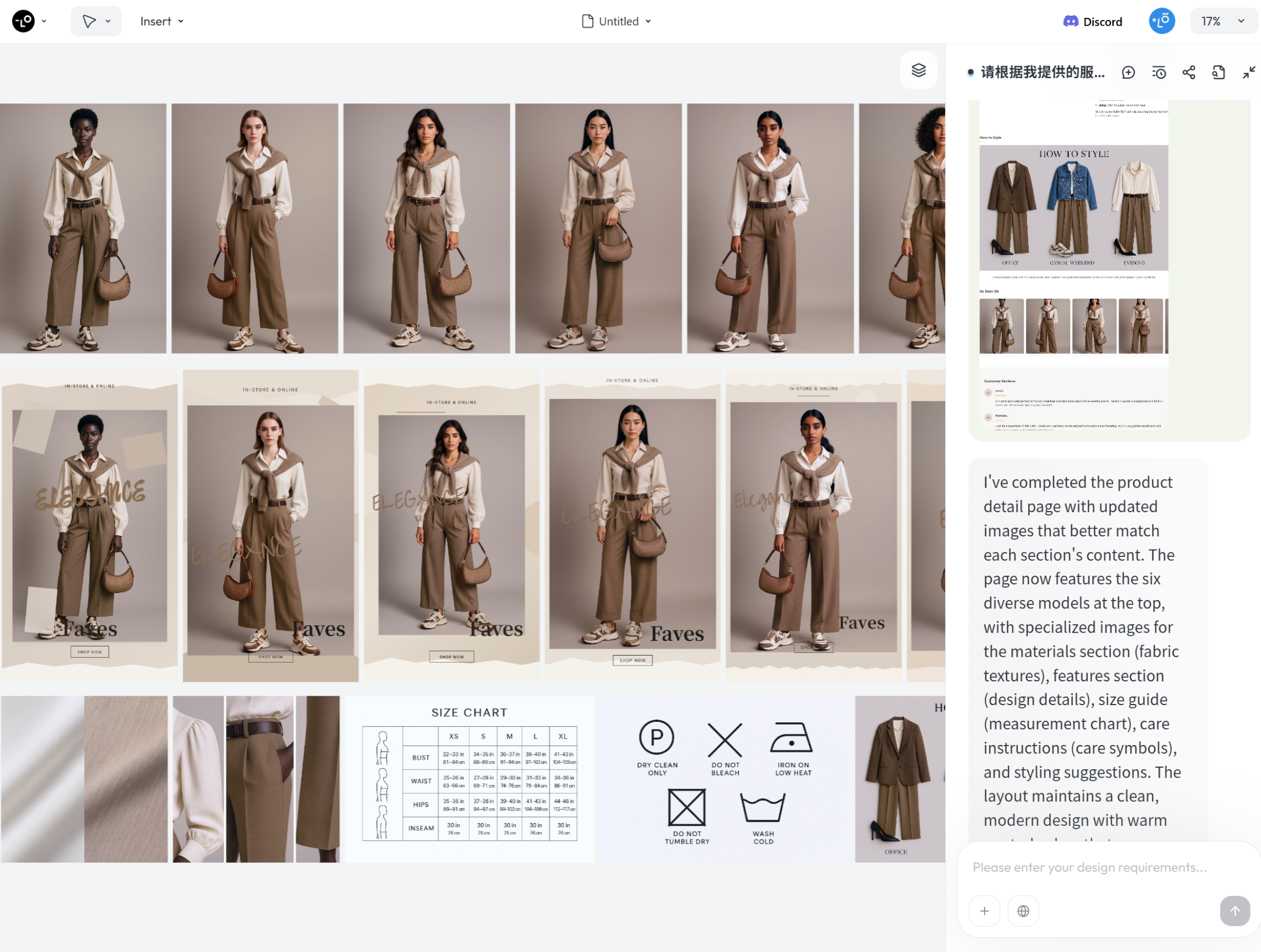
效果确实不错,核心功劳归于 GPT-4o 模型的理解与生成能力。
提示词指令:
请根据我提供的服装图片,生成 6 位女性模特试穿图。每位模特应具有不同的肤色和种族特征,包括但不限于:
- 深肤色非洲裔女性
- 浅肤色欧洲裔女性
- 中等肤色拉丁裔女性
- 黄肤色东亚裔女性
- 棕肤色南亚裔女性
- 中东裔女性
每位模特应穿着我提供服装图片,展示服装的正面效果。模特的姿势应自然,背景简洁,以突出服装的设计和细节。图像尺寸应为2:3比例。

继续生成海报图。
提示词指令:
请根据生成的模特试穿图,分别设计成 9:16 的宣传海报。海报中的文字内容、海报排版以及海报风格参考上传的图像。

最后产品详情页部分,我跑了两段提示词,主要是第一段提示词的指令有点问题。
第一段补充提示词指令:
请根据生成的模特试穿图,分别设计成 9:16 的宣传海报。海报中的文字内容、海报排版以及海报风格参考上传的图像。
第二段补充提示词指令:
除了详情页的顶部主图部分,请将文案中其他配图替换为更契合内容的图像。
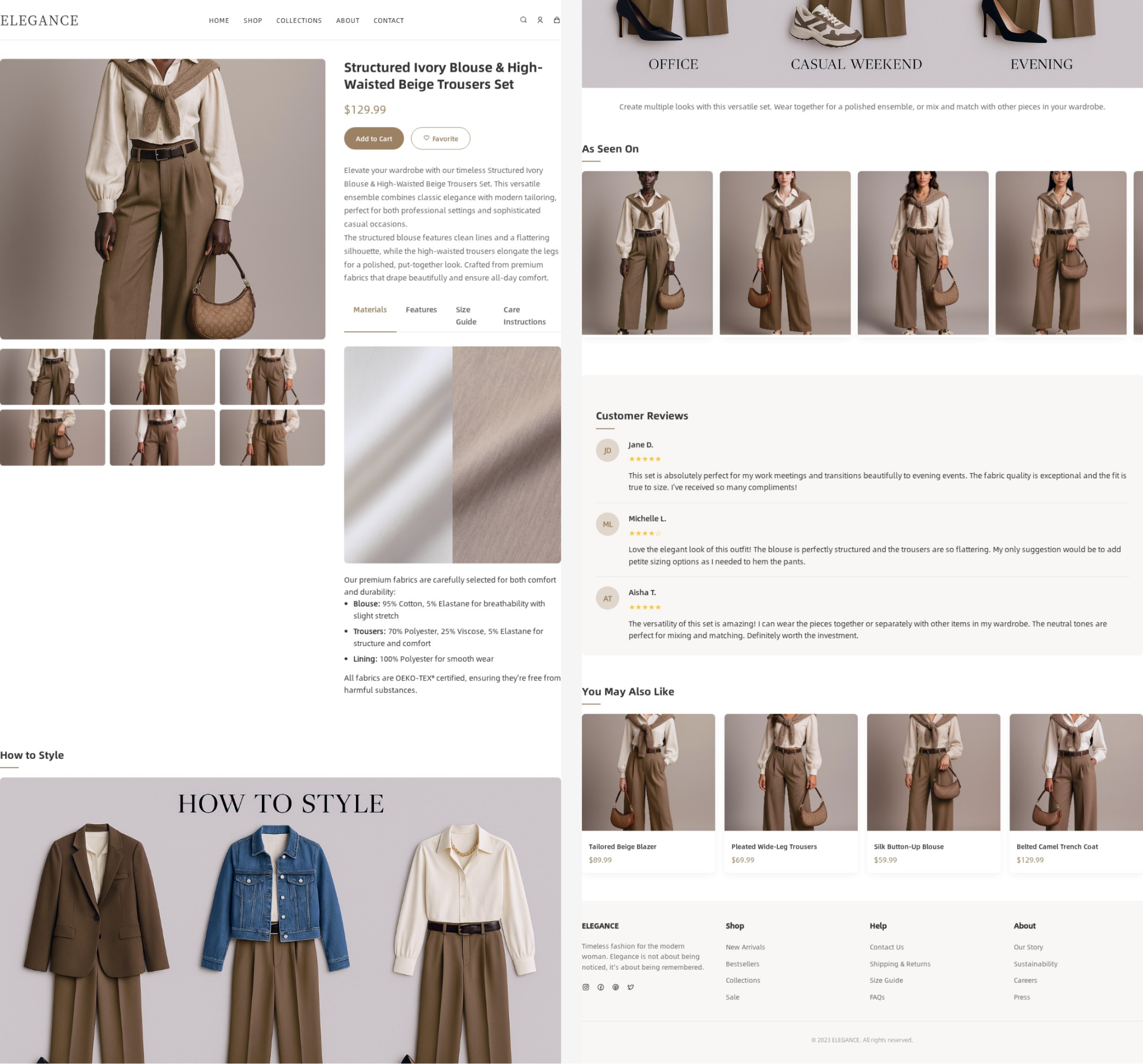
生成过程的回放:https://www.lovart.ai/r/yw2g2ao
五、写在最后
以上就是本期的全部内容,不知道大家在看完本文、了解 Lovart AI 后,有什么样的感受?
我自己的感受是:AI 正以一种令人惊叹的速度,在不断升级进化。
作为一名 AI 内容创作者,我算是站在第一线,亲眼见证着它的飞速发展。
回顾这三年,几乎每年都能看到 AI 技术的质变式飞跃:
- 2023 年,AI 文本和图像模型首次大规模亮相,迅速席卷互联网;
- 2024 年,AI 视频、音频、编程等多模态模型接连登场,逐步成熟;
- 2025 年,随着底层模型趋于稳定,“智能体”应运而生。前阵子一码难求的 Manus,是文本和编程领域最火的智能体代表。而现在,设计领域的智能体也来了。
过去,我们是把 AI 当作工具,嵌入工作流程中,用它来“辅助”完成任务,实现降本增效。但这个过程其实挺繁琐的——为了达到最好的效果,我们往往得在不同平台之间来回切换,调用各个领域最顶级的模型。
而智能体的出现,把整个 AI 工作流进一步打通了。
它不再只是个“工具”,更像是你的实习生、下属、助手——你只需给出需求,它会自动理解你的意图,拆解任务、查找资料、调用模型,全流程帮你搞定。
那么问题来了,我们应该怎么做?
其实我在最近几篇文章里已经说了很多次:
“学会下达需求,也就是学会写 Prompt(提示词)
,这件事,比你想象中重要得多。如果你写不出清晰、明确、符合预期的提示词,那 AI 也很难真正理解你的“真实意图”。自然,输出结果就不可能让你满意。更重要的是——不会写 Prompt,就等于不会用 AI。你的认知差距,最终会被同行人不断拉大。”
所以这里也先给自己埋个坑:我是有计划为大家分享提示词相关的干货教程哈。
最后,引用 比尔·盖茨 的一句话作为收尾:
"The true value of technology is its ability to let humans focus on creation, not repetitive tasks."“技术的真正价值,在于它能让人类专注于创造,而不是重复劳动。”
71
举报
声明
158
分享
相关推荐

















评论你的想法~
表情
喜欢TA的作品吗?喜欢就快来夸夸TA吧!
推荐素材

























你可能喜欢













相关收藏夹























登录注册
71登录即可同步推荐记录哦
99+登录即可加入我的收藏
评论登录即可评论想法
分享分享