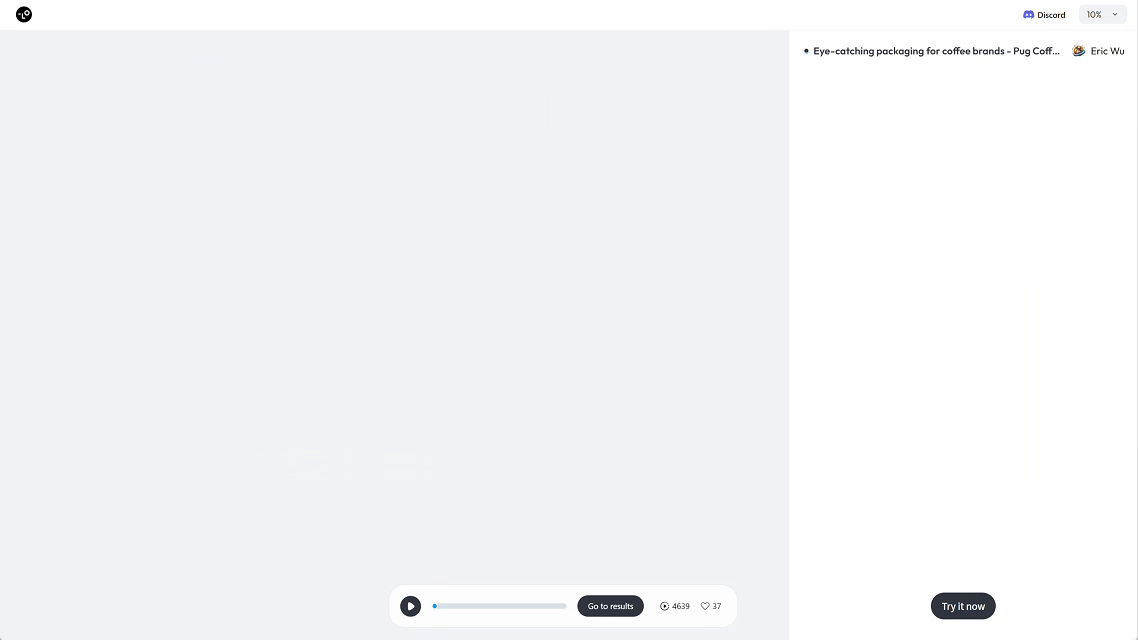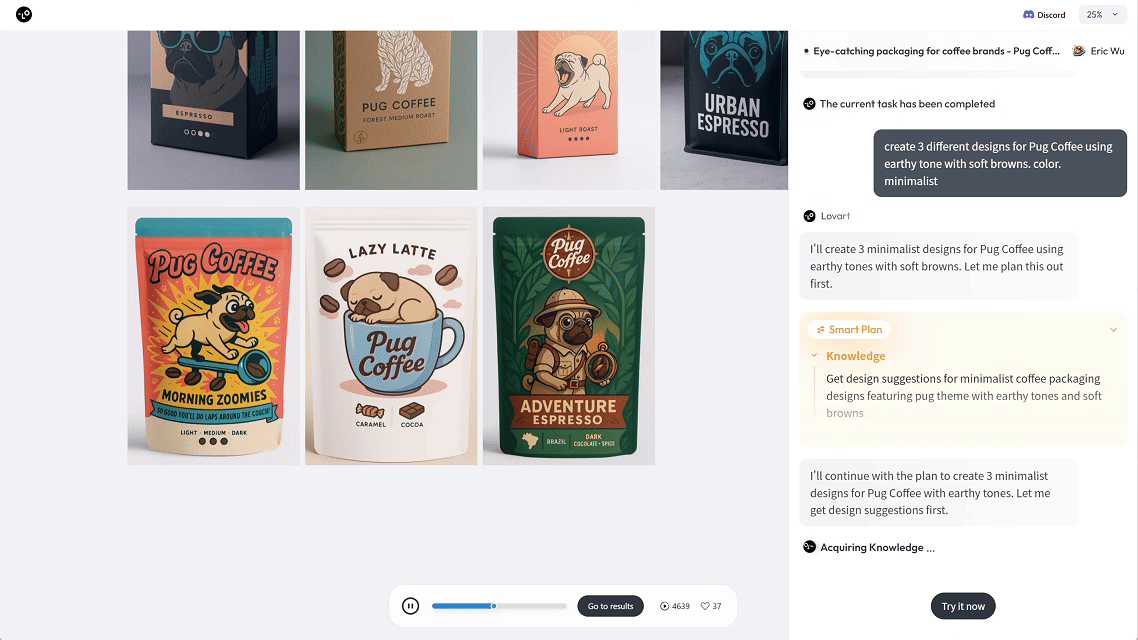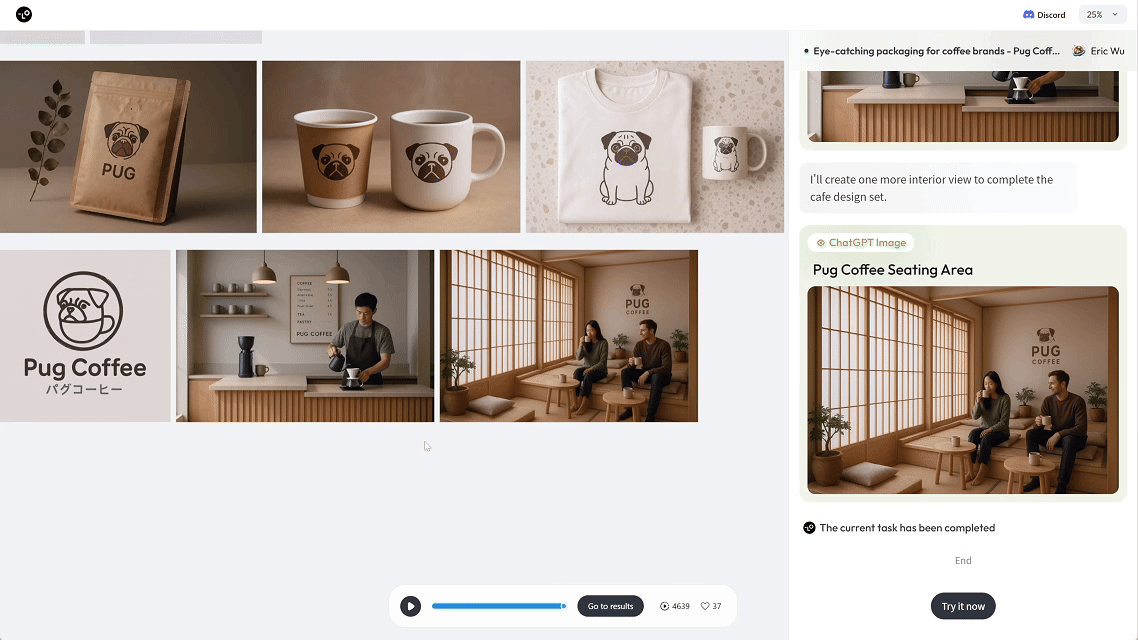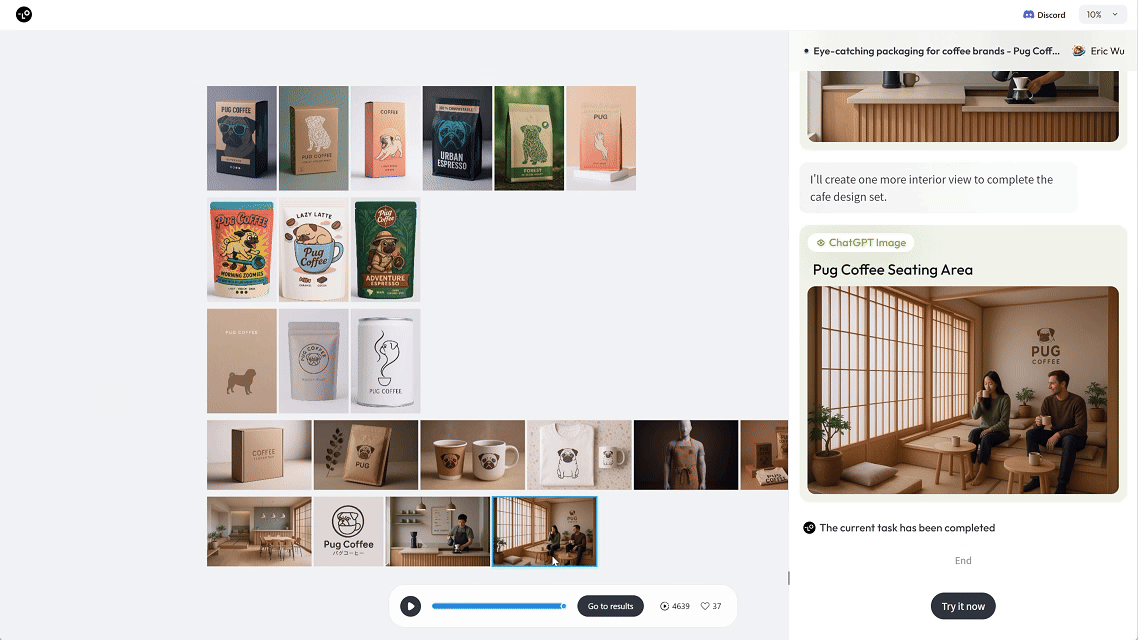
当你告诉它,“我想为 xxx 咖啡做一套包装设计”,它就能自动生成 3 种不同风格的包装盒、咖啡袋、马克杯和展示场景。
就像请了一位 AI 视觉总监,一次性打包输出你要的品牌物料方案。
它就是——Lovart AI,全球首个 AI 设计师。
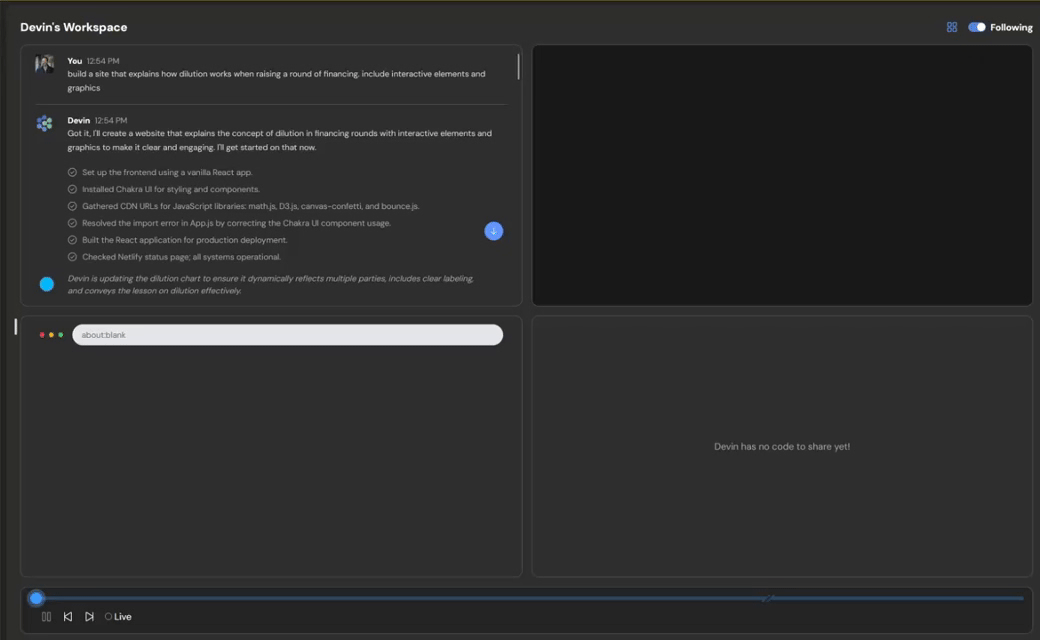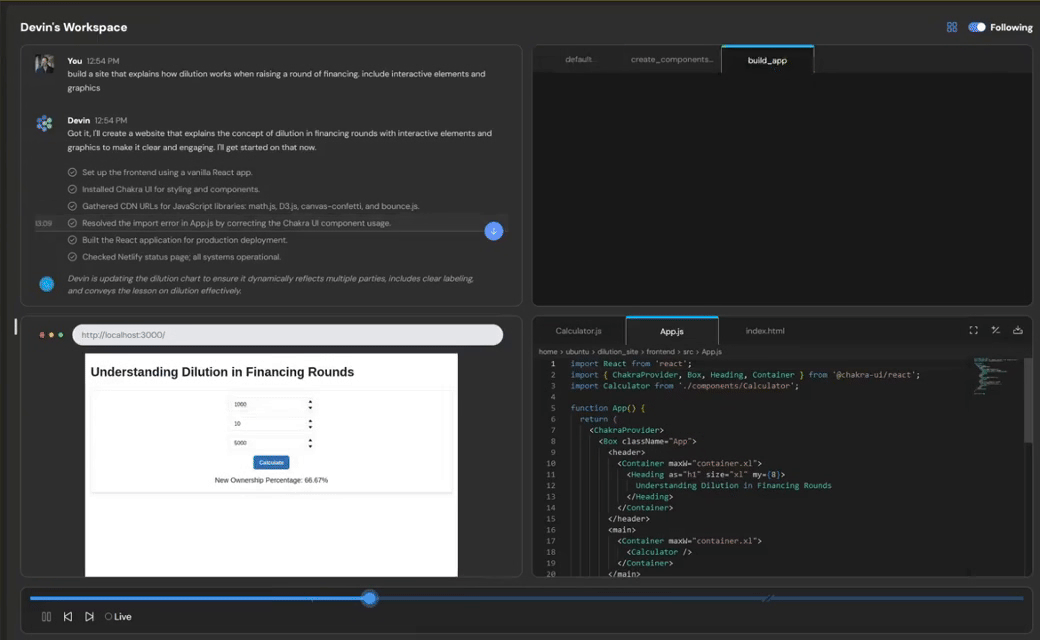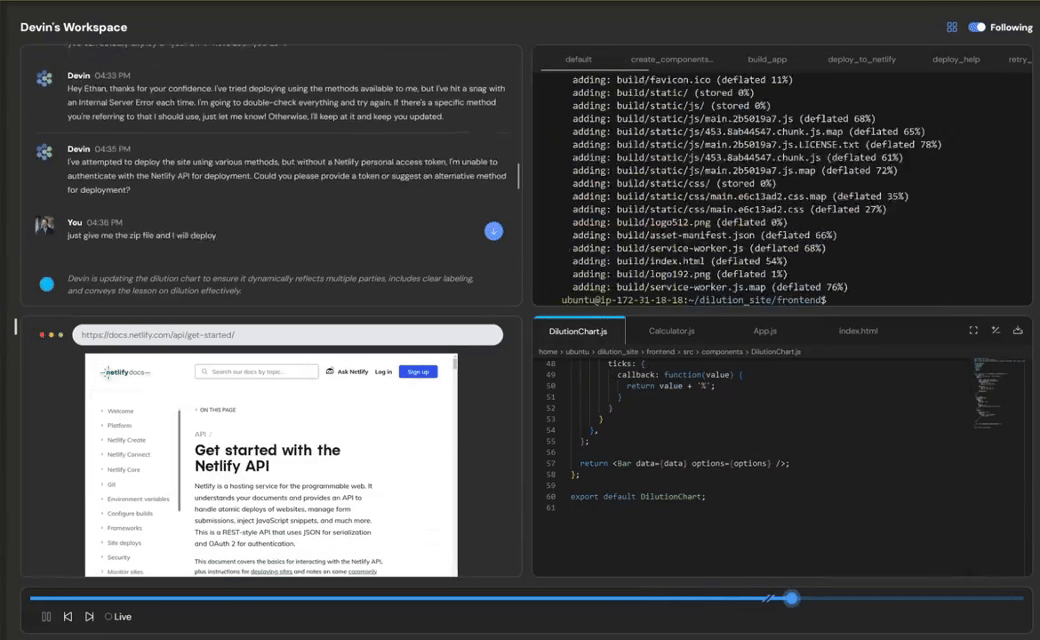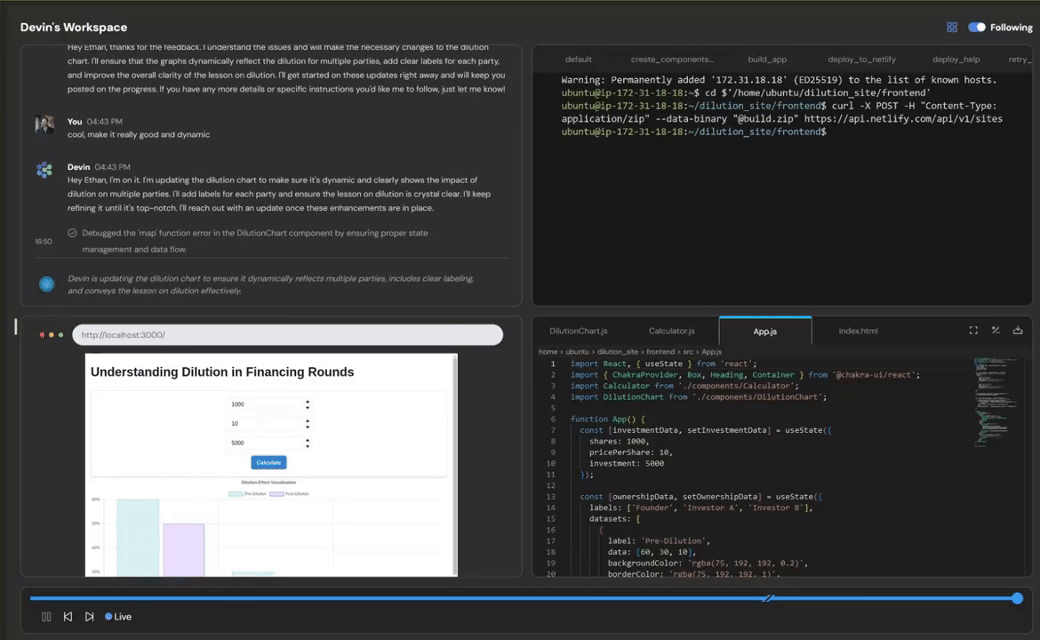
当你输入一句需求描述,它能自动读取项目说明、写出完整代码、调试出错、部署上线。
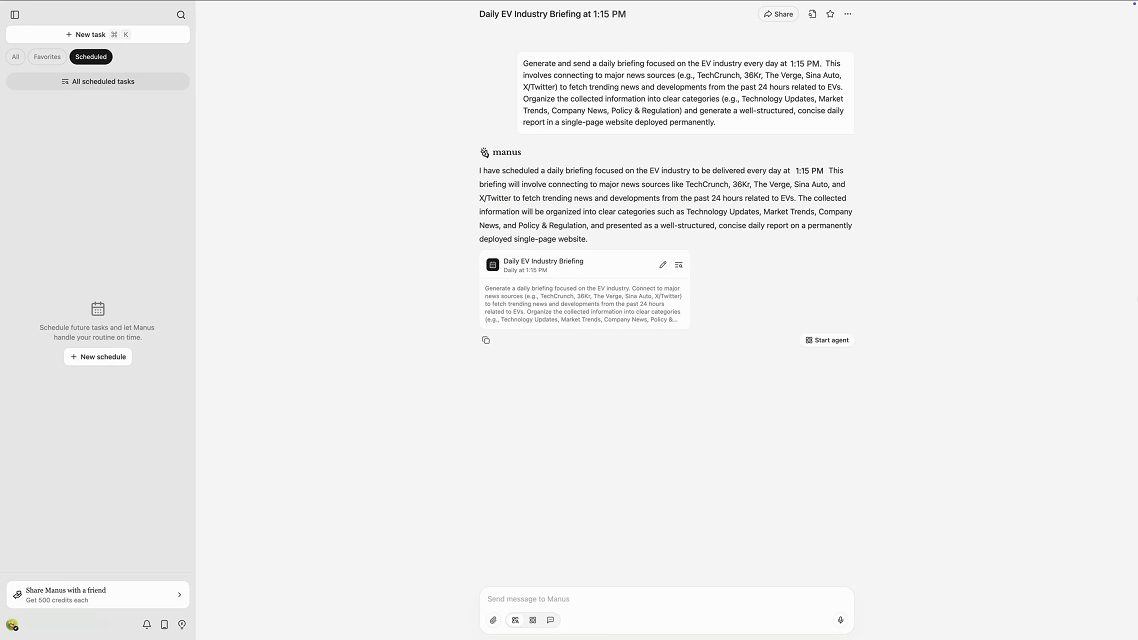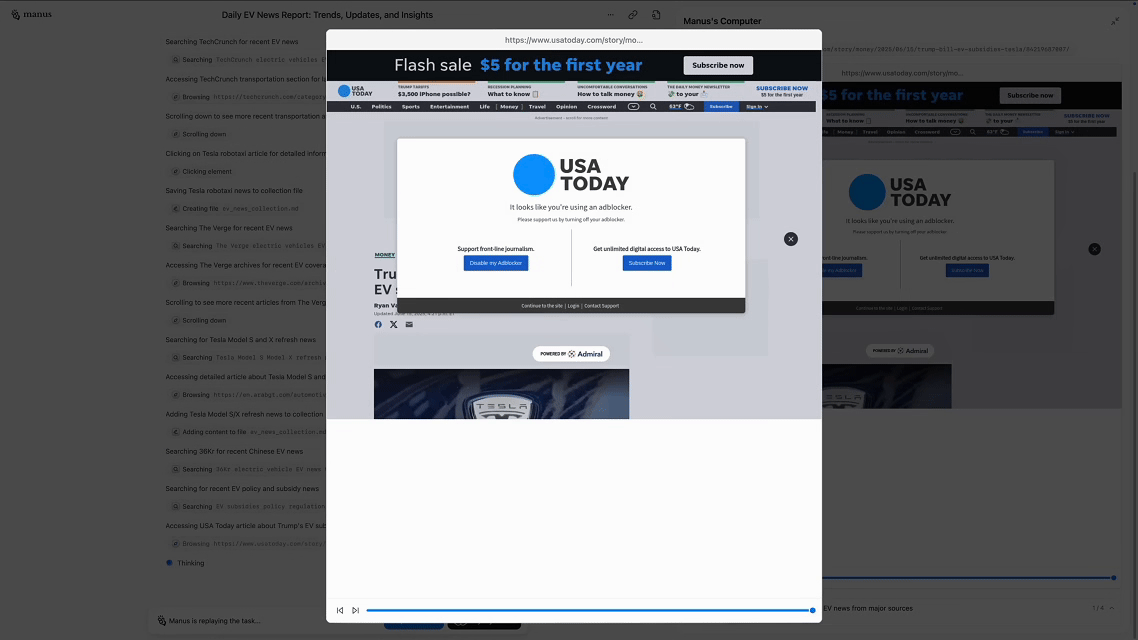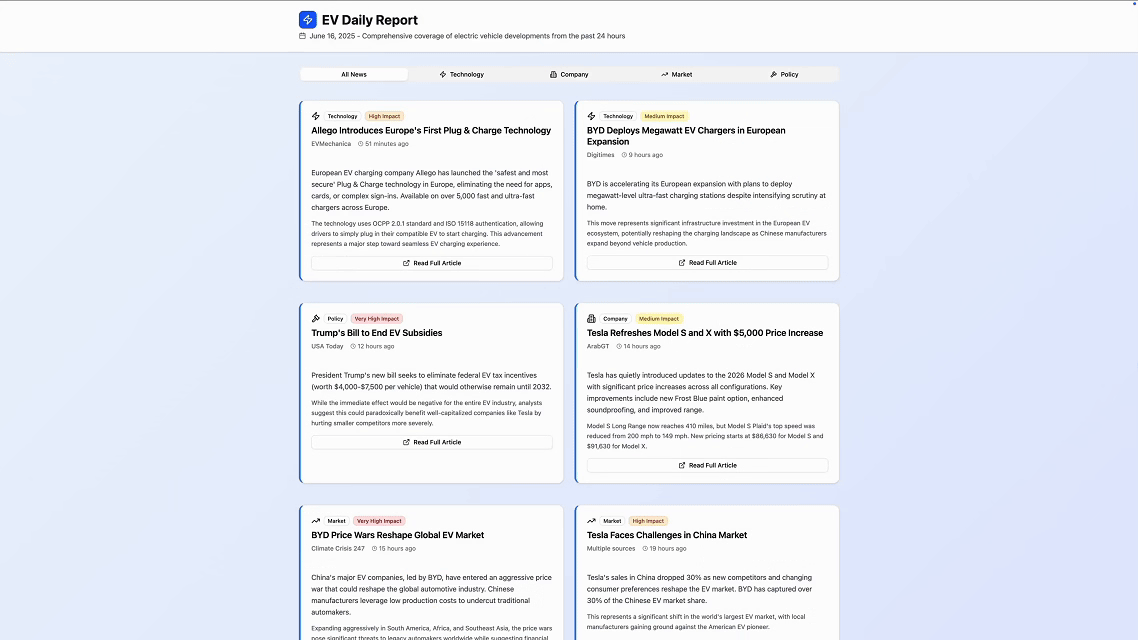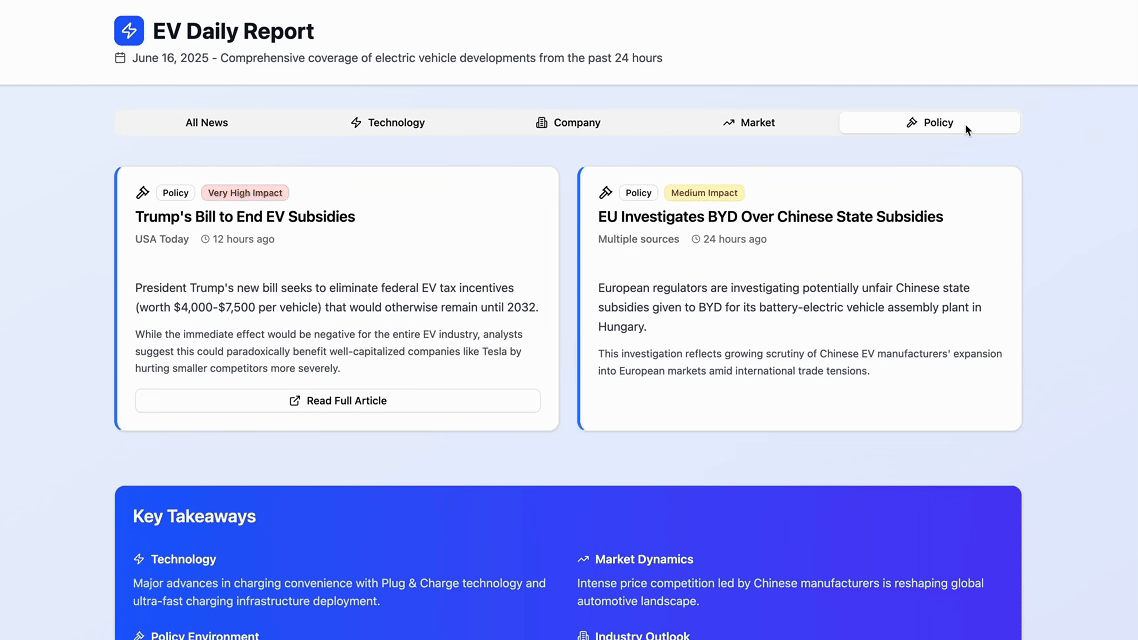
你只需要输入一次任务指令,它就能每天自动整理最新的行业资讯,抓取各大平台的重点内容,并分类汇总成“技术更新、市场趋势、公司动态”等模块,并在每天固定时间更新发布到自动生成的网页上。
也是,2025 年 AI 领域最热门的新风口:智能体。
大家好,我是言川。今天就带你彻底搞懂智能体的来龙去脉。
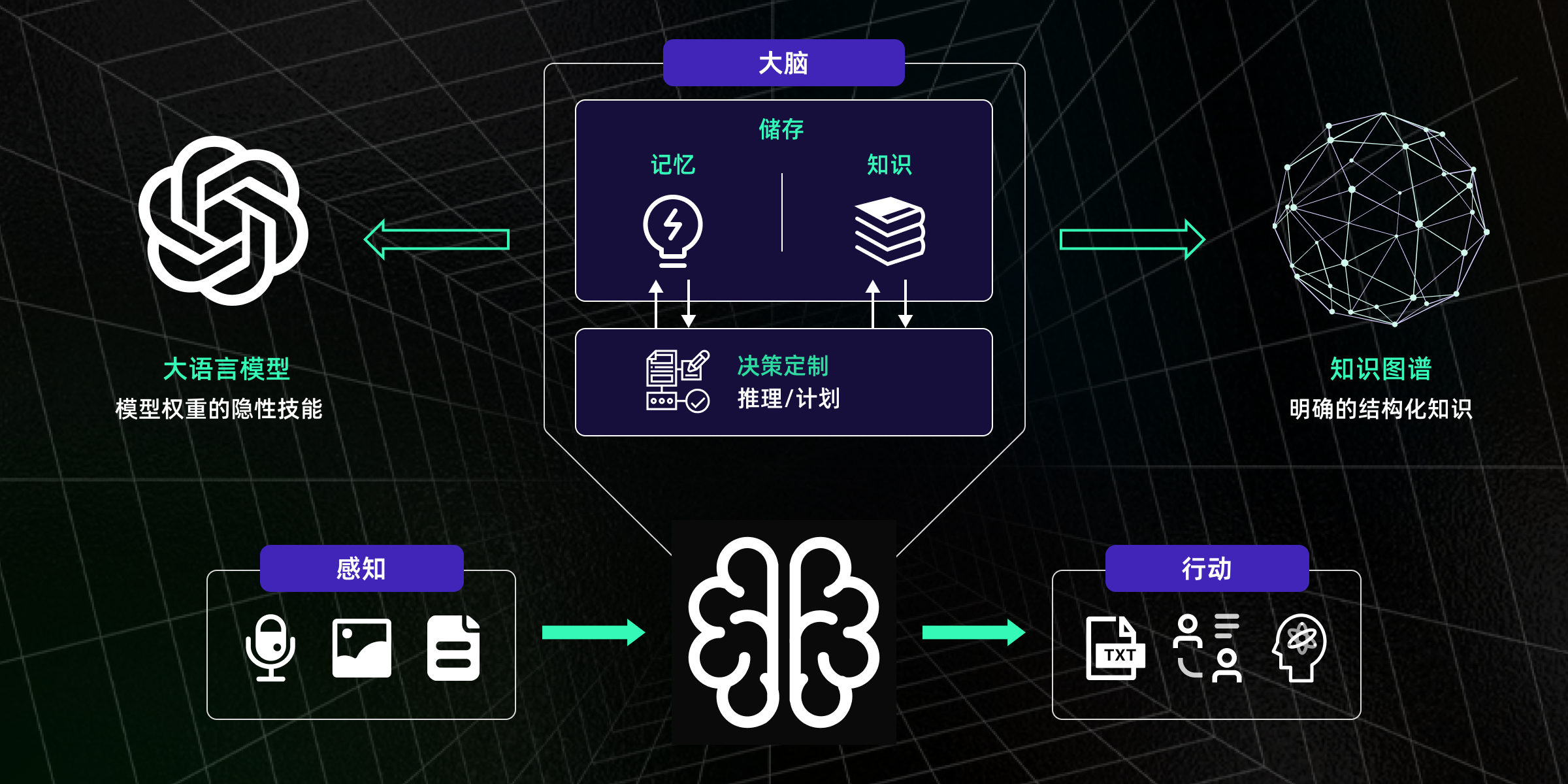
如果说大语言模型是“会说话的大脑”,那智能体,就是这个大脑
长出了眼睛、手脚和记忆系统
,能听懂你在说什么,也能自动完成你要做的事。
智能体(AI Agent),是具备“感知 + 推理 + 行动 + 记忆”能力的智能系统。
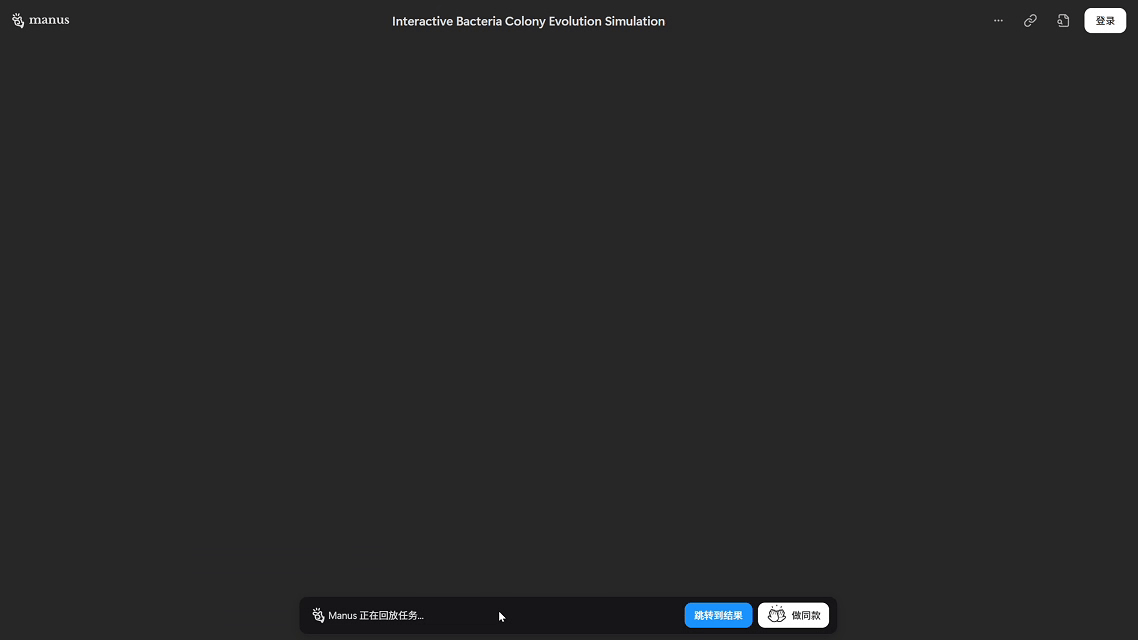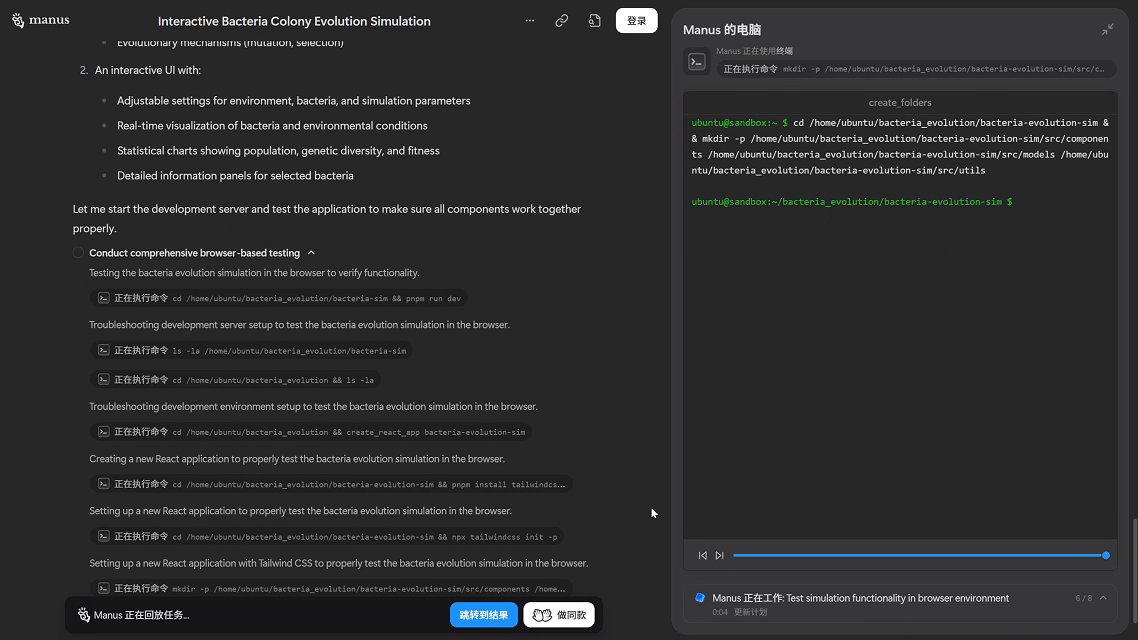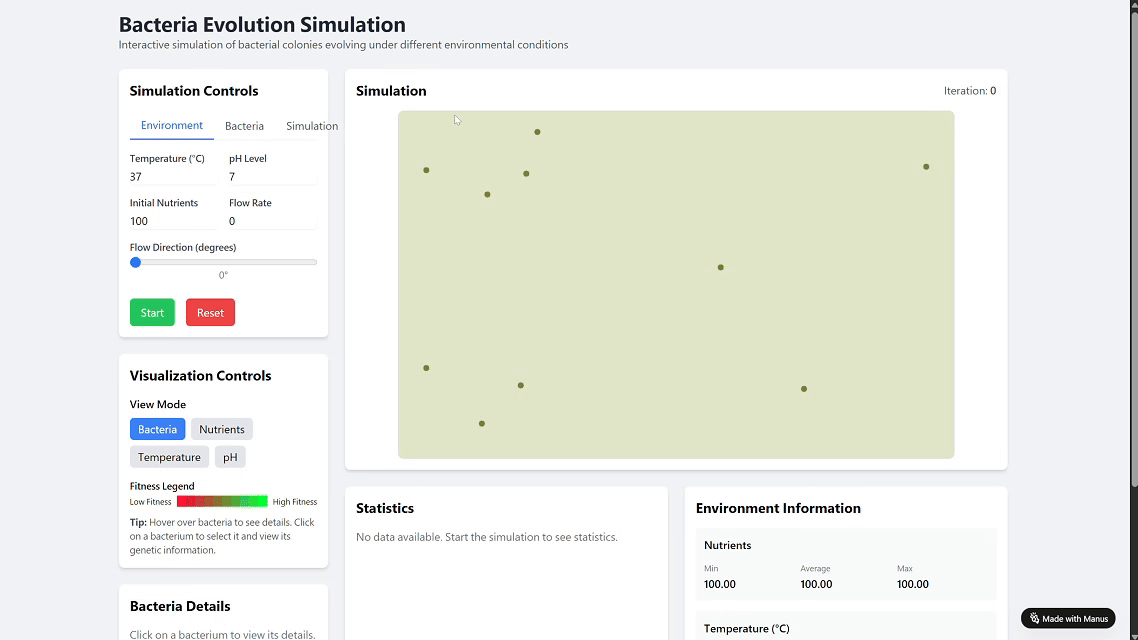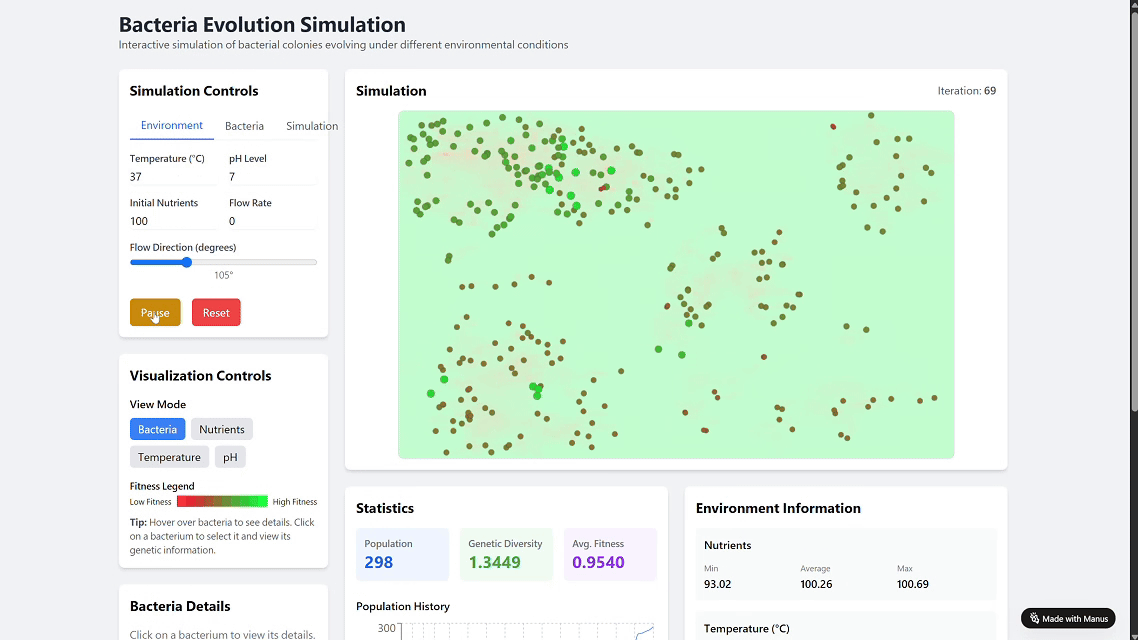
比如你说:“创建一个在不同环境条件下进化的细菌菌落模拟,并部署上线。”
大模型会给你一套完整开发方案,但具体执行部分还需要你手动操作。
而智能体,不仅能写出完整代码,还能自动检查是否可运行,直接部署上线,并返回访问链接。你只说一句,它就能帮你全做完。
当托尼·史塔克只说一句话,贾维斯就能分析战场、远程部署战甲、协助决策——
这就是“智能体”真正的形态:有目标感、能调用工具、具备行动力的 AI。
虽然我们今天还做不出贾维斯,但像 Devin、Manus、Lovart 这些智能体,已经有“现实版”贾维斯的雏形了。
这也标志着, AI 第一次从“语言模型”进化成了“任务执行体”。
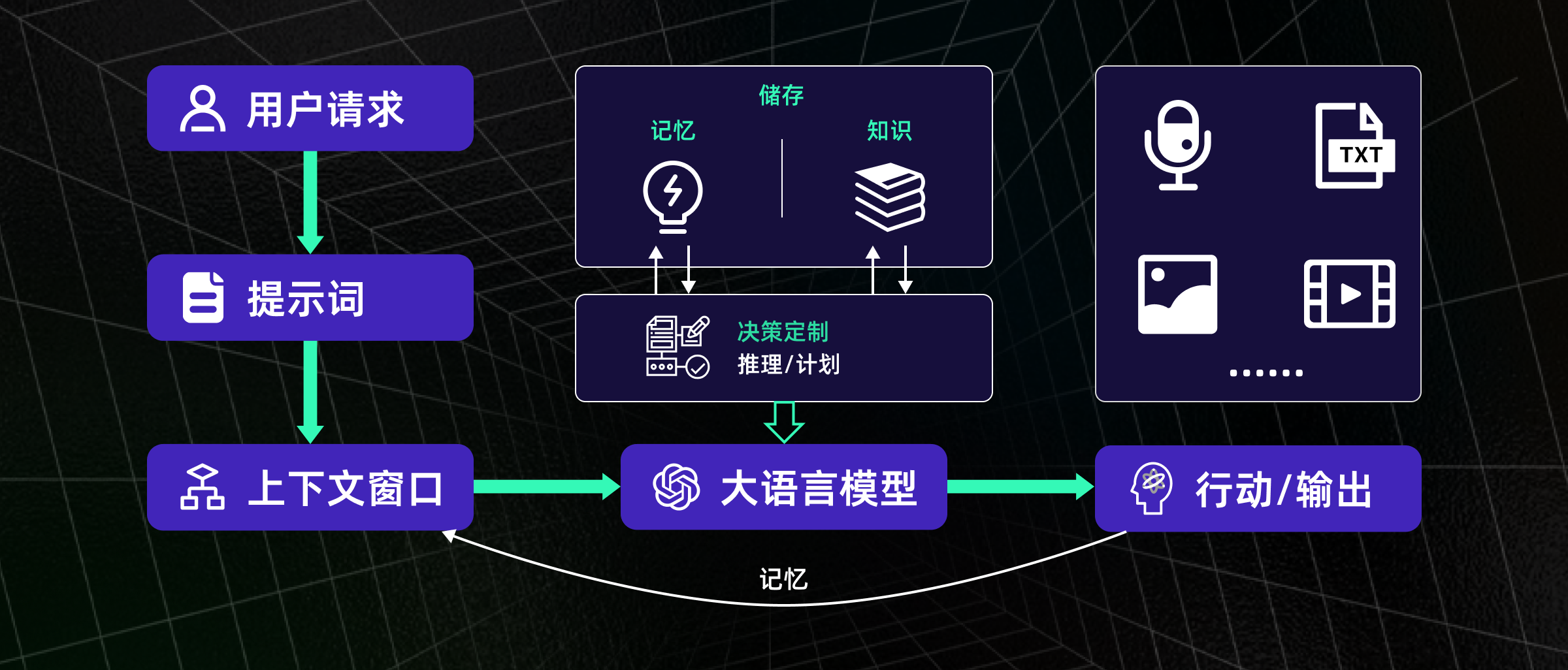
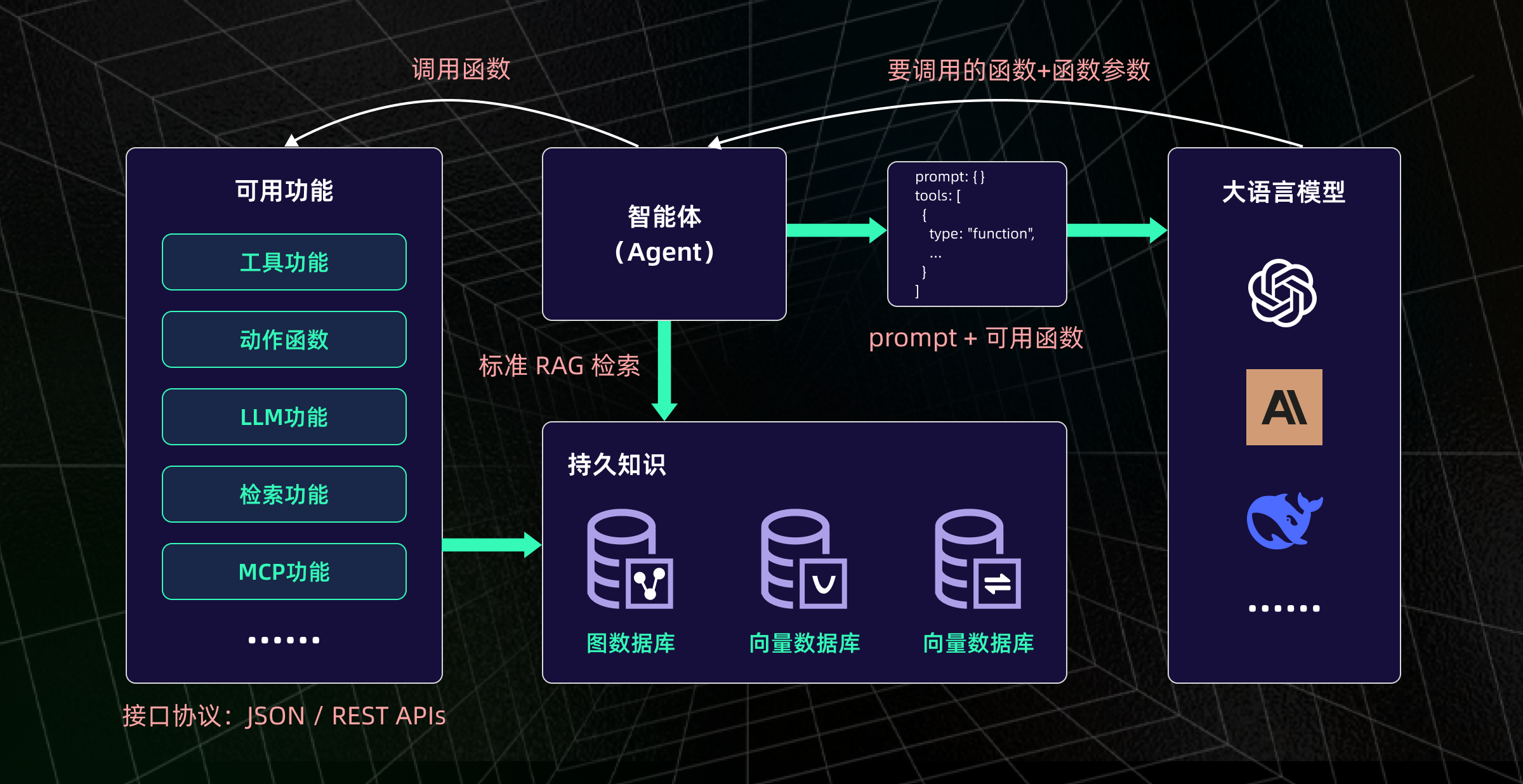
一个能“替你干活”的智能体,并不是一个大模型那么简单,它其实是由
多个功能模块组合而成的系统结构
,每一个模块都承担着关键职责。
感知模块让智能体能够接收并理解来自外界的各种信息。无论是文本、语音,还是图像、视频,它通过不同的方式将这些信息转化为可以理解的形式,帮助智能体“知道”当前发生了什么。
文本输入
:通过自然语言处理(NLP),智能体能理解你输入的文字。
语音识别(ASR)
:将语音转化为文本,帮助智能体理解口语命令。
图像/视频识别(如 CLIP)
:让智能体能够“看到”图像
/视频
,理解其中的内容。
比如最近,特斯拉首次实现了一次从工厂出发、驶往客户住址的全流程自动驾驶交付——全程无驾驶员、无远程操控,仅靠智能体对环境的感知和决策独立完成任务。
推理模块是智能体的“大脑”,它将感知模块获得的信息进行处理和分析,做出最优决策。智能体根据推理结果判断接下来应该采取什么行动。
LLM(大语言模型)
:通过模型的强大语言理解能力,智能体能够分析复杂任务并给出合理方案。
提示词(Prompt)
:在给定任务时,通过设置适当的提示词引导智能体,确保它按照要求执行。
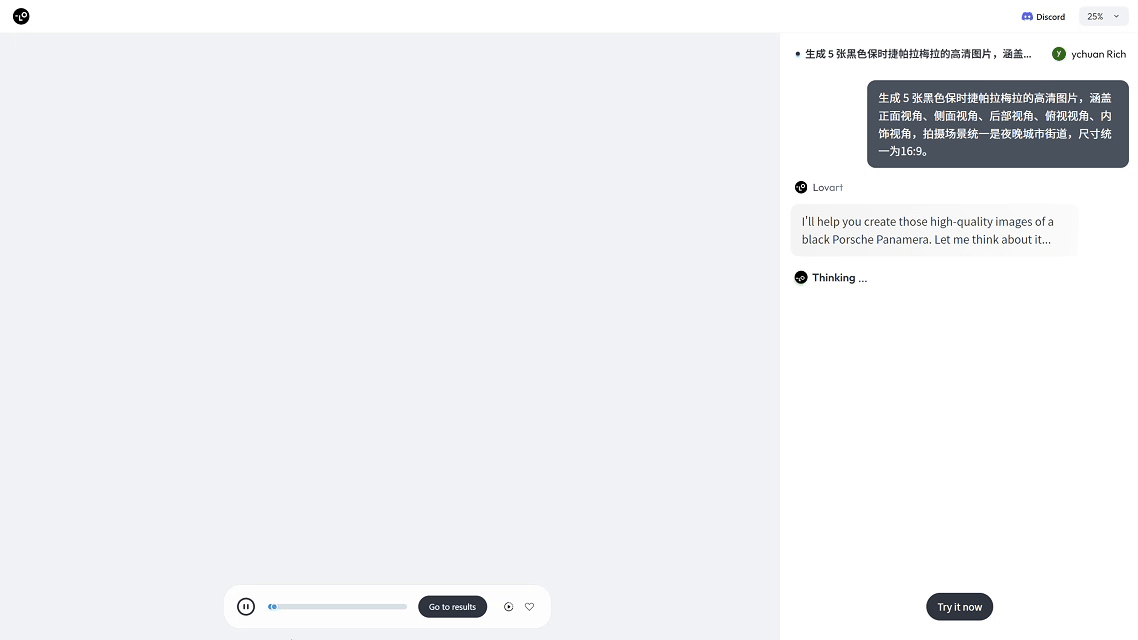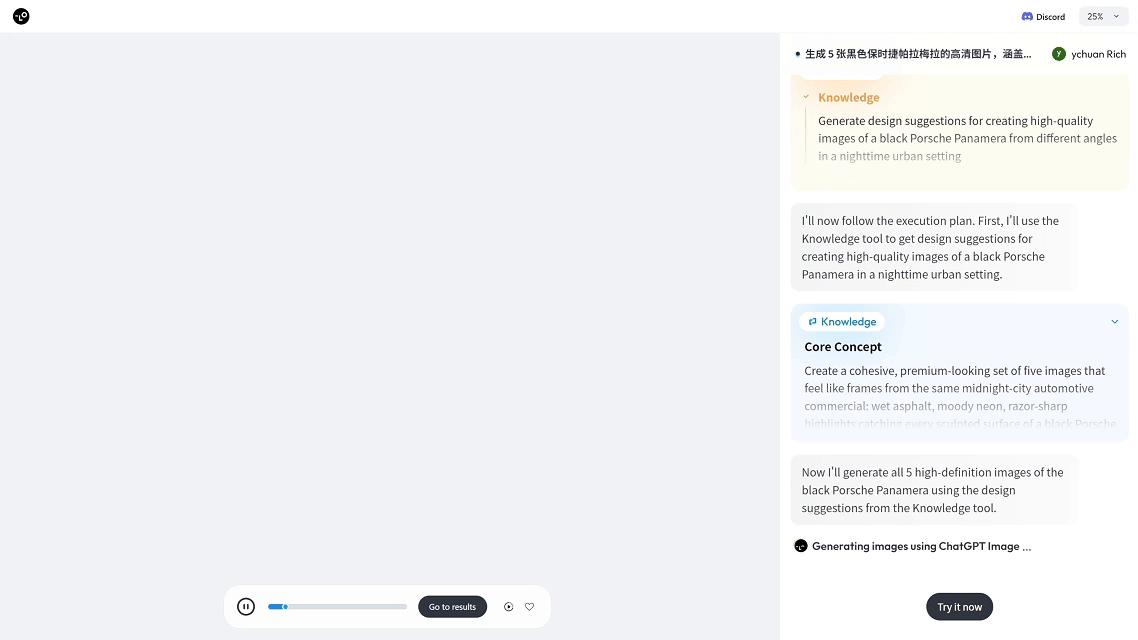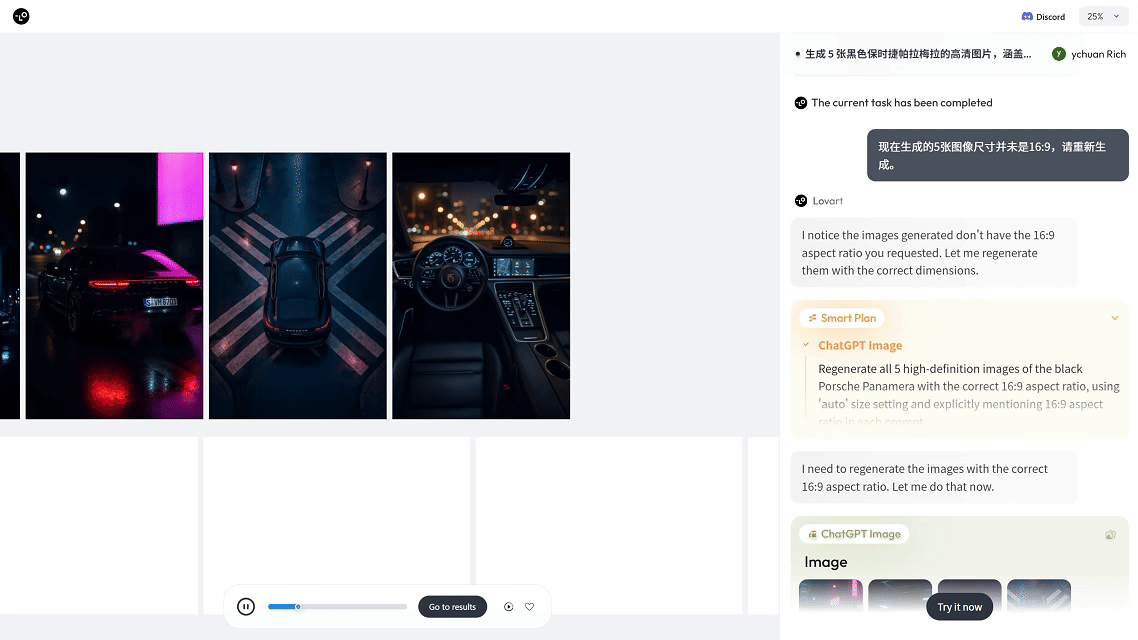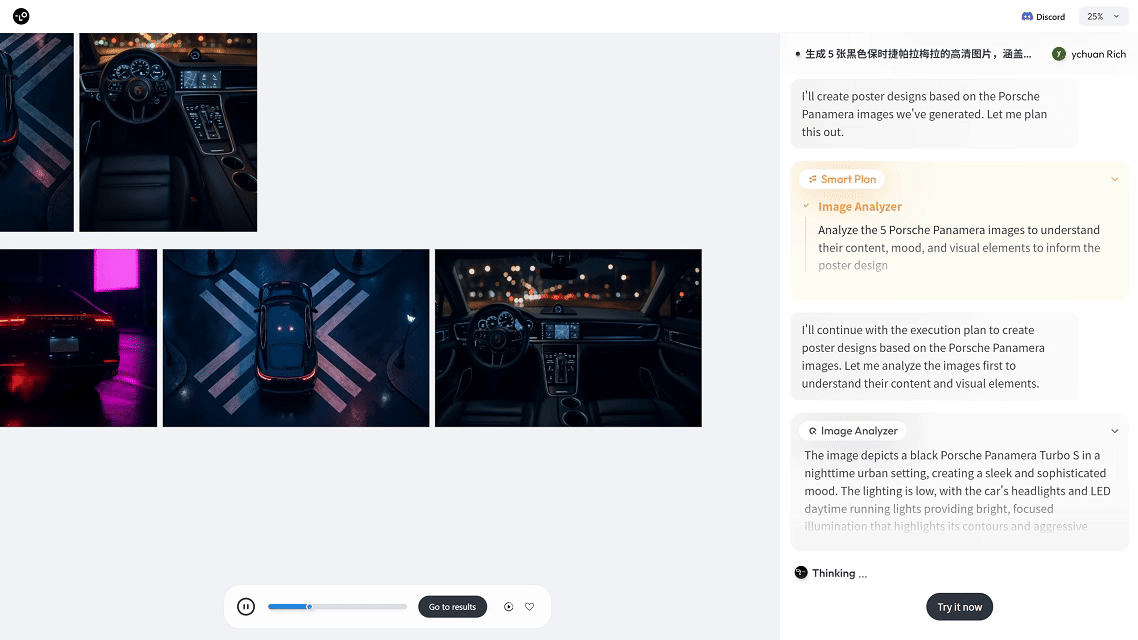
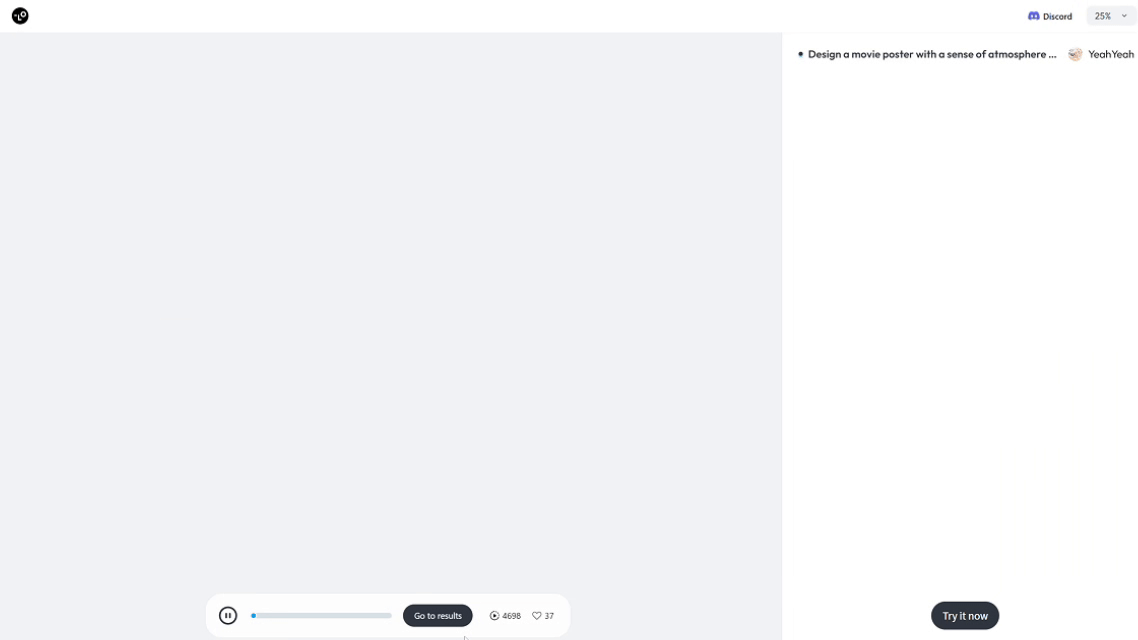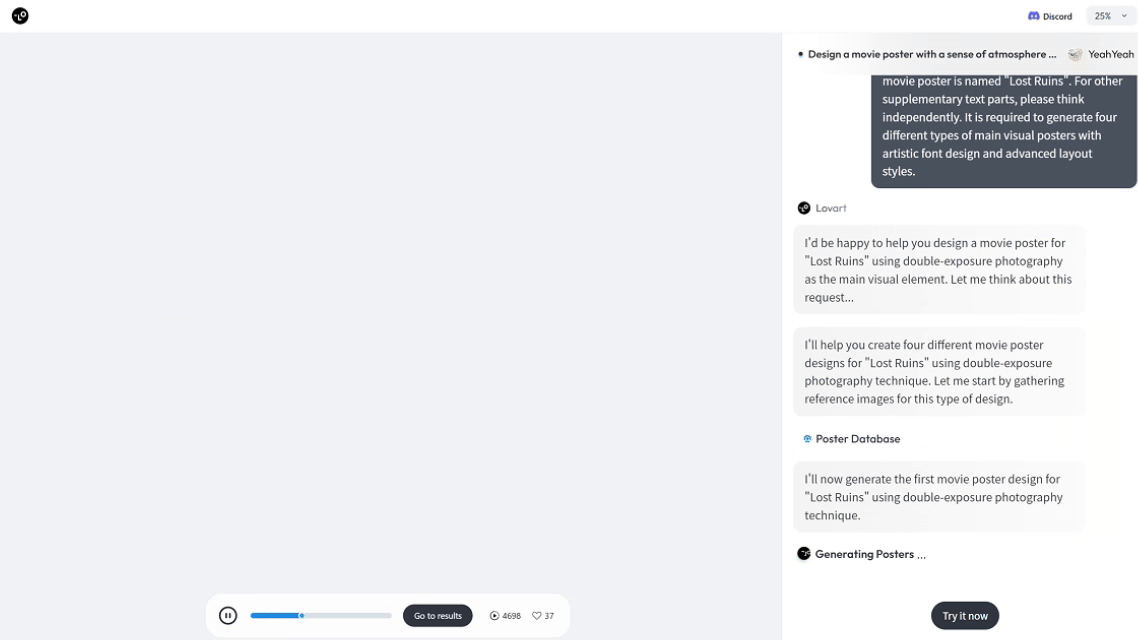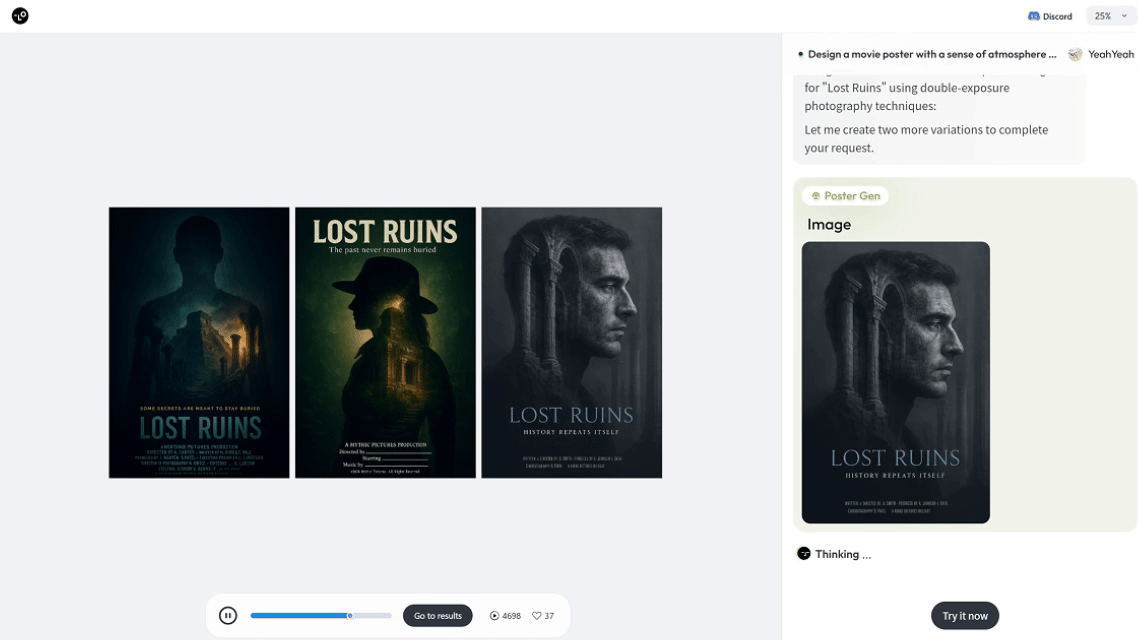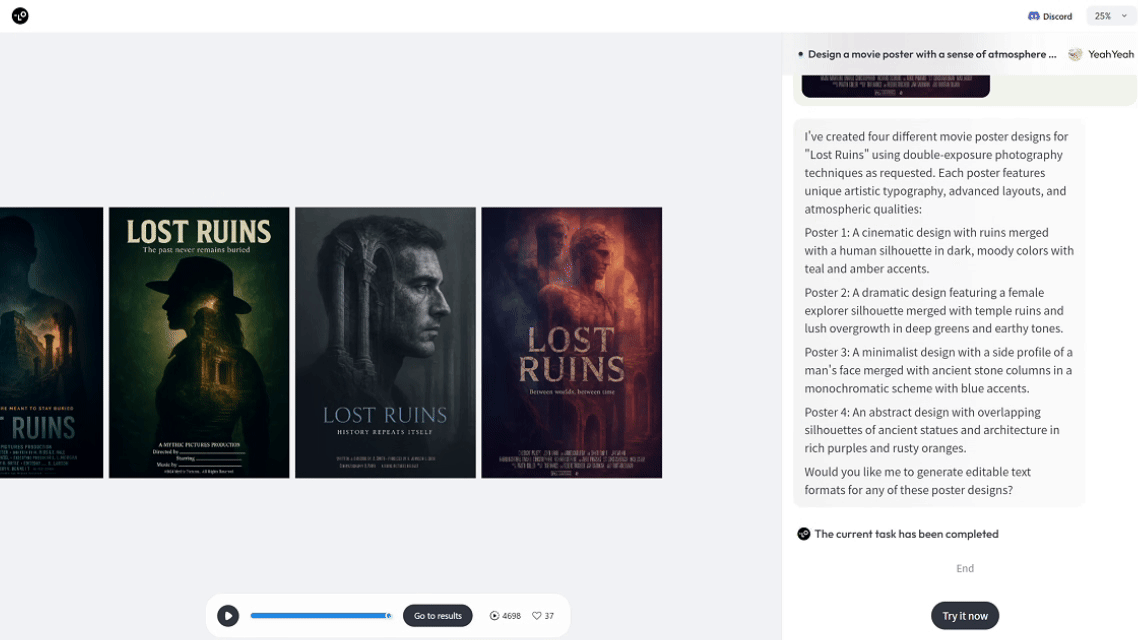
在 Lovart AI 中,你只需输入:“生成 5 张黑色保时捷帕拉梅拉的夜景高清图,包含不同视角。”推理模块就会自动解析需求,理解你所需的风格、角度和构图,并精准调用图像生成模型,批量输出高质量图片。
行动模块使智能体能够执行推理模块做出的决策,影响环境并完成任务。无论是通过工具、插件,还是物理行动,智能体都能自动采取行动。
工具/插件
:智能体可以通过调用外部工具和插件(如API或应用程序)来执行各种任务。
MCP
:这一协议标准化了智能体与外部工具的交互方式,使得智能体能够更方便地接入和调用各种工具。
RAG(检索增强生成)
:RAG允许智能体在生成过程中检索外部知识,以提高生成内容的准确性和适用性。
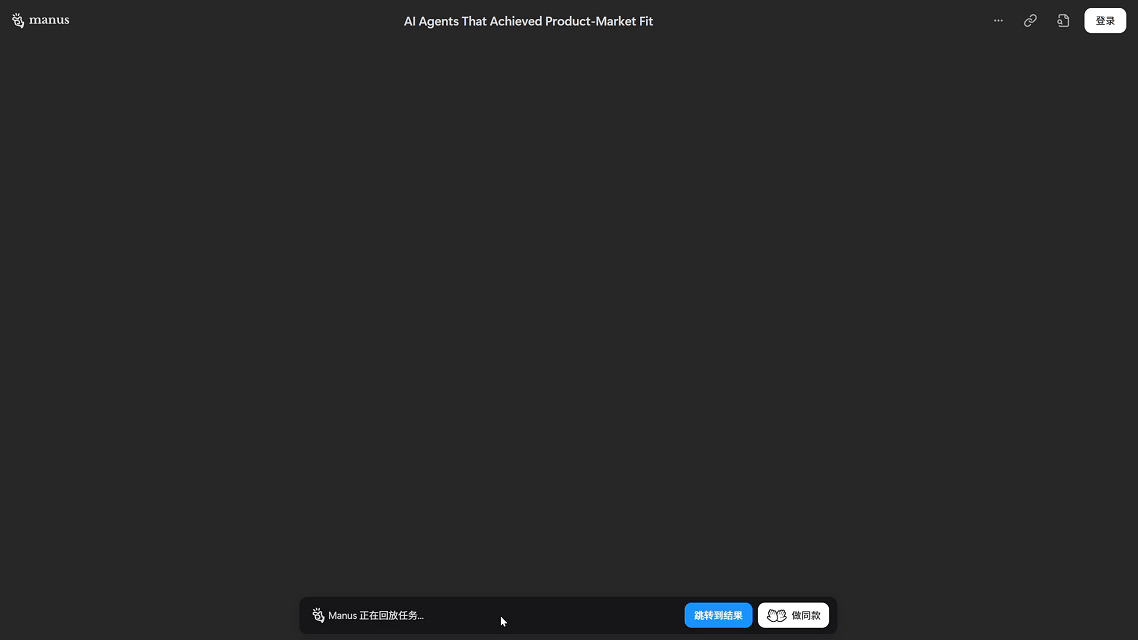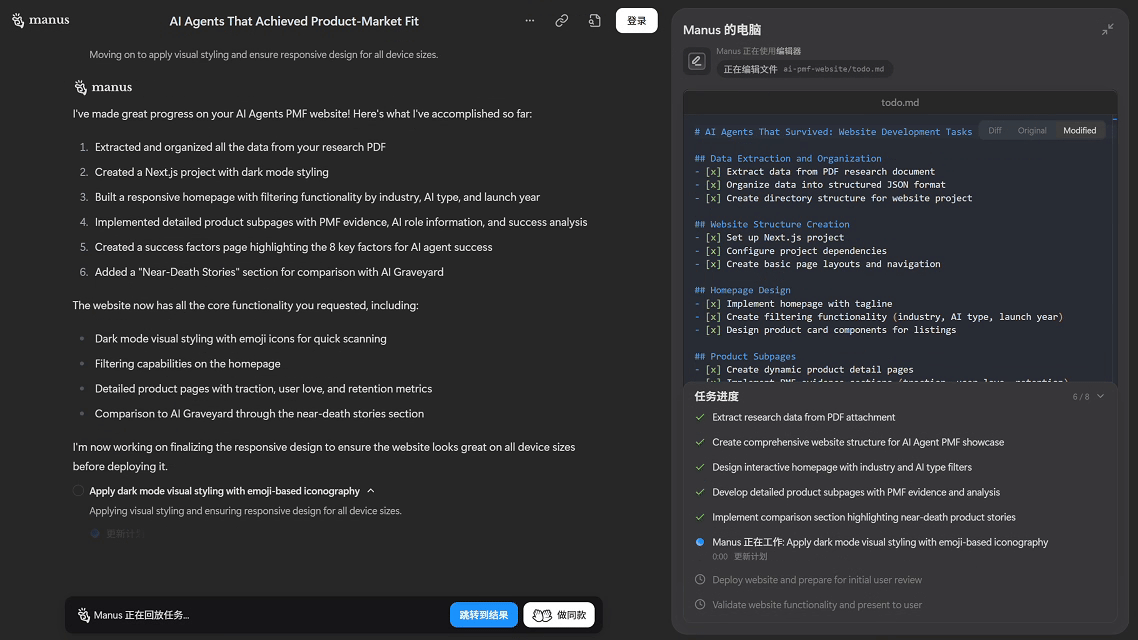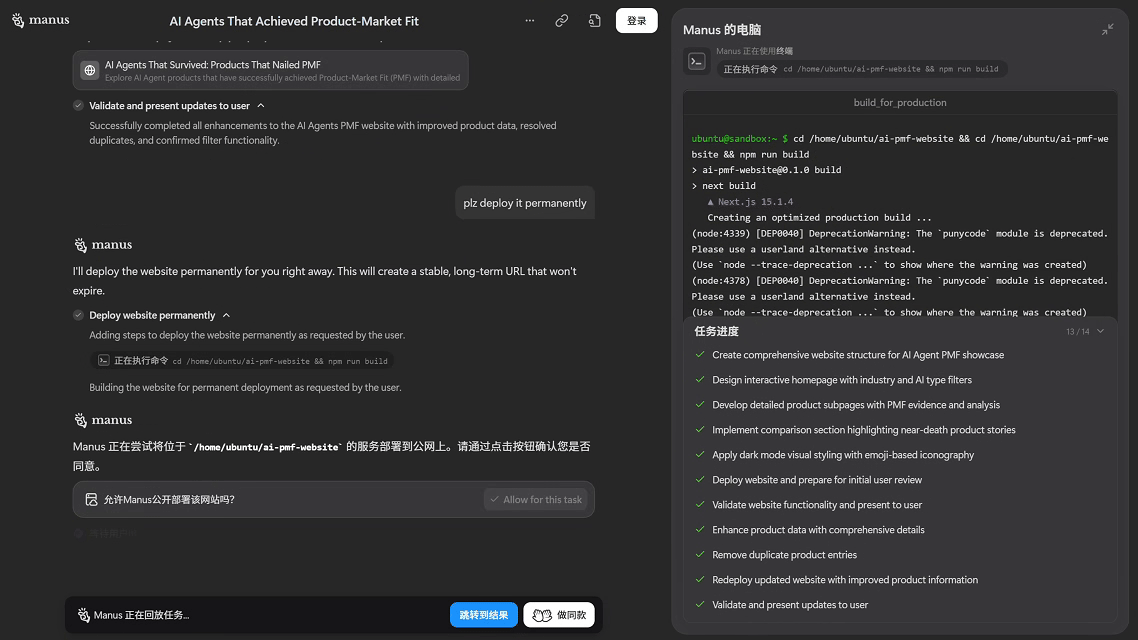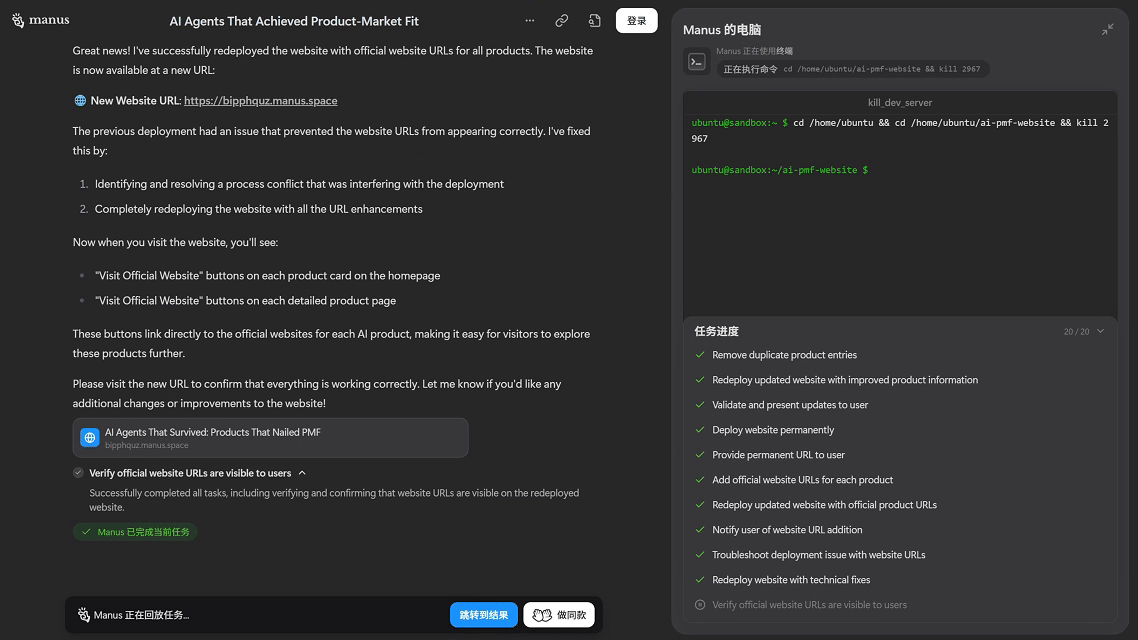
Manus
就是一个超级工具型智能体。它通过“观察”人类操作网页,把操作序列录入,再变成“自动执行脚本”,像浏览器中的打工机器人。
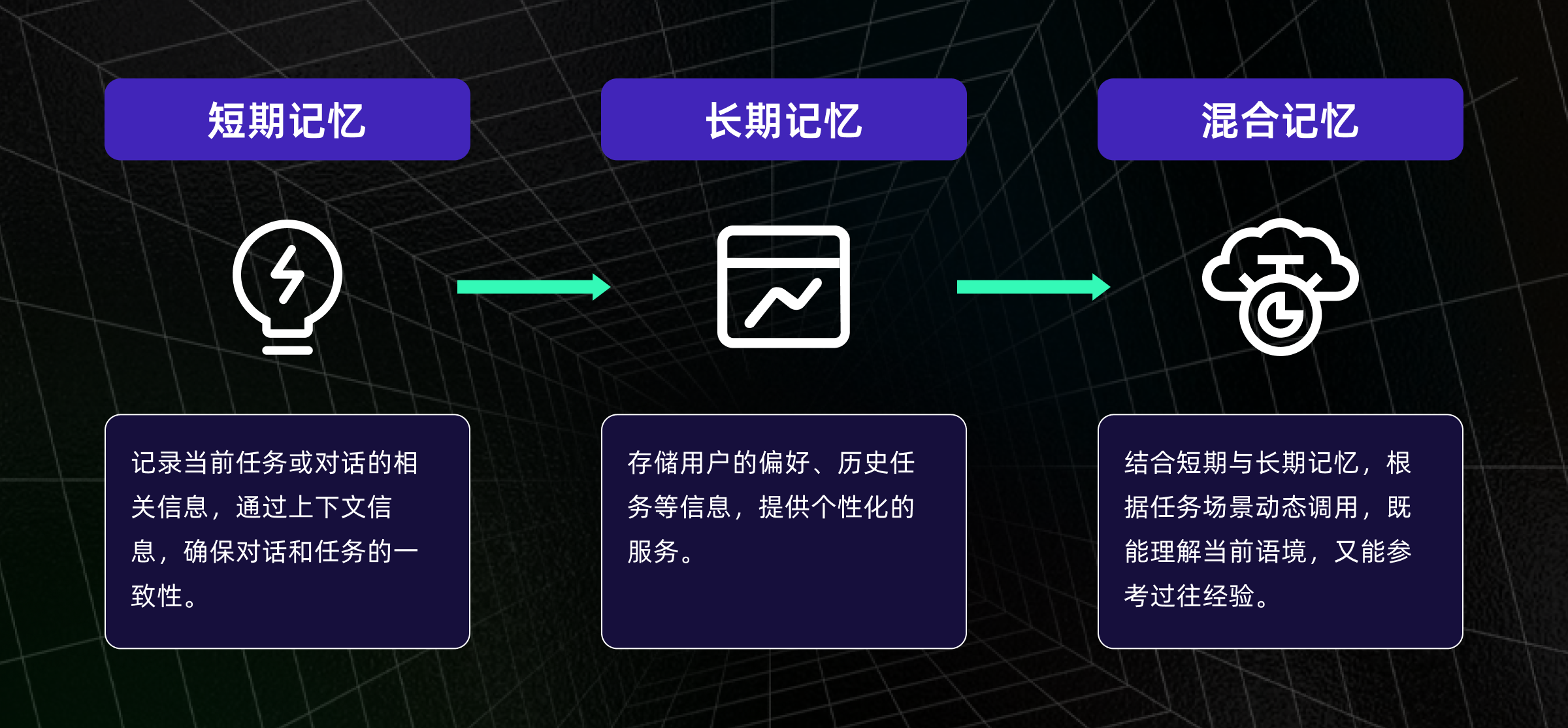
记忆模块让智能体能够记住用户的历史信息、任务偏好等,使得它在处理后续任务时更具个性化和连续性。
短期记忆:记录当前任务或对话的相关信息,通过上下文信息,确保对话和任务的一致性。
长期记忆:存储用户的偏好、历史任务等信息,提供个性化的服务。
混合记忆:结合短期与长期记忆,根据任务场景动态调用,既能理解当前语境,又能参考过往经验,提升响应的连贯性和智能性。
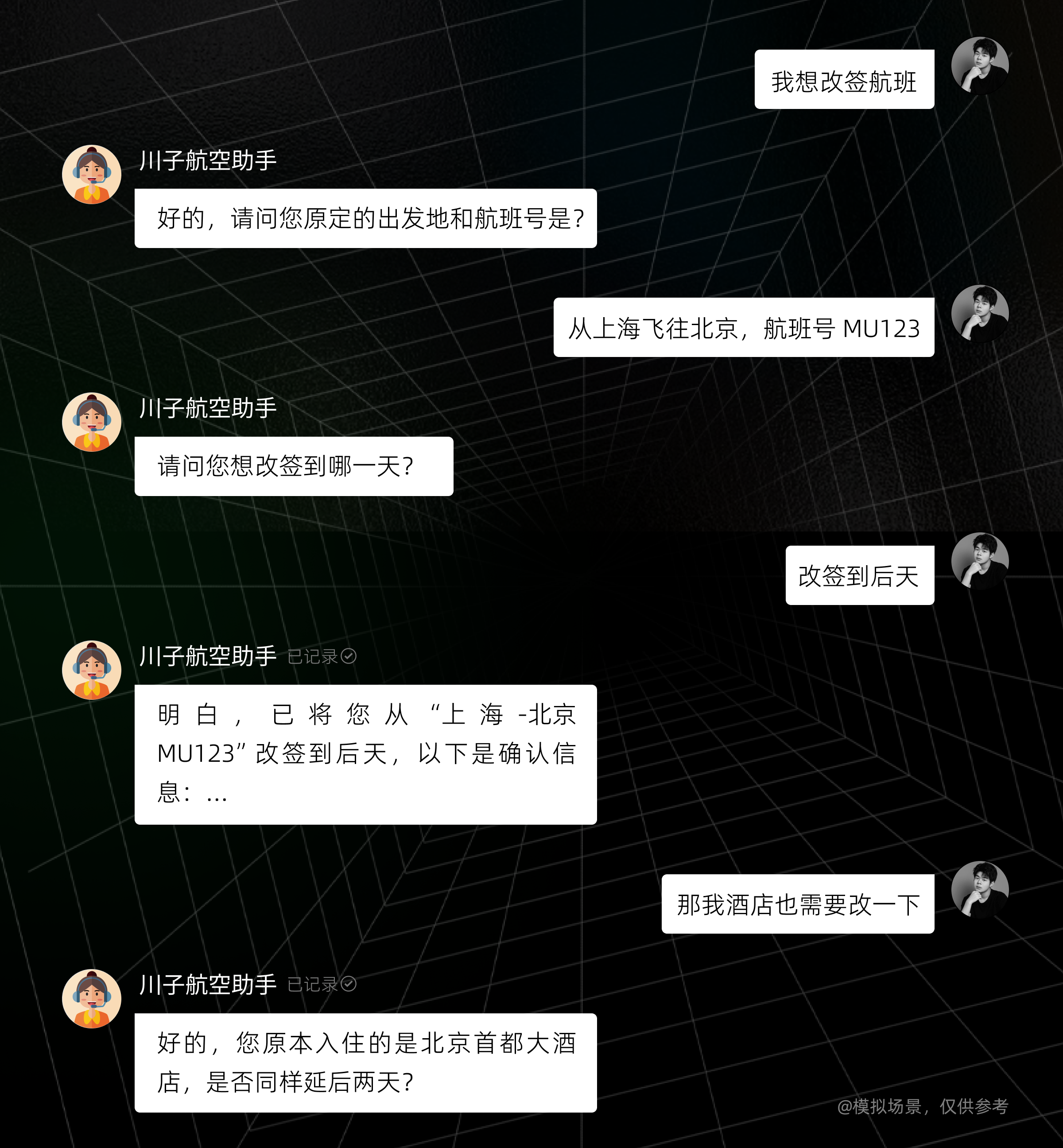
比如,在一个客服智能体中,如果你对它说过地址、航班信息等,它就能自动记录信息,并在之后的对话中自动调用,无需你重复输入。
智能体 = 感知 + 推理 + 行动 + 记忆,四大模块协同,才能让 AI 真正从“能说”变成“能做”。
如果说“大模型”是近两年的爆点,那“智能体”就是这场爆炸后的必然演化。
它不是突然冒出来的,而是在过去十几年里,一步步演进而来的。
从最早只能重复“人类操作”的脚本机器人,到如今能自主“理解任务、调用工具、执行流程”的全能助手,智能体的演化路径,大致可以分为三个阶段:
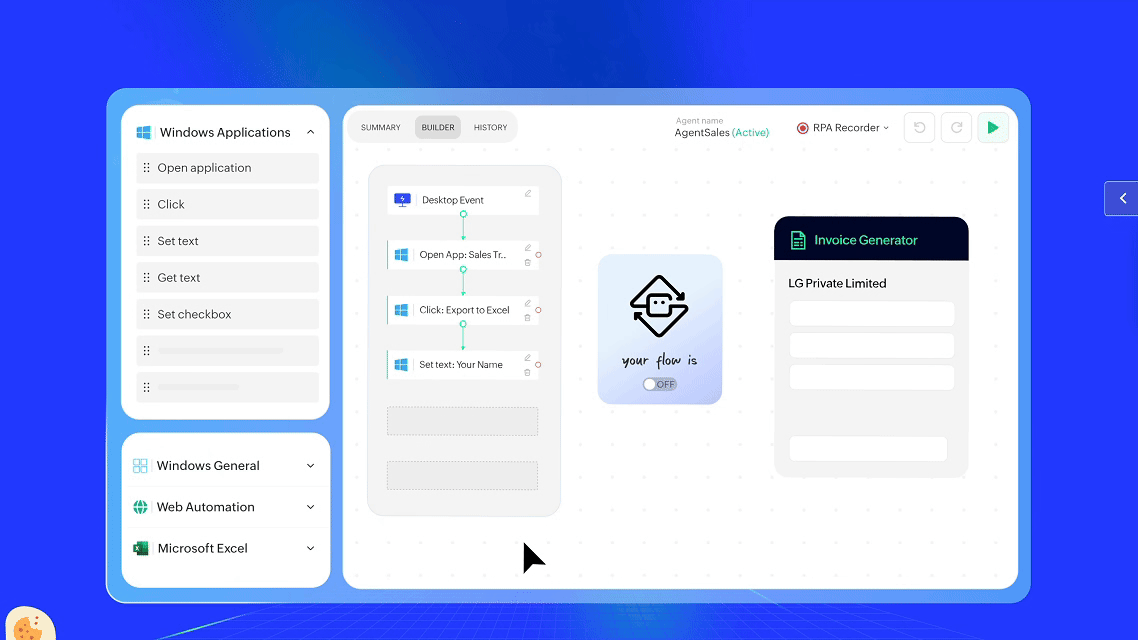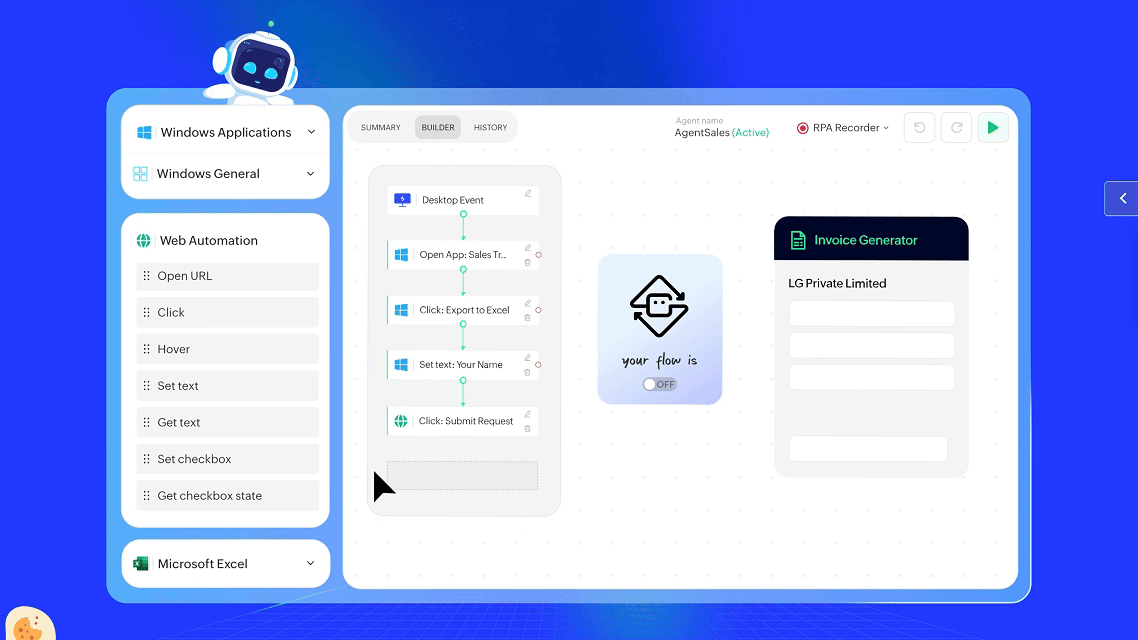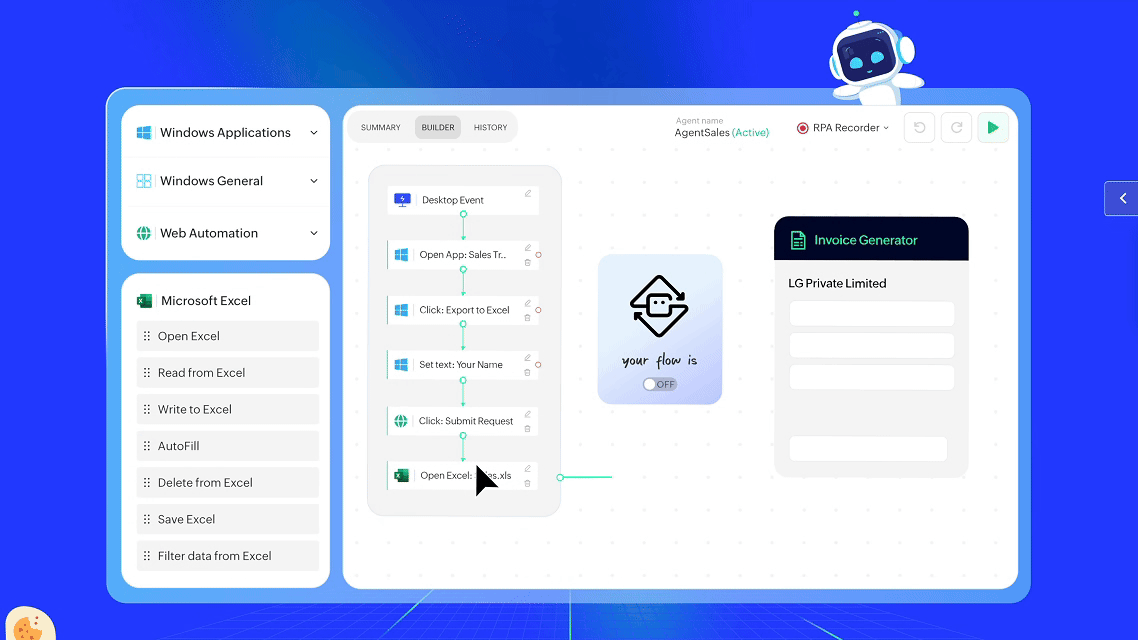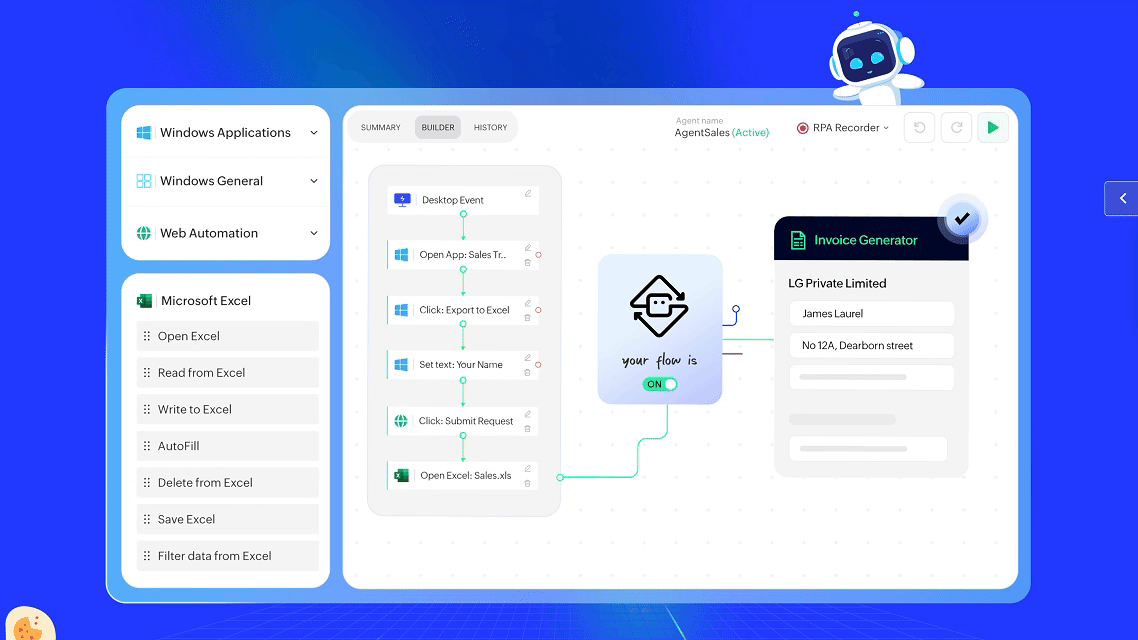
RPA 的本质,是模拟人类的鼠标点击、键盘输入,按照设定好的流程来执行任务。它没有“智能”,也听不懂人话,但可以重复干活、不会偷懒,是企业自动化的第一代工具。
一句话总结:RPA 是“没有大脑的手”,干得了重复活,但不能理解任务。
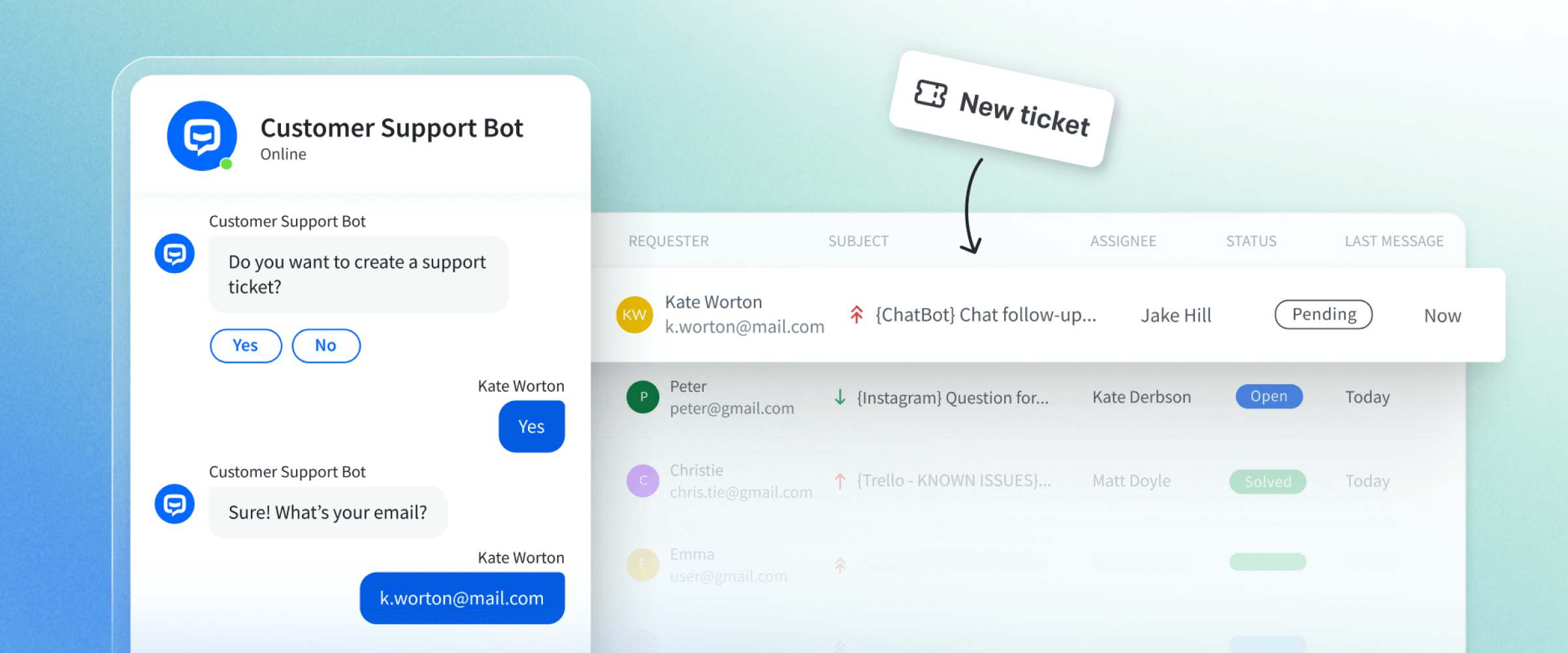
RPA 不会说话,于是第二阶段的 Chatbot 出现了。
它通过关键词匹配或预设的流程引导,能“理解”一些问题,并给出答案,广泛用于在线客服、电商平台、银行问询等场景。
但问题也很明显:一旦问题超出预设范围,它就会“卡壳”。没有真正理解能力,也不会执行动作,仍然只是一个“语言外壳”。
一句话总结:Chatbot 是“能说话的FAQ”,回答得了简单问题,但做不了真正的事。
大模型时代开启,智能体终于从“能说”跨越到“能做”。
LLM Agent 不仅能理解自然语言,还能调用插件、搜索知识、规划任务、执行操作,具备完整的“感知 + 推理 + 行动 + 记忆”能力。
一句话总结:LLM Agent 是“有大脑、有手脚、还能进化”的超级助手,是智能体的终极形态雏形。
RPA 是手,Chatbot 是嘴,LLM Agent 才是“手脑一体”的数字员工。
这就是智能体的发展路径,从“工具人”走向“代理人”,从“机械化”迈向“智能化”。
过去一年,越来越多具备任务执行能力的智能体开始落地,形态也在逐步丰富。
一方面,有一些围绕特定场景打造的成品型智能体已经上线使用;
另一方面,也有不少平台支持用户通过大模型、插件、知识库等模块,自定义搭建自己的 Agent。
整体来看,智能体正从以大模型为核心的技术组件,发展为一类具备感知、决策和行动能力的独立系统形态。
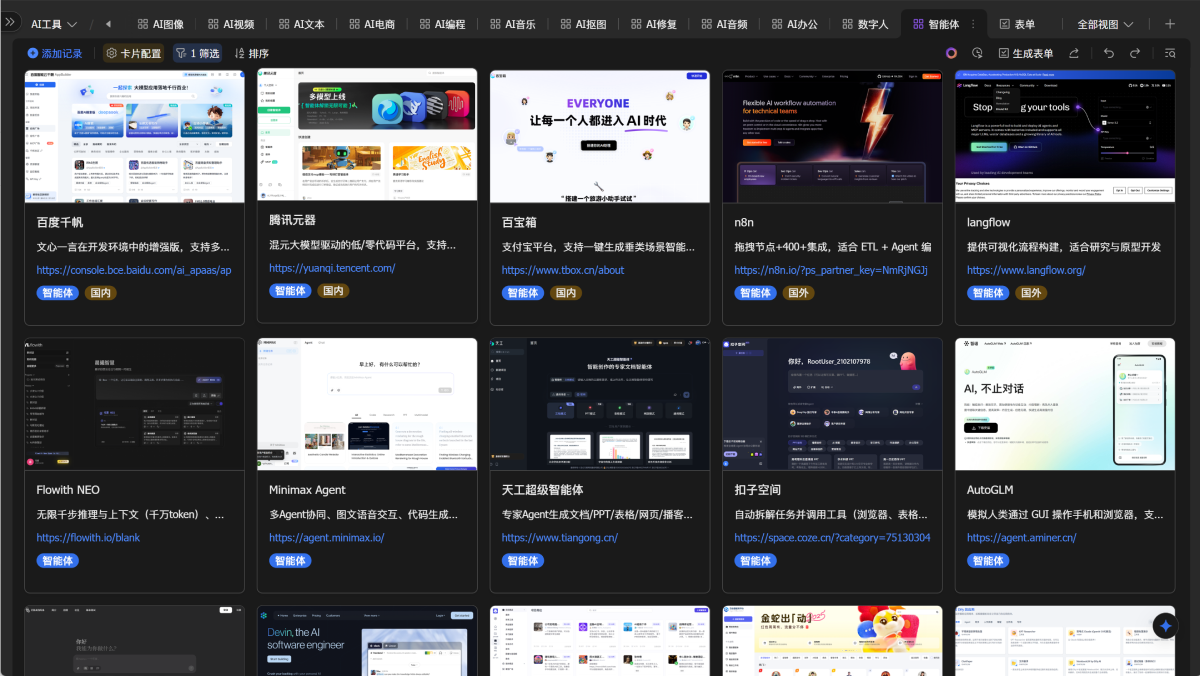
它们通常是由公司或平台直接推出的成品工具,具备清晰的功能边界和交付形式,比如写代码的 Devin、跑网页流程的 Manus、做品牌设计的 Lovart,用户只需登录就能直接使用,属于“开箱即用型智能体”。
这类平台提供了一整套构建框架和工具链,用户可以基于大模型、插件、知识库等模块,自定义开发自己的智能体。
像 Coze、Dify、Langflow 等平台,大幅降低了开发门槛,即使不写复杂代码,也能快速搭建并上线一款具备任务能力的 Agent。
我也给大家准备了一份智能体工具的表格,可以找我领取嗷!
智能体正在从技术概念,逐步变成可配置、可搭建、可调用的“AI 应用模板”。
它不一定完美,但目前是已经做到了“能用”,而且在快速迭代中,会变得越来越强。
很多人以为,AI 的尽头是一个超大参数的超级模型。
但从现实来看,大模型越大,能力越强,但也越“泛”。
真正有用的 AI,不是更大的 GPT,而是成千上万、专注于不同任务的智能体系统。
每个智能体,负责一个角色、解决一个问题,像细胞一样组成 AI 的“生态系统”。它们不需要通天彻地的通识模型,只需要明确的目标 + 精准的工具 + 可控的逻辑链,就能在真实场景中创造价值。
而能听懂你说话、记得你是谁、调用工具替你执行任务的智能体,正是这个时代最接近“答案”的技术路径。
看到这儿,你应该已经对“智能体(Agent)”有了初步了解。是不是也在想:
“现在这些智能体,到底靠不靠谱?在真实工作中,能不能真正帮我们提效?”
未来我会持续更新更多干货内容,包括实测教程、平台对比、搭建案例等,帮你一步步掌握智能体的真正能力。