AI 视频终于解决了过去最棘手的一件事:角色、物品、场景的一致性问题。
上传几张人物图,比如《武林外传》的白展堂、佟湘玉,再上传一张川子在某相馆拍摄的形象照,还有一碗肥肠面的图片。
输入提示词,描述想要的画面,AI 就能融合这些素材,生成一个完整的视频片段:
提示词:三人围坐在中式木桌前互相交谈着,桌上放着一碗热气腾腾的肥肠面。他们正在轻松地交谈着,场面自然幽默。
视频中的人物和场景融合的非常自然,并且人物的特征和服饰也很还原。
上传诸葛亮、关羽的剧照图,再上传一辆白色电动车的图像。
只需一句提示词,就能生成“丞相载关羽奔赴赤壁战场”的超现实画面,一切都按参考图来渲染,几乎没有跑偏。
提示词:诸葛亮骑着一辆白色电动车,关羽坐在后座,手持大刀。他们穿梭在赤壁战场中,电动车全景展现清晰,背景是火光中的江边,战船燃烧。
又或者是现代人物穿越古代战场,采访某位历史人物的“B站抽象文学”。
输入提示词,川子就成功来到赤壁战场见到了刘皇叔,从场景氛围到人物互动,都能精准融合。
提示词:赤壁战场上,现代男子,手持麦克风采访刘备,他们身上沾满了尘土和战火烟雾,背景是火光中的江边与燃烧的战船。
除了人物,你也可以上传动物图 + 场景图 + 装备图(比如卫衣、墨镜)。
输入一段提示词,就能让所有元素自然融合,指哪打哪。
提示词:一只黑色猩猩站在上海东方明珠塔前,穿着黄色运动卫衣,戴着黑色墨镜,手持手机自拍,笑容灿烂。
这就是 Vidu AI 最近上线的
Q1 参考生视频功能。
这个功能可以上传多张参考图像(人物、背景、道具、服装等元素),再配合一段提示词,AI 就能像搭积木一样将这些图像合成一个完整视频。
当前版本支持 5 秒的视频生成,初始生成就拥有 1080P 的清晰度,生成效果更逼真、细节更丰富。
并且它的操作非常简单,简单到我奶奶都会用,接下来我就带大家来玩下 Vidu AI 。
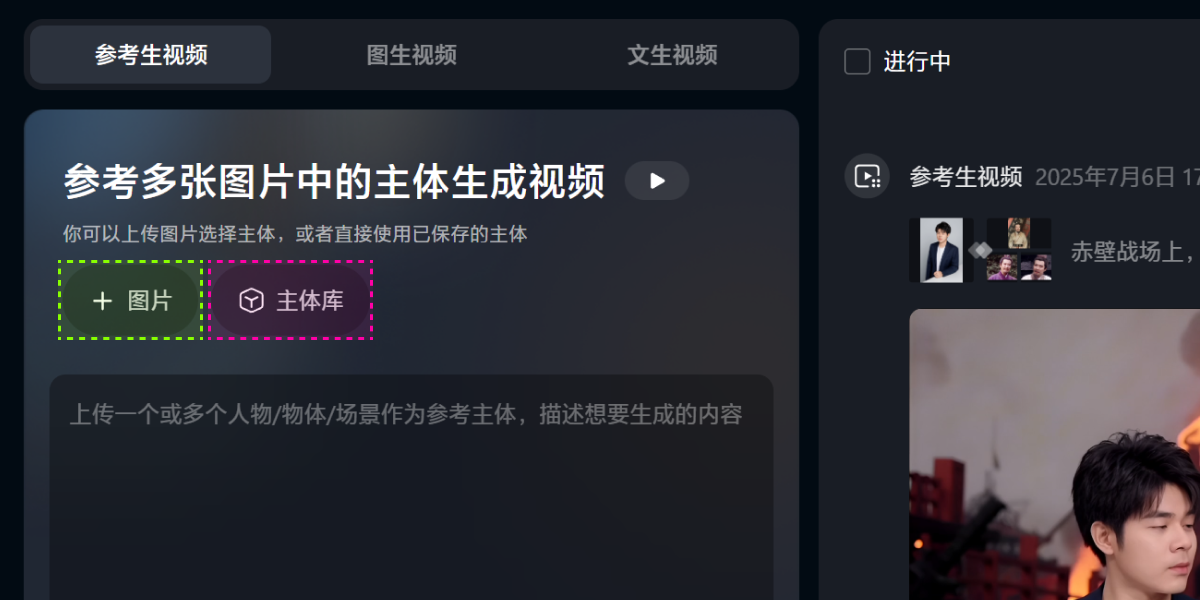
这里可以选择直接上传图片,或者是将多次复用的角色上传到主体库。
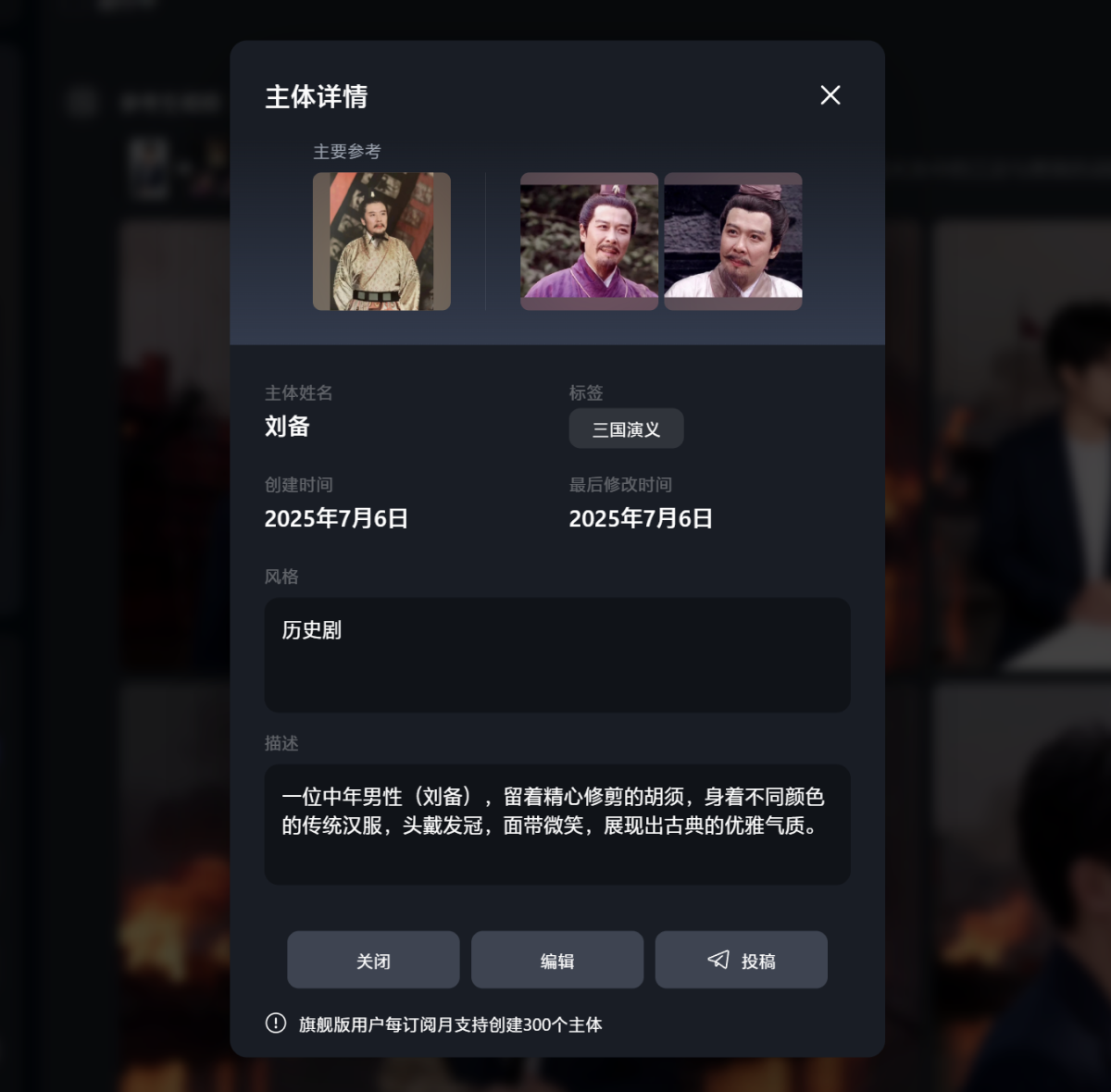
像刘备是我们后续会多次复用的角色,那么可以搭建一个刘备的角色主体。
这里需要注意图像素材的质量(禁模糊不清、干扰元素等)。如果有人物的多角度图片,那么在后续的视频生成中会更精准。
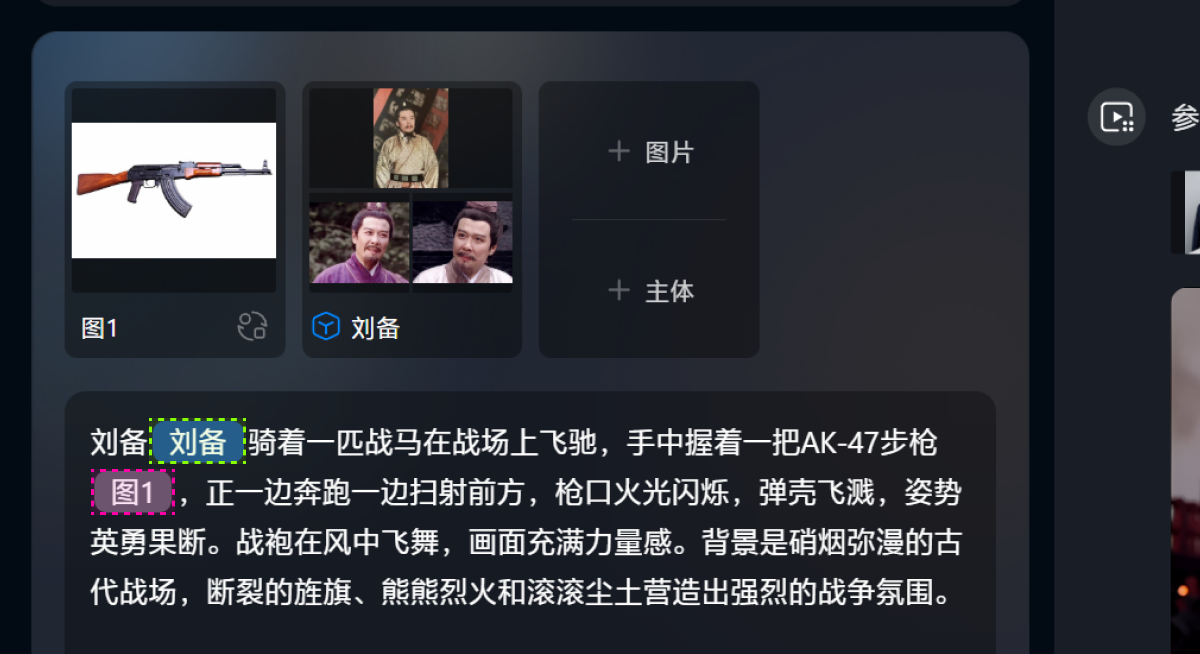
选择图片素材和主体素材后,就可以往下设置提示词,这里玩个抽象的案例。
提示词:刘备骑着一匹战马在战场上飞驰,手中握着一把AK-47步枪,正一边奔跑一边扫射前方,枪口火光闪烁,弹壳飞溅,姿势英勇果断。战袍在风中飞舞,画面充满力量感。背景是硝烟弥漫的古代战场,断裂的旌旗、熊熊烈火和滚滚尘土营造出强烈的战争氛围。
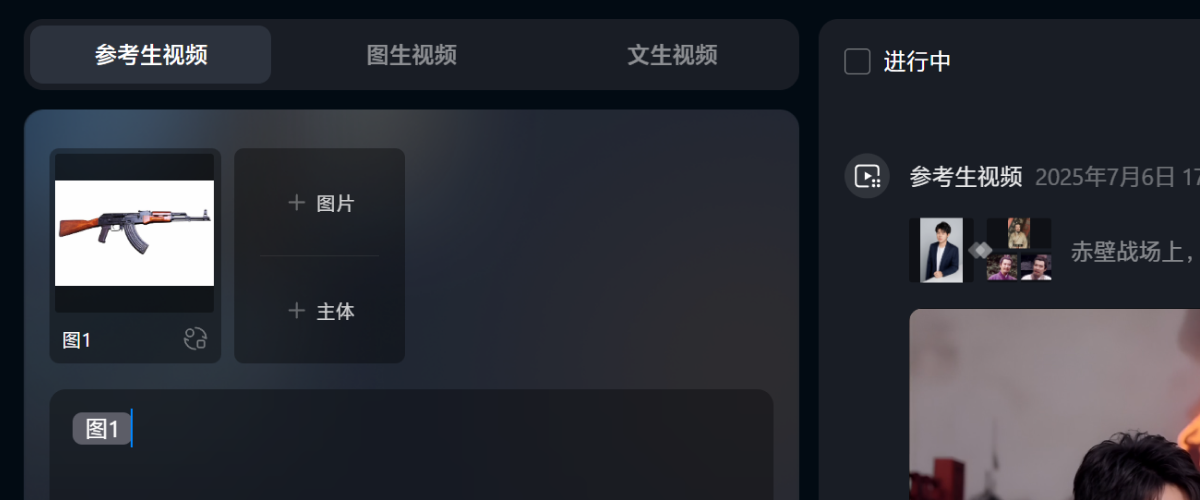
提示词部分还需要注意,把主体和图片拖到提示词对应的位置:
把 [刘备] 拖到第一句“刘备”提示词的后面,如此 AI 就会知道刘备是谁,长什么样。
把 [图1] 拖到第二句的步枪后面,AI 也就能知道这把步枪长什么样。
记得把模型设置成 Vidu Q1,其他参数可以根据自己的需求来设置。
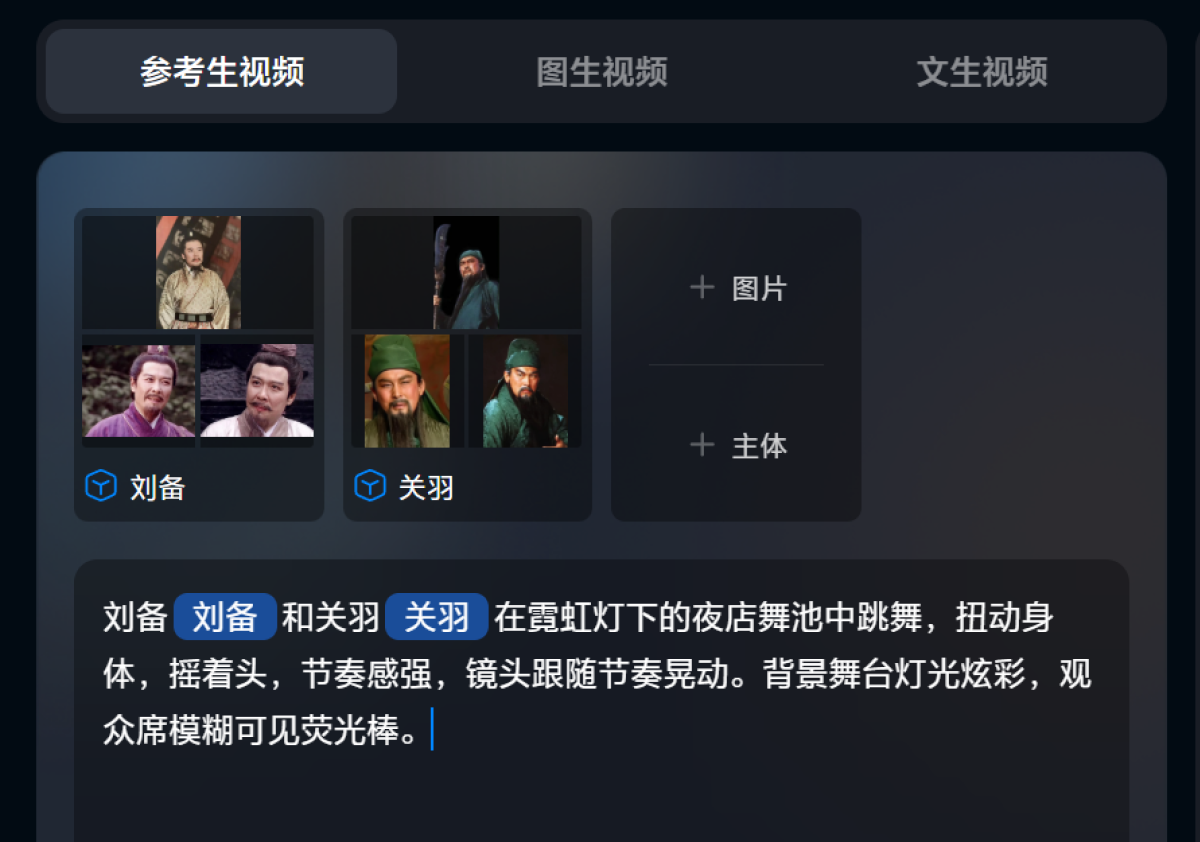
如果你觉得刘皇叔的表情太冷酷了,你还可以修改提示词,让他张嘴大笑。
提示词:刘备和关羽在霓虹灯下的夜店舞池中跳舞,扭动身体,摇着头,节奏感强,镜头跟随节奏晃动。背景舞台灯光炫彩,观众席模糊可见荧光棒。
这就是 Vidu Q1 模型的参考生视频功能。不管是在图像细节、人物还原、道具精度等方面都有质的飞跃,尤其是在“多主体一致性”上的表现。
只需要将人物图、场景图上传进去,并输入一段提示词,就能自动生成一段完整的、风格统一的视频镜头。
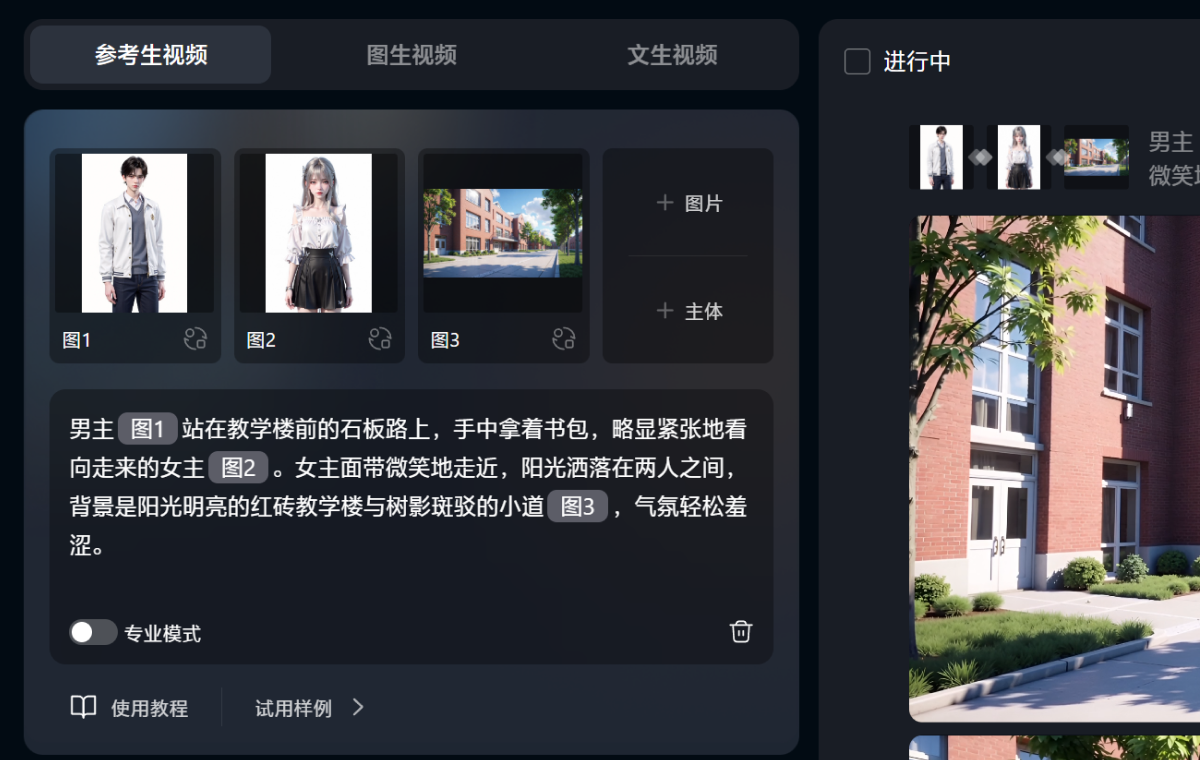
提示词:男主背着书站在教学楼前的石板路上,略显紧张地看向走来的女主。女主面带微笑地走近,阳光洒落在两人之间,背景是阳光明亮的红砖教学楼与树影斑驳的小道,气氛轻松羞涩。
视频提示词:女主坐在图书馆窗边看书,阳光洒落在书页上。男主站在一旁,略微俯身,轻声与她交谈。女主抬头回应,两人神情专注,背景是整齐的木质书架和温柔午后的光影。
视频提示词:黄昏的操场,男主和女主并排散步,脚步轻松,偶尔交谈,偶尔沉默。夕阳的余晖洒在他们身上,金色光线勾画出他们的身影,气氛宁静而温暖。背景是空旷的操场,远处篮球场上有些许声音,天空渐渐染上温柔的橙色,周围的一切都显得平静而美好。
视频提示词:空旷的教学楼走廊里,男主和女主对立站着,彼此相距不远。男主神情专注,缓缓伸出手,轻轻摸向女主的脸颊,眼神温柔却带着些许紧张,背景是静谧的走廊和明亮的灯光。
视频提示词:天台上,两人面对面站着,风轻轻吹起女主的发丝。男主将手中的信纸递给她,女主低头看着信,嘴角浮现微笑。背景是校区屋顶、远山与蓝天,气氛安静治愈。
最后我把所有视频分镜简单剪了一下,配了点BGM,效果取下:
如果说以前做广告要拍摄、搭建、调光、后期,那现在,用 AI 做广告,你只需要:
我尝试用 Vidu AI 做了三个不同风格的广告短片,全部都是用参考图合成的,来看看效果如何。
上传进 Vidu 后,只需一句提示词,便可快速融合成一段视频。
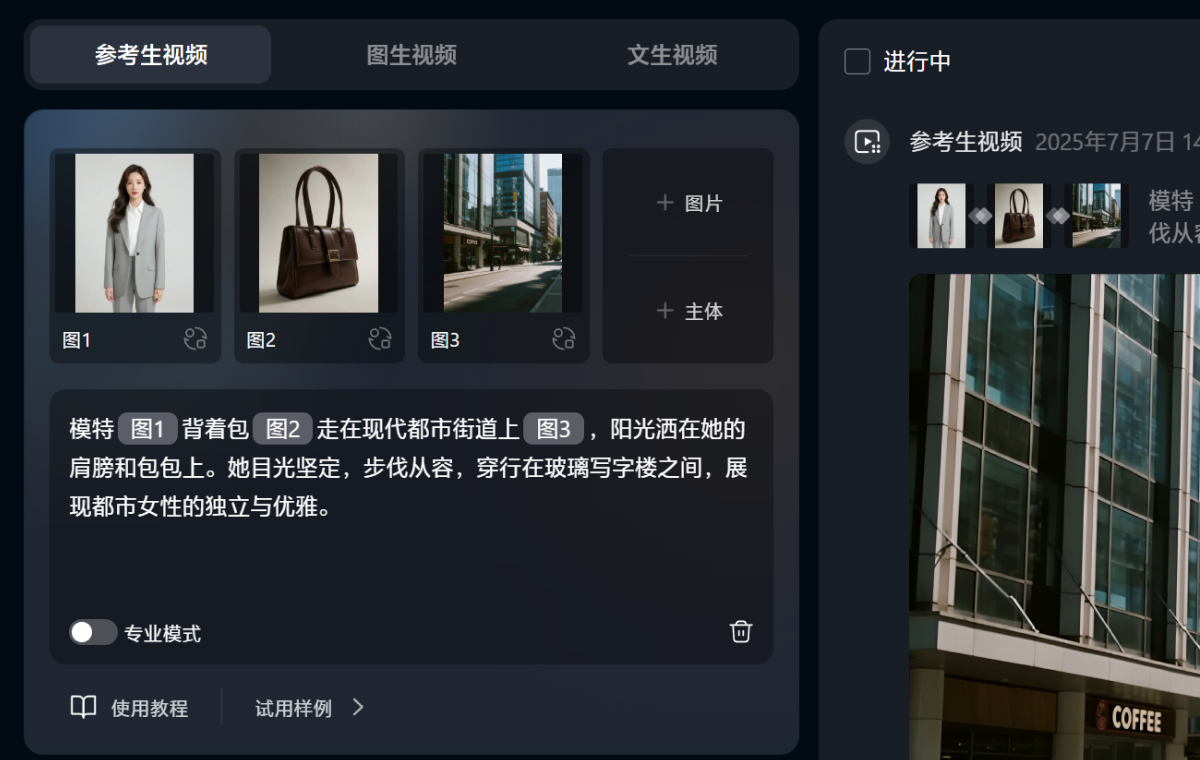
提示词:模特背着包走在现代都市街道上,阳光洒在她的肩膀和包包上。她目光坚定,步伐从容,穿行在玻璃写字楼之间,展现都市女性的独立与优雅。
上传图像后,重点是提示词对“模特动作 + 产品位置”的表达。
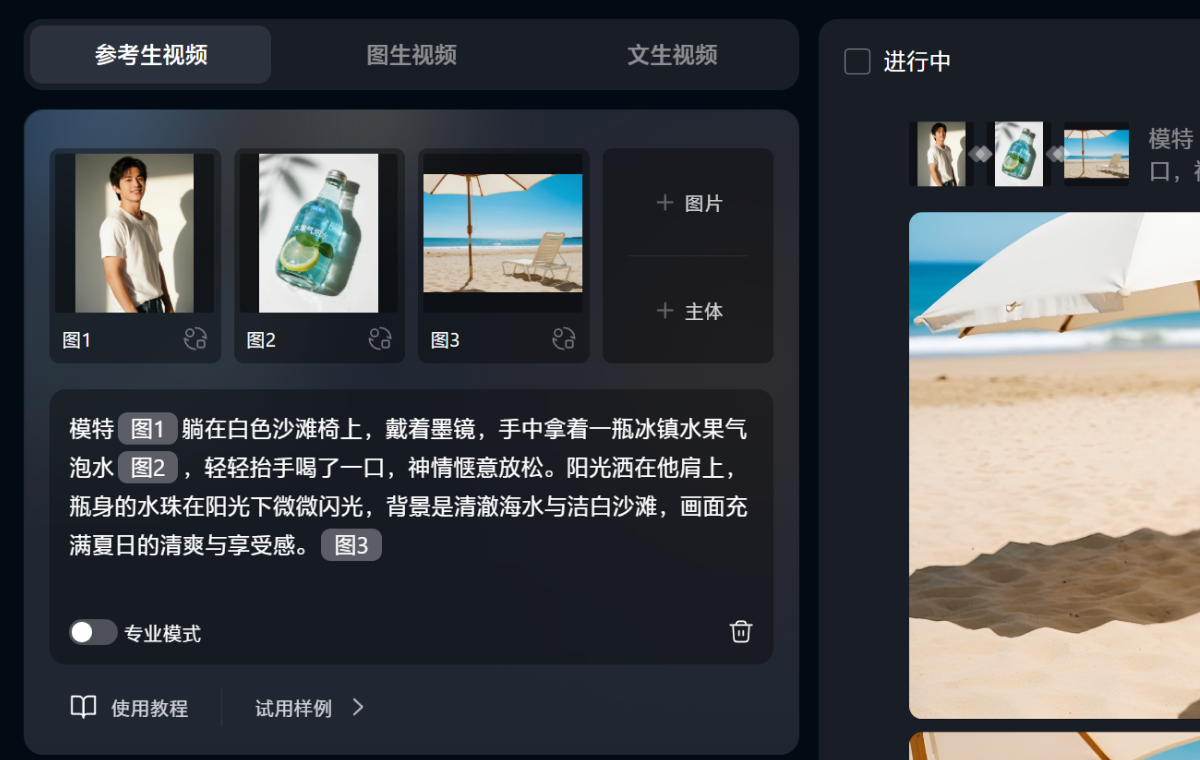
提示词:模特躺在白色沙滩椅上,戴着墨镜,手中拿着一瓶冰镇水果气泡水,轻轻抬手喝了一口,神情惬意放松。阳光洒在他肩上,瓶身的水珠在阳光下微微闪光,背景是清澈海水与洁白沙滩,画面充满夏日的清爽与享受感。
这次我们只用了两张图:产品图、场景图,做一个产品合成的效果。
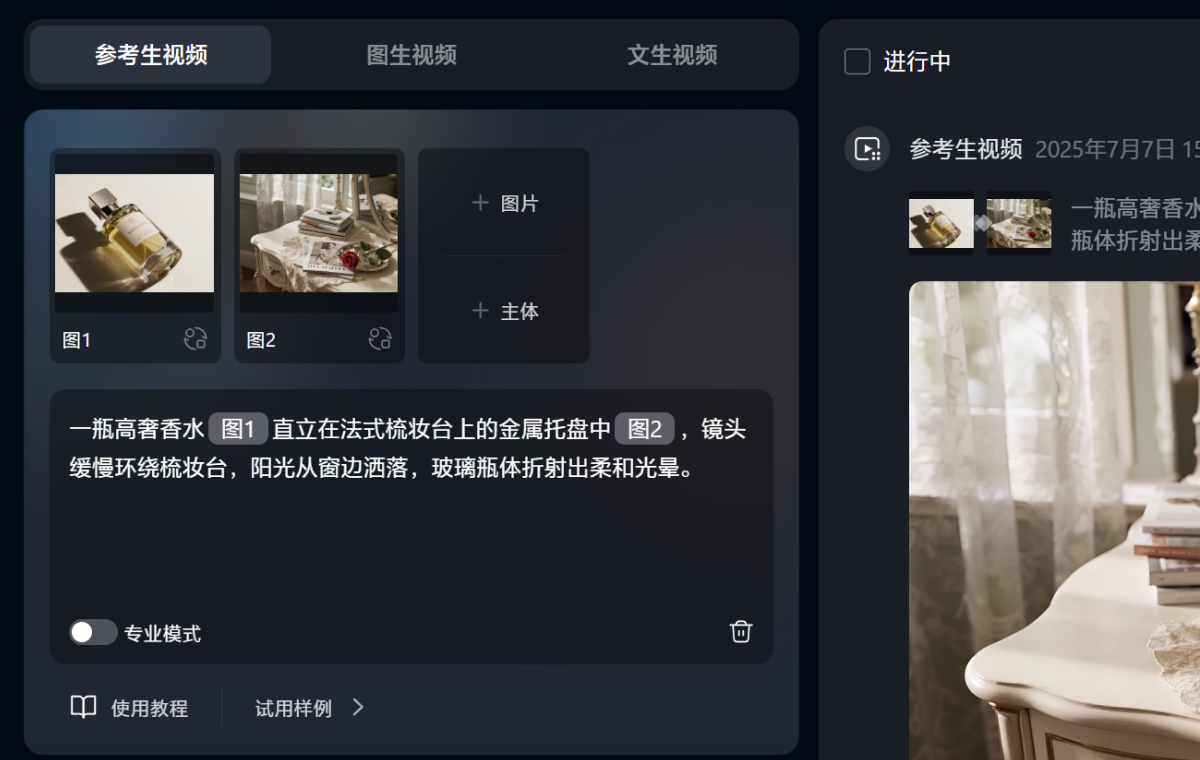
视频提示词:一瓶高奢香水直立在法式梳妆台上的金属托盘中,镜头环绕,阳光从窗边洒落,玻璃瓶体折射出柔和光晕。
以上就是本篇文章的全部内容,老规矩,来聊聊我的感受。
这一次,Vidu AI 真正把「AI 视频模型」从
炫技的“玩具”变成了创作者手中的“工具”
。
过去几年,我参加过不少 AI 视频创作比赛,也折腾过数十款 AI 视频工具。
这些工具大多能生成内容,却难以真正落地到创作流程中,最根本的问题只有一个:
缺乏精准控制。
否则花了时间调图、修图、补帧,反而更像在“为AI打工”。
图像生成领域的代表——GPT-4o、Flux Kontext 等模型,早已通过「参考图 + 提示词」解决了控图问题。
所以在那时的 AI 视频流中,我们通常会先在图像阶段把人物/场景/道具融合好,再喂给视频工具动起来。
但这种做法非常勉强 —— 动作生硬、崩坏频繁、细节断裂,几乎只能靠多抽多试碰运气。
而现在,Vidu Q1 参考生视频,直接复用了图像控图的成熟能力,
让视频也支持“参考图+提示词”这种高精准的生成方式。
只需上传几张图像,加上一句话,所有元素就能自然融合。
“You can't solve today's problems with yesterday's tools.”