Control Net最全教程|神器辅助生成精致绘图

AI工具介绍
简介
此扩展适用于Stable Diffusion web UI,允许 Web UI 将ControlNet添加到原始 Stable Diffusion 模型以生成图像。
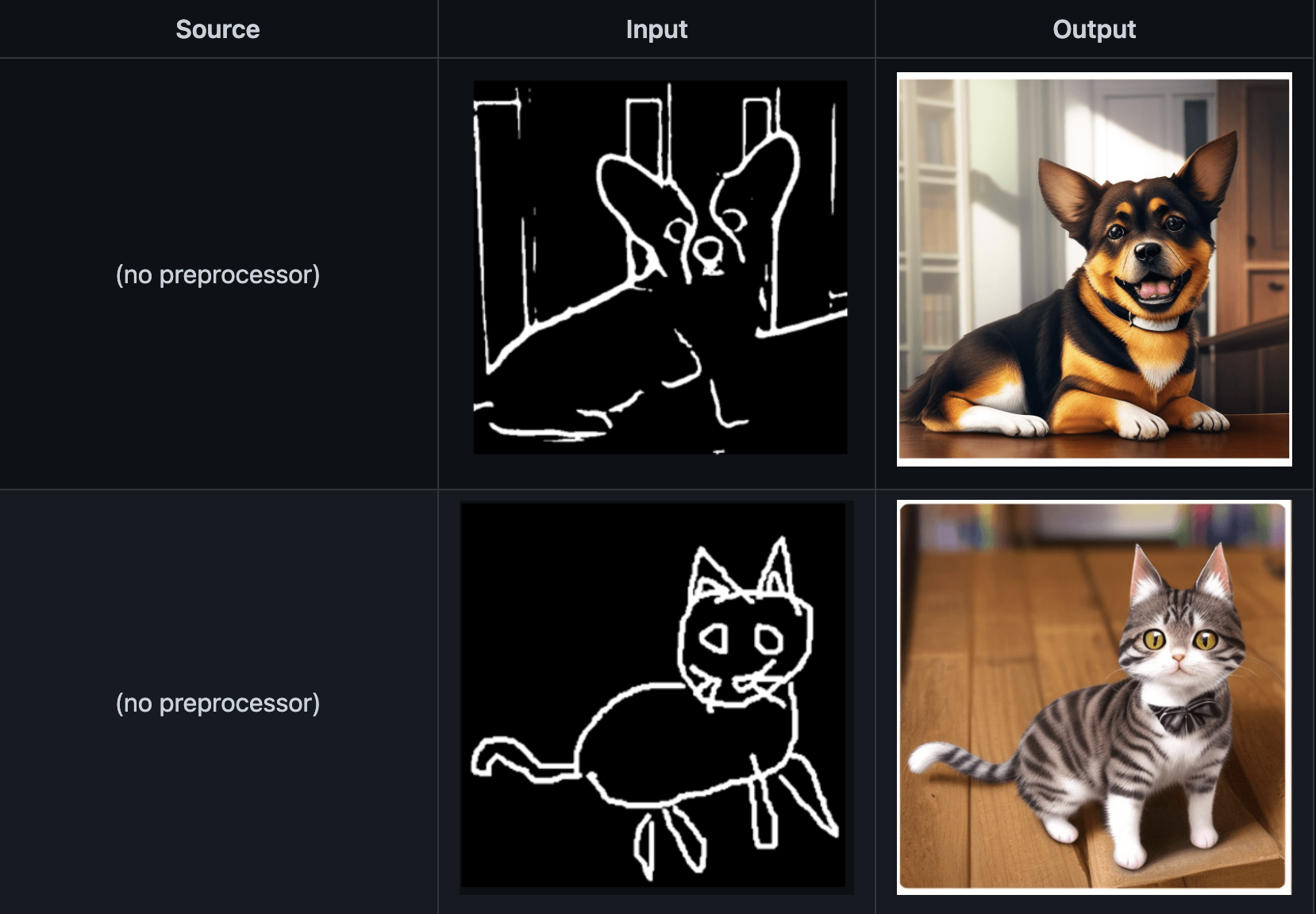
ControlNet 是一种通过添加额外条件来控制扩散模型的神经网络结构。可以通过上传线稿、色稿、人物姿势等参考图精准生产你所需的图片精度。

目录
一、下载安装
二、模型介绍
三、如何使用
四、初学者应用步骤
学完你将开启新大陆
一、下载安装
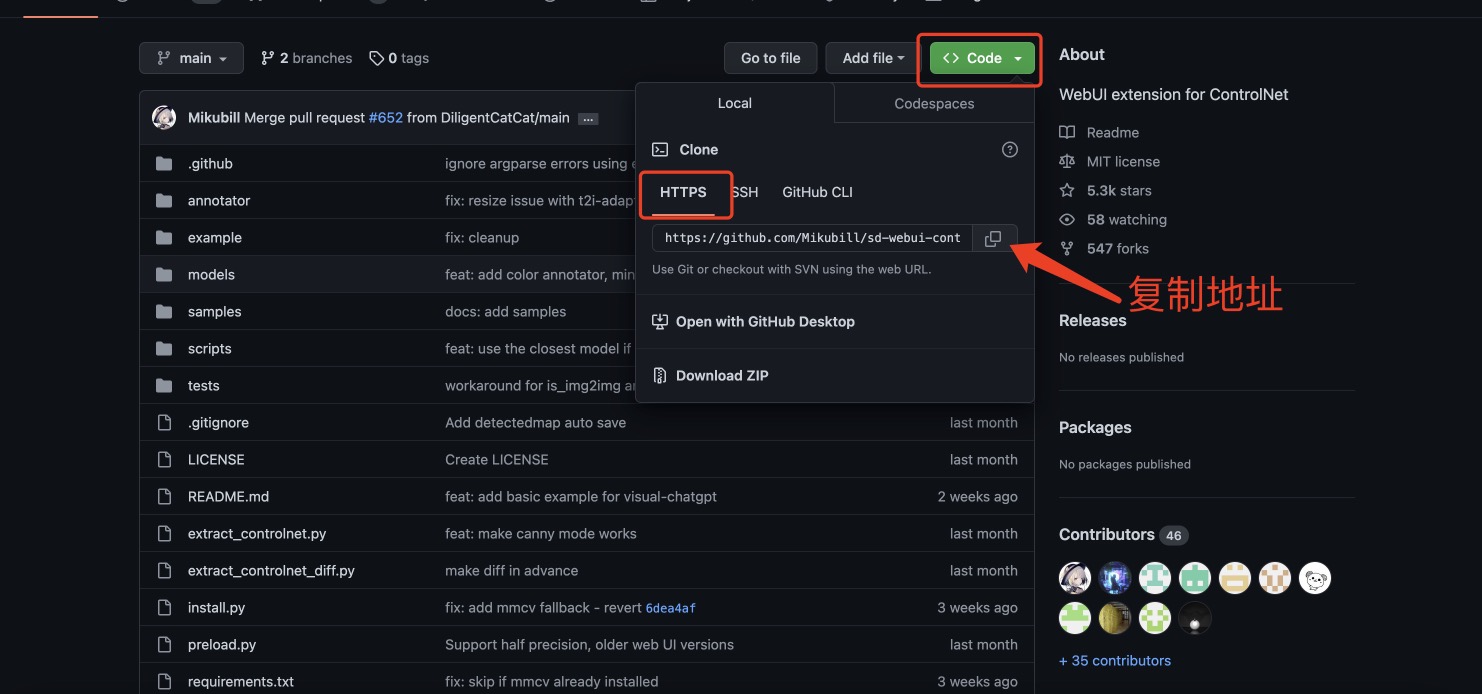
安装地址:https://github.com/Mikubill/sd-webui-controlnet
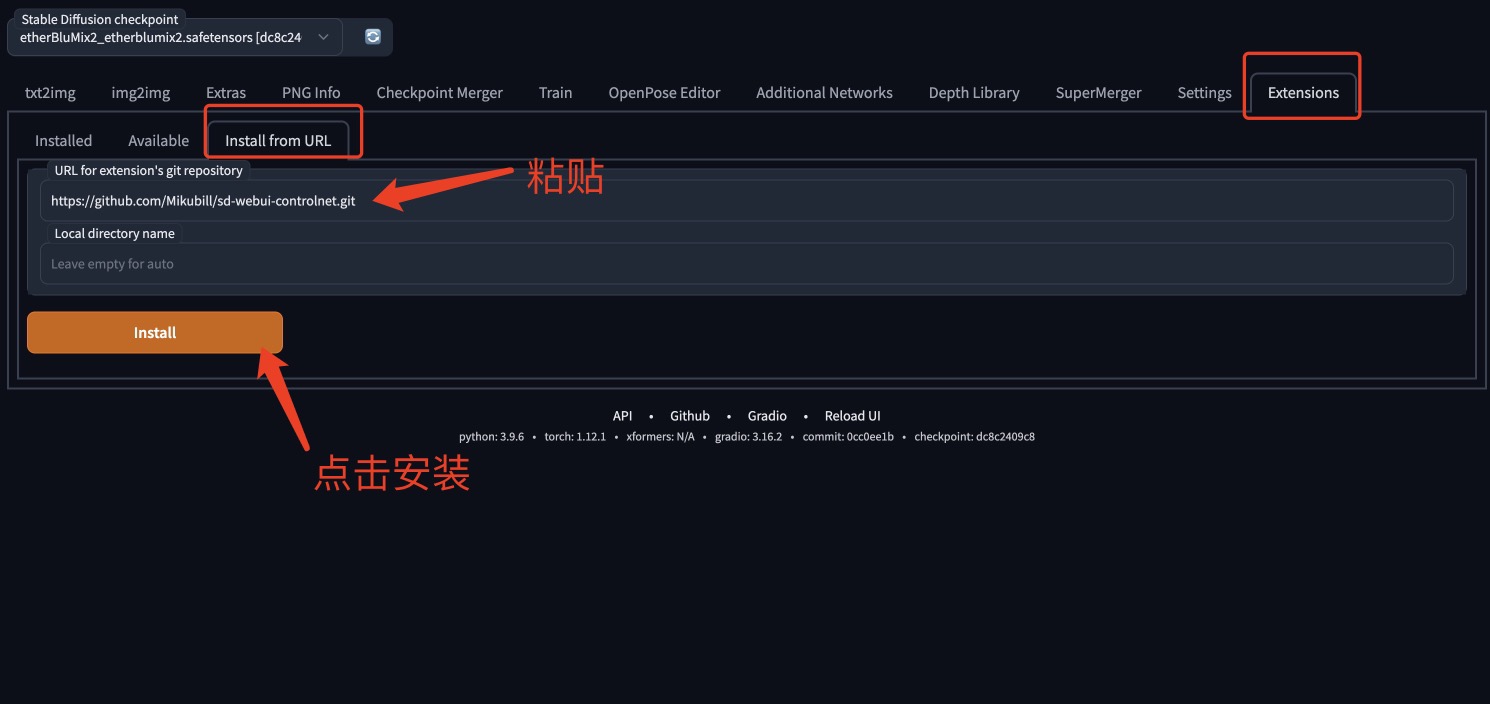
1、自动下载
按照下图步骤,下载后重启就会显示Control Net的插件
2.手动下载
下载安装包,手动安装到stable diffusion的指定文件夹内,重新启动应用即可看到操作面板。
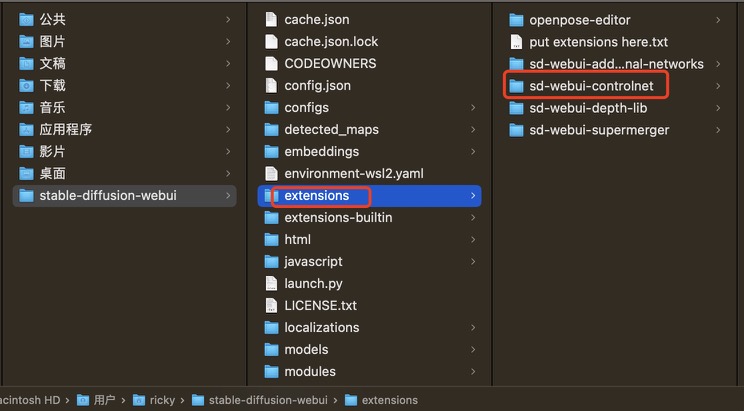
3.检测是否下载成功
下载文件存放在下图位置(自动下载可以在这个位置检查看是否下载成功)
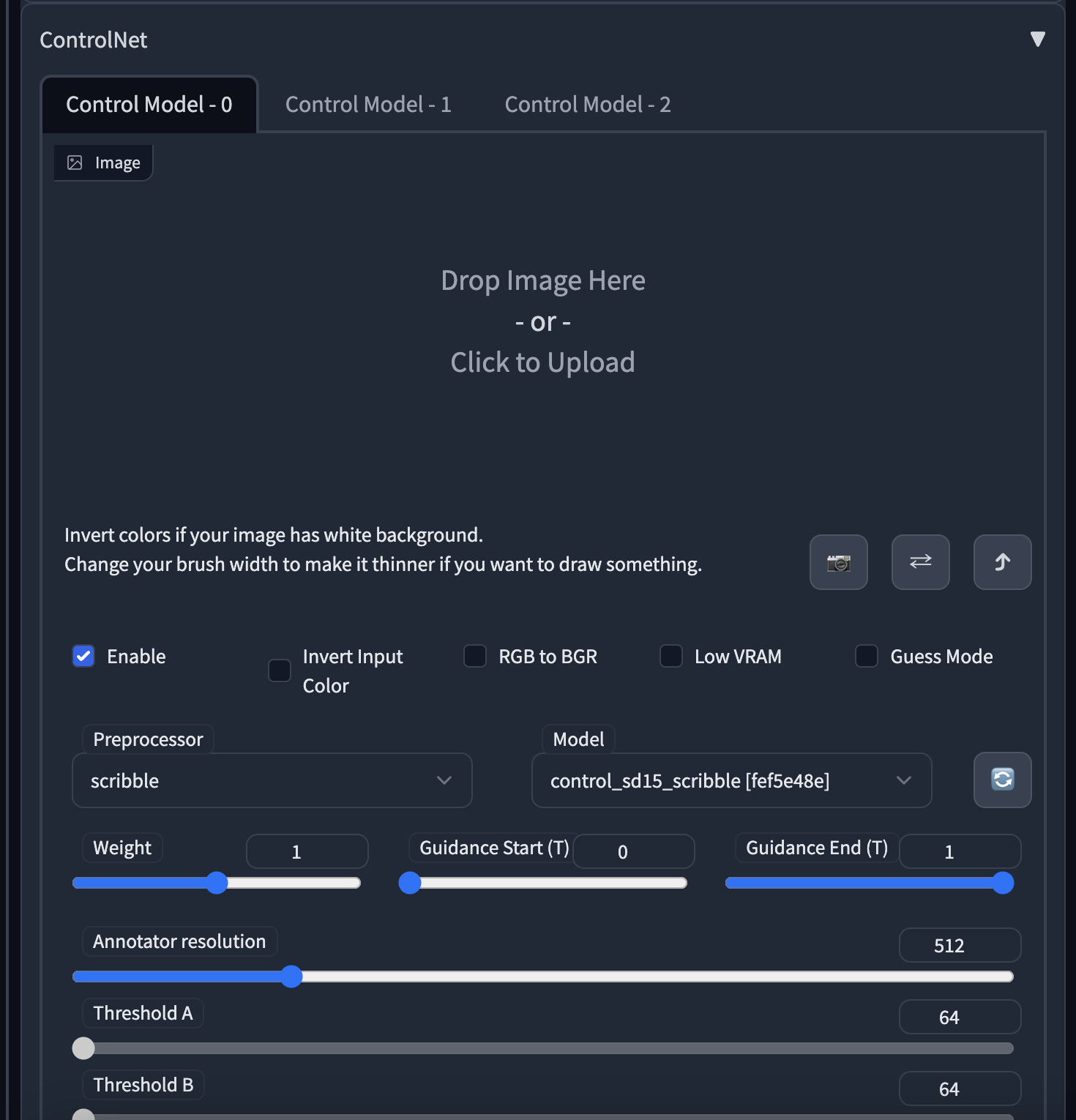
4.操作界面
img2img、txt2img板块下查看新增板块,该板块默认是收起状态,需要展开使用
二、模型介绍
ControlNet是需要专用模型的,否则无法使用相关功能引导图画。模型都比较大,可以按照自己需求去下载相关模型
下载地址:https://huggingface.co/lllyasviel/ControlNet/tree/main/models
1.Canny模型
主要是边缘检测,属于比较通用的模型,程序会对上传图片预加载出线稿图,之后再由AI对线稿进行精准绘制(细节复原能力强) 根据线稿精准绘制,可以放精致的线稿,进行生成

2.Hed模型
相比Canny自由发挥程度更高,以轮廓线为主

3.Scribble模型
涂鸦成图,比Canny自由发挥程度更高,以下为低权重成图

4.Seg模型
区块标注,适合潦草草图上色

5. Mlsd模型
建筑物线段识别,对于生成建筑有着细致的表现

6.Normal模型
适用于3维制图,用于法线贴图,立体效果
AI会提取用户输入的图片中3D物体的法线向量,以法线为参考绘制出新图,此图与原图的光影效果完全相同

7.Depth模型
该模型适合掌握图片内的复杂3维结构层次,并将其复现
它会从用户输入的参考图中提取深度图,再依据此重现画面的结构层次

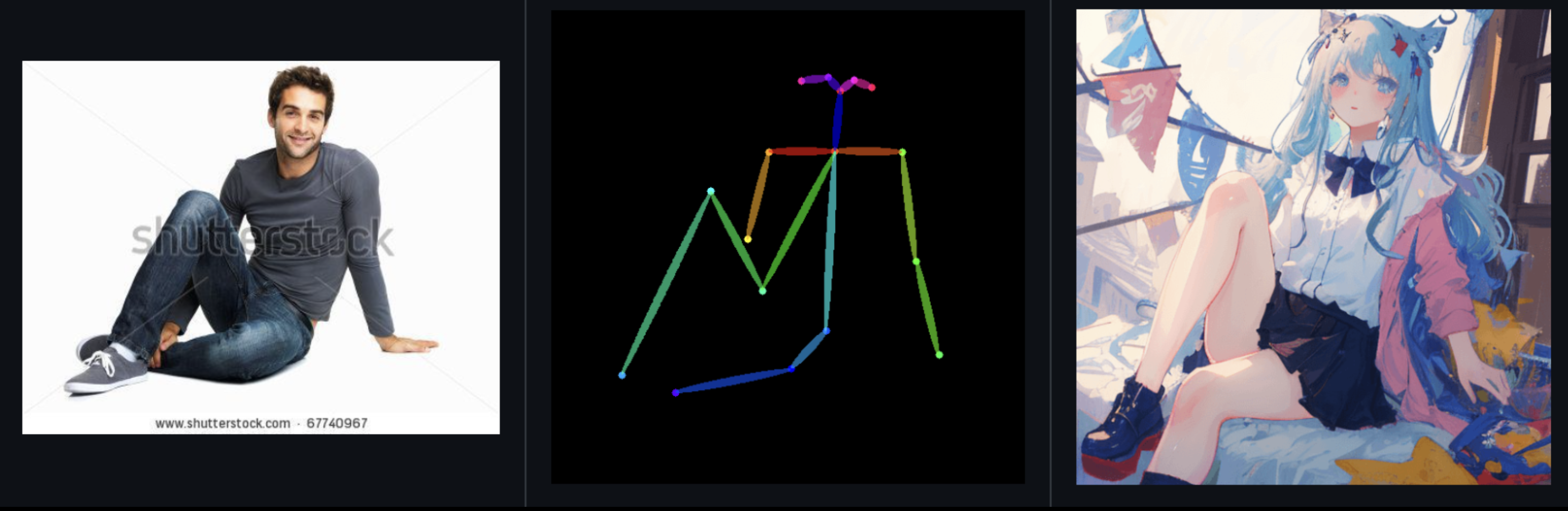
8、openpose
用户可以输入一张姿势图片(推荐使用真人图片)作为AI绘画的参考图,输入prompt后,之后AI就可以依据此生成一副相同姿势的图片;当然了,用户可以直接输入一张姿势图,如下图:
推荐可以设置姿态的插件:https://github.com/fkunn1326/openpose-editor
插件下载方式都是相同的 下载重新启动就会显示操作界面
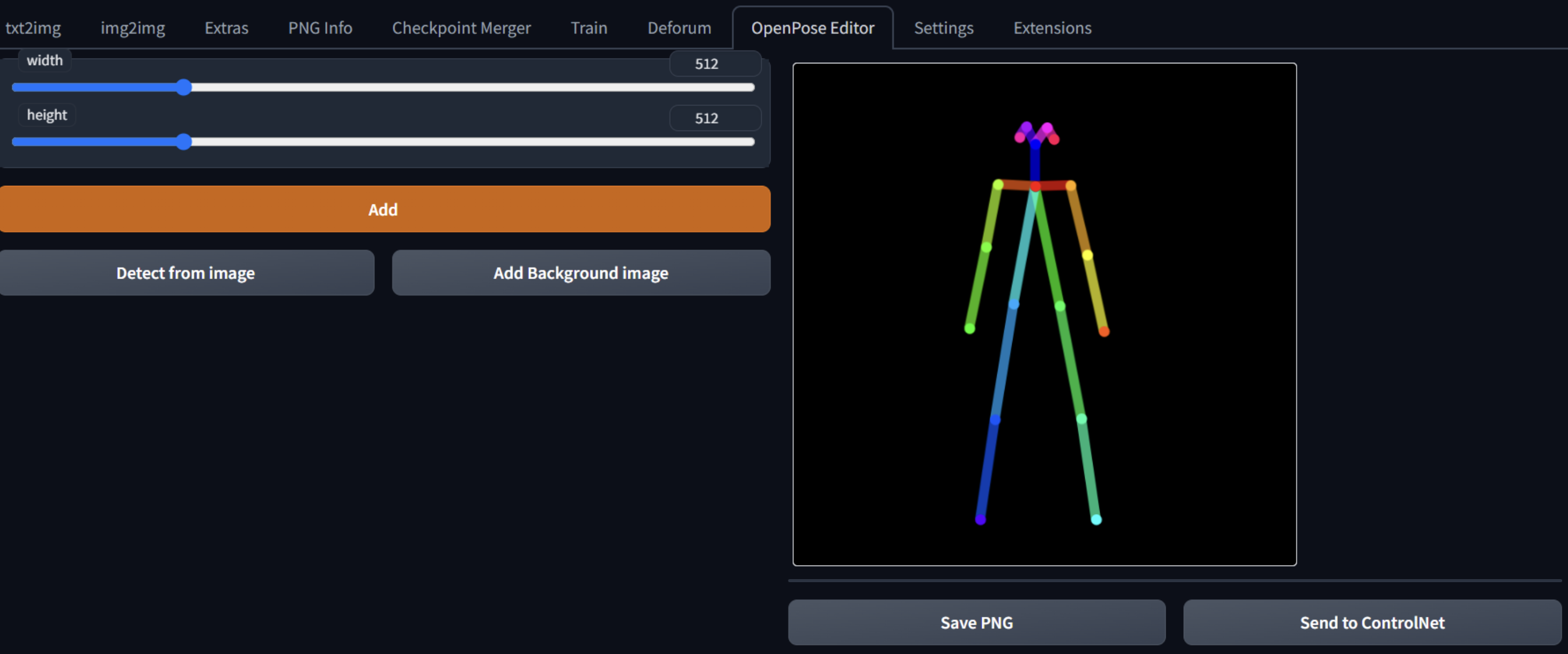
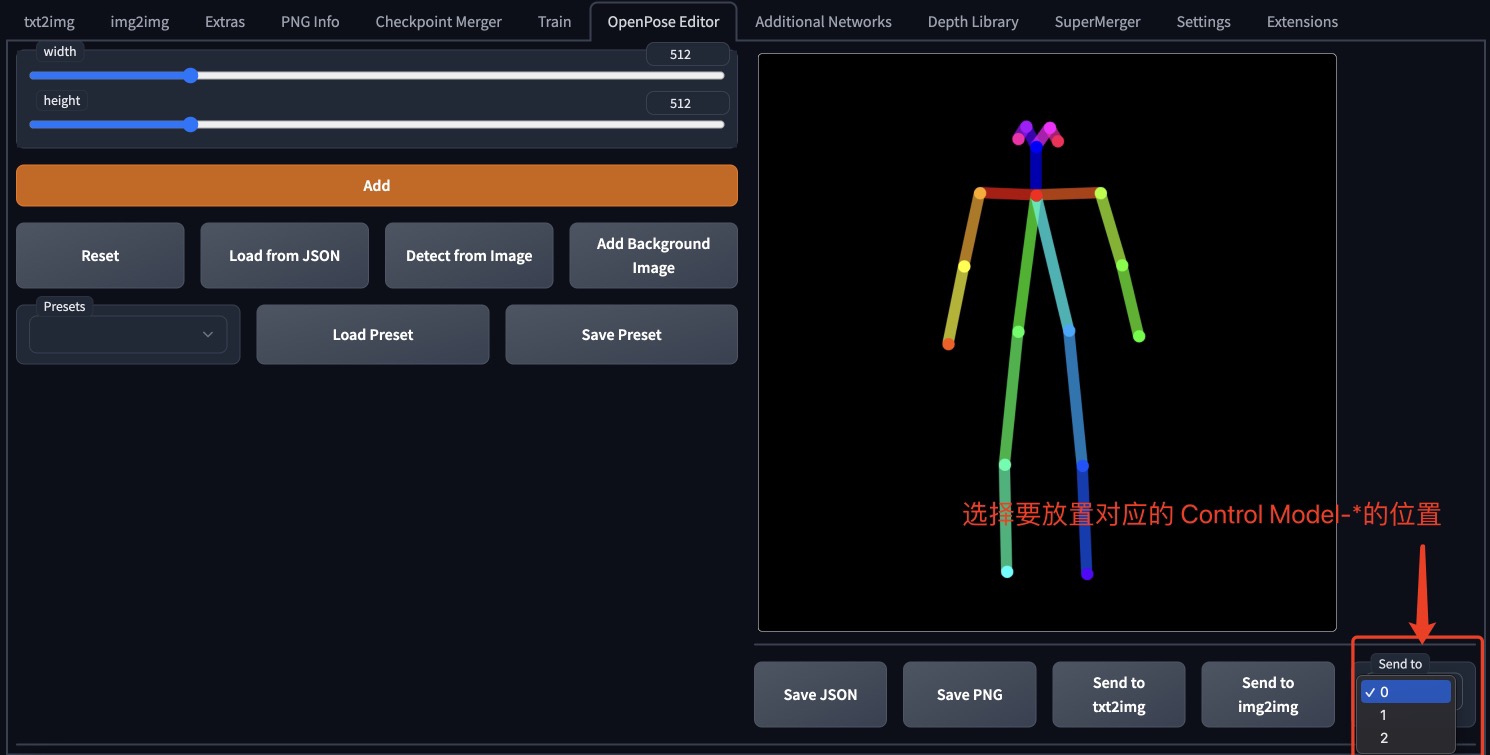
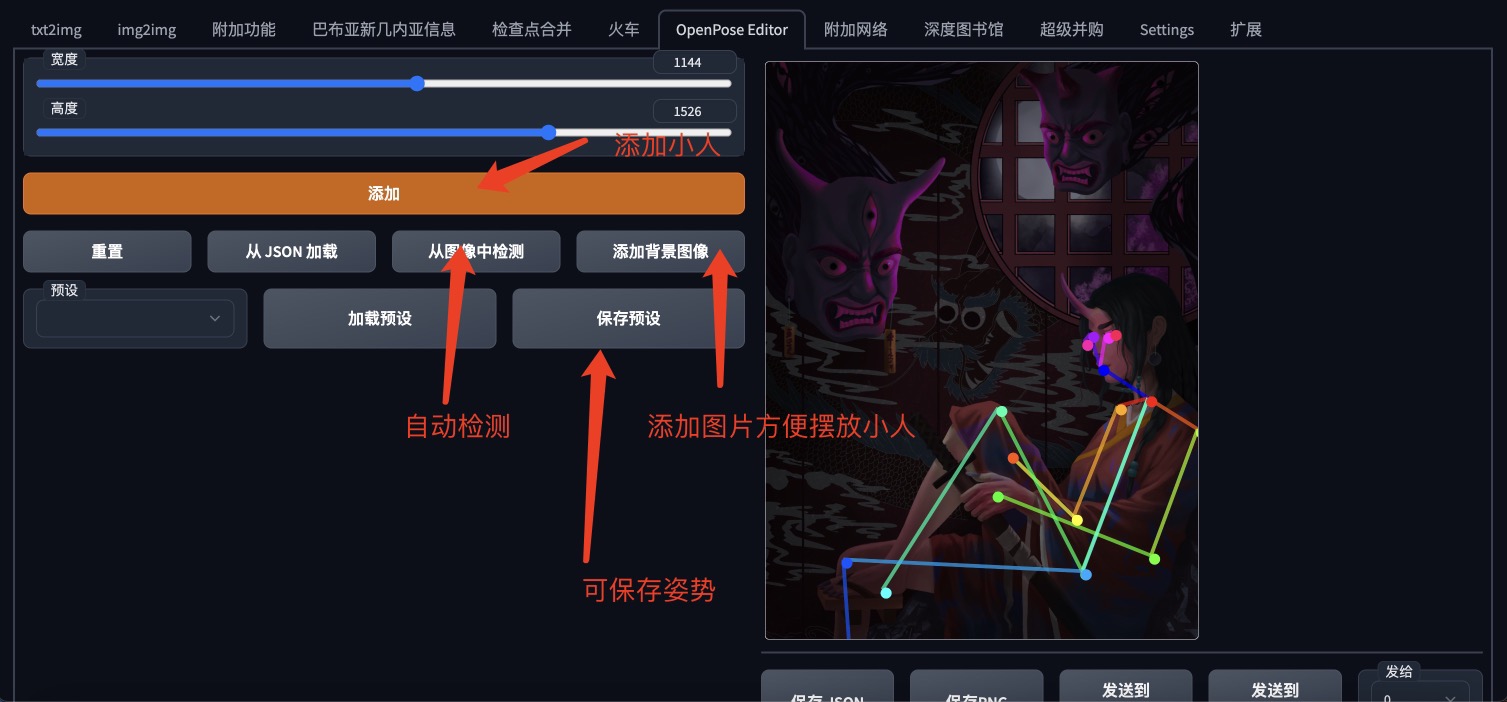
界面信息:
•“添加”:添加一个人
•“Detect from image”:从图像中检测姿势
•“添加背景图像”:添加背景
•“保存 PNG”:另存为 PNG
•“发送到 ControlNet”:如果安装了 Controlnet 扩展,则将图像发送给它
使用时:
不要给ConrtolNet 的 "Preprocessor" 选项指定任何值,请保持在none状态,摆放好姿势可以直接传送到Control
三、如何使用
1、基础功能
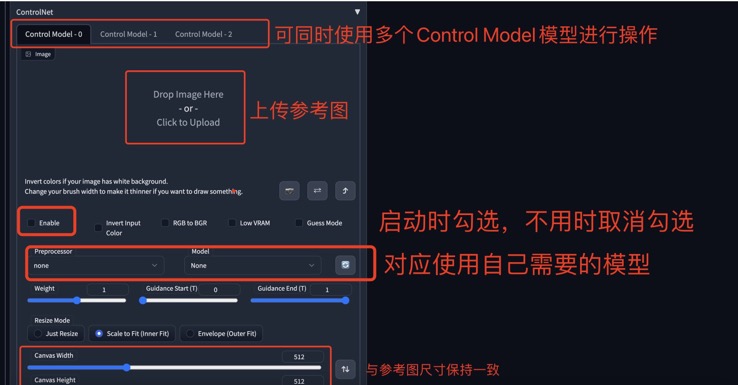
下载成功后此插件在txt2img、img2img中都可以使用,会多显示出来一个展开模块 根据自己所需,上传自己需要的图片,选择对应模型 关键词输入自己想要的状态,需要自己不断调试,Control的模型可以多尝试几个看哪个读取最精准
•不要忘记添加一些负面提示,ControlNet repo 中的默认负面提示是“longbody、lowres、bad anatomy、bad hands、missing fingers、extra digit、less digits、croped、worst quality、low quality”
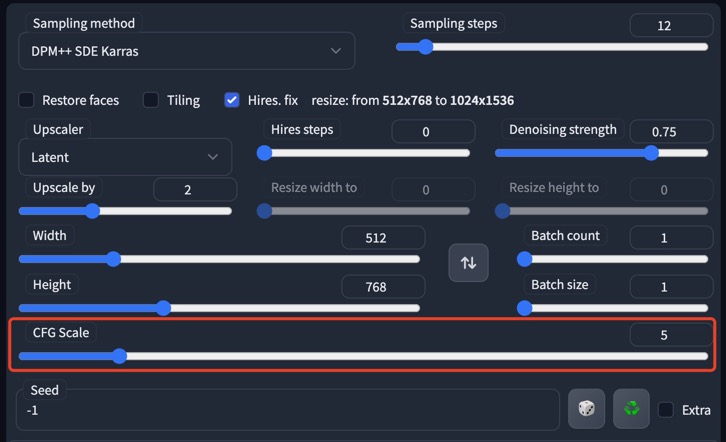
2、基于 CFG 的 ControlNet(实验性)
请注意,您需要使用较低的 cfg 比例/指导比例(例如 3-7)和适当的权重调整才能获得良好的结果。
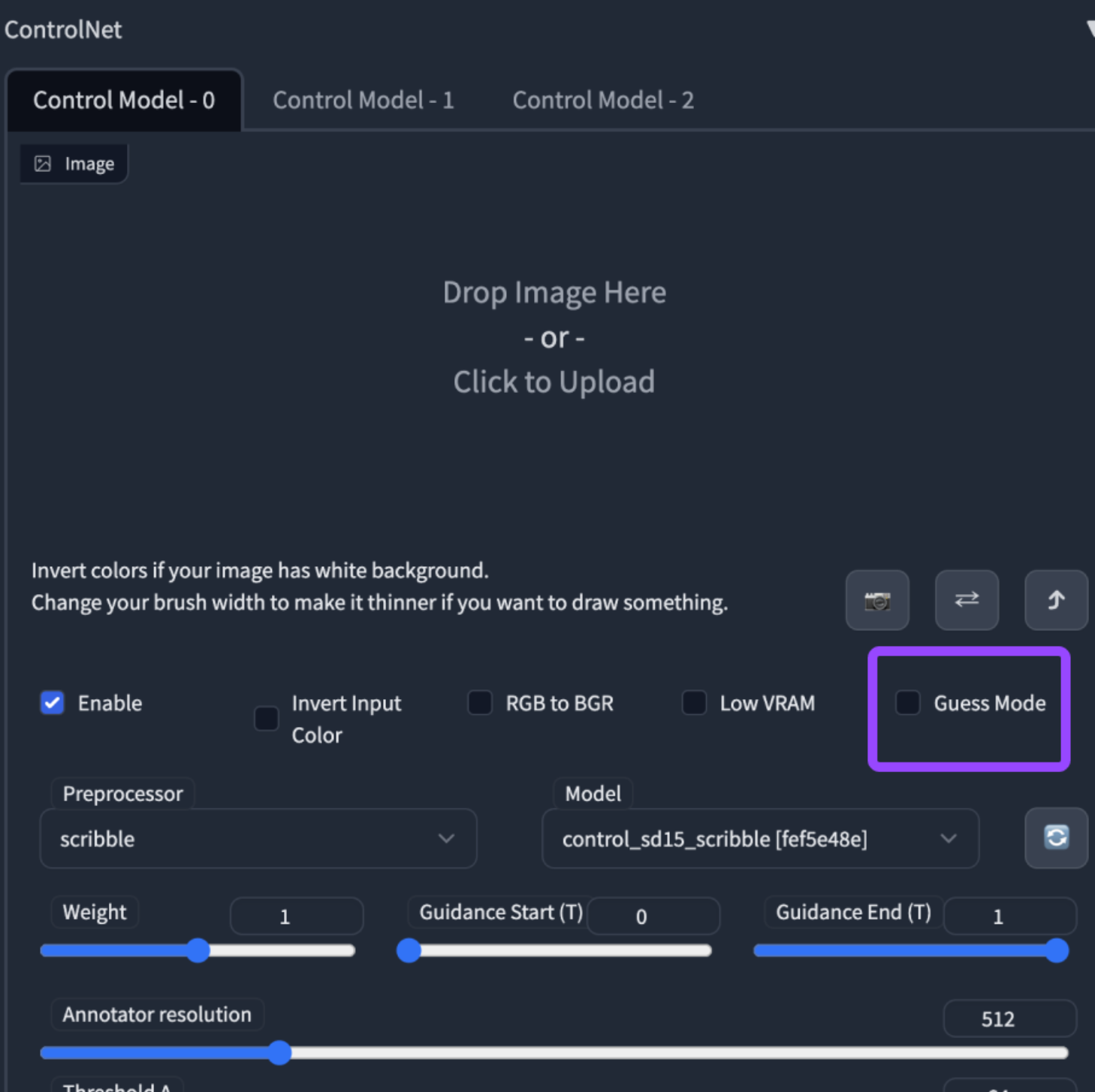
2、Guess Mode模式
Guess Mode是基于 CFG 的 ControlNet + 加权的指数衰减。
Guess Mode将完全释放非常强大的 ControlNet 编码器的所有功能。 在此模式下,您只需删除所有提示,然后 ControlNet 编码器将识别输入控制图的内容,如深度图、边缘图、涂鸦等。
这种模式非常适合比较不同的方法来控制稳定扩散,因为非提示生成任务比提示任务要困难得多。
在这种模式下,不同方法的性能将非常突出。 对于此模式,我们建议使用 50 步, 3 到 5 之间的比例。
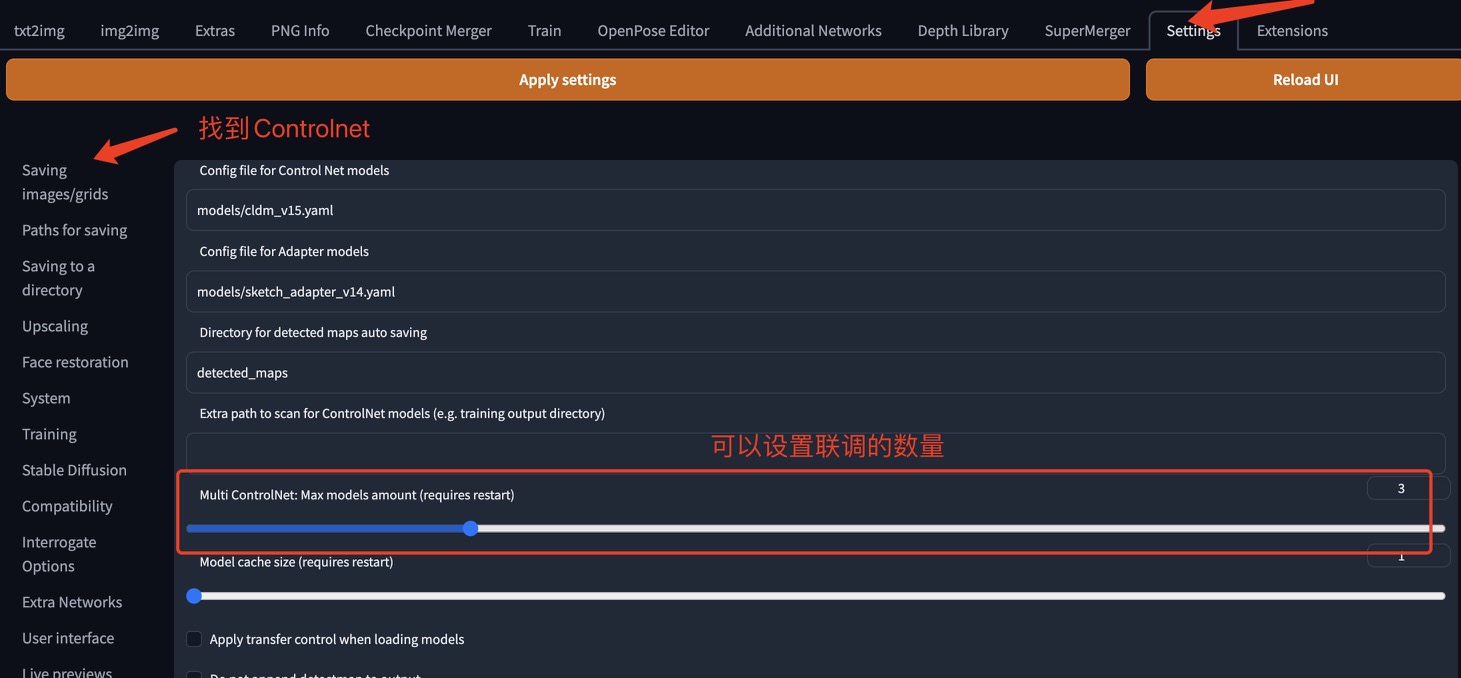
3、联合调节(实验)
此选项允许在单代中使用多个 ControlNet 输入。要启用此选项,请更改Multi ControlNet: Max models amount (requires restart)设置。请注意,您需要重新启动 WebUI 才能使更改生效。
•如果启用了其中任何一个,猜测模式将应用于所有 ControlNet。
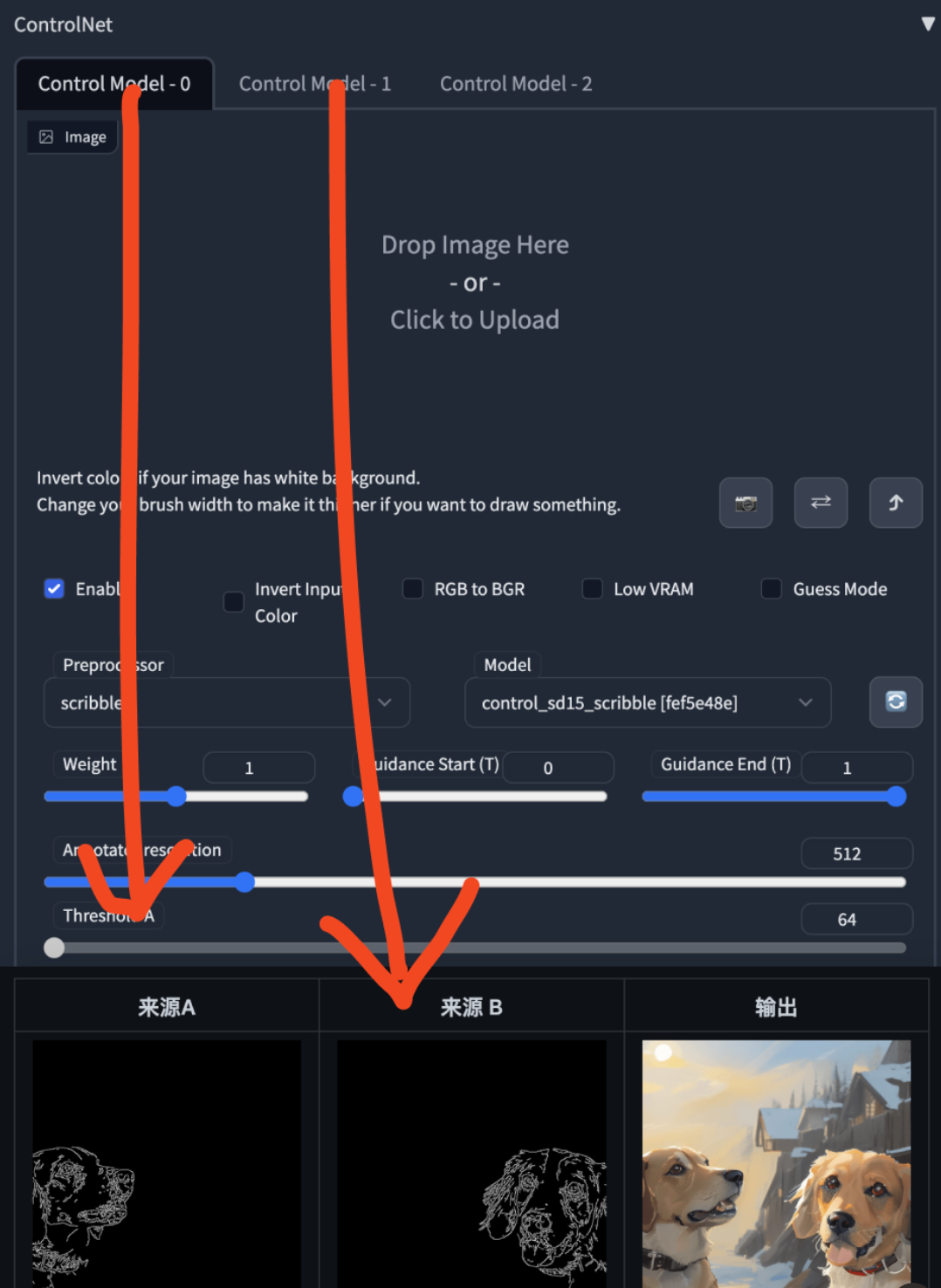
四、初学者应用步骤
第一步:
我把源照片复制到 img2img,并启用了controlnet,你可以复制下面的设置,但要确保将分辨率设置正确。
使用 SD1.5 或更早的版本,一般是使用较小的分辨率512,其他的根据你的想法来配置。
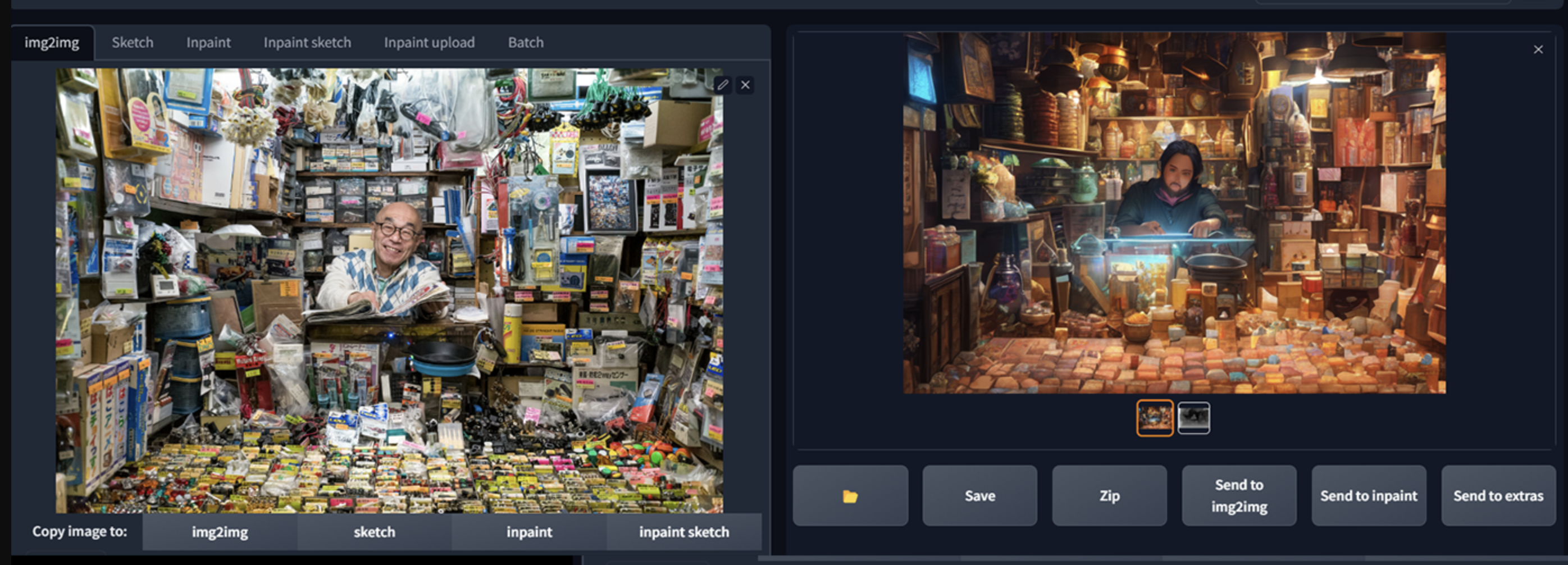
在笔画强度上留有余地,试图保留原作中的一些色彩,但并不是很大。
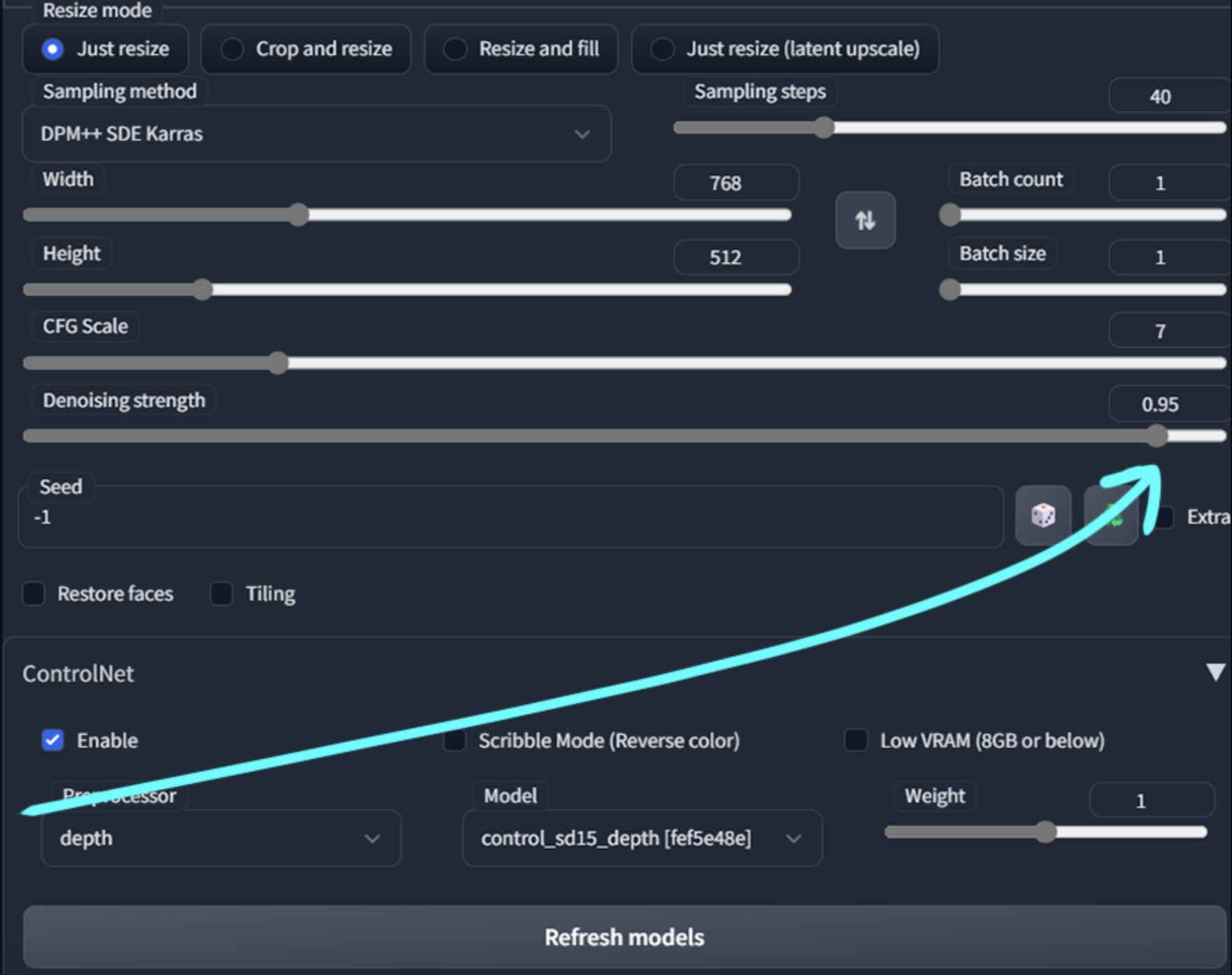
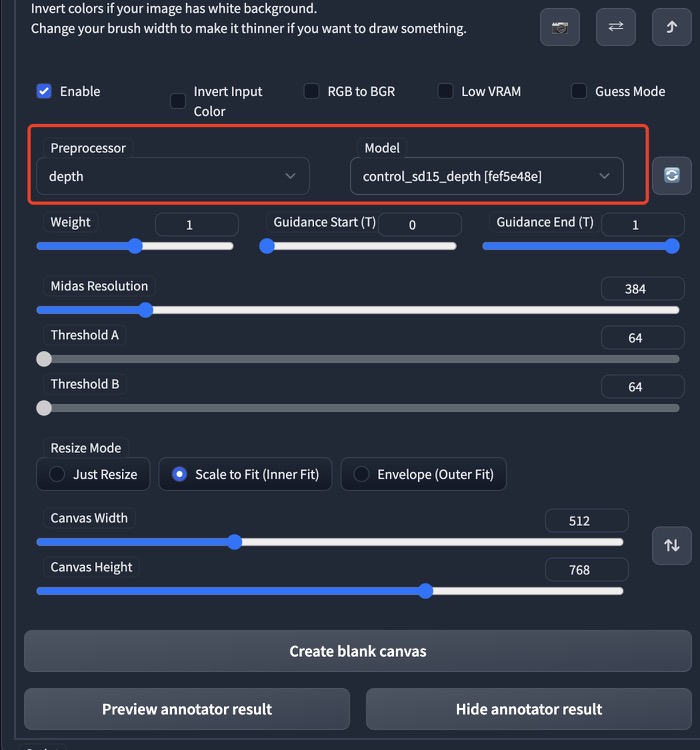
使用的是深度模型(depth)

第二步:
现在我们需要更多的细节,所以我把分辨率提高了一倍,这很简单,只要把较小的值(512x2 ,1024)提高一倍,然后与剩余的值相匹配,这样长宽比就会保持不变。 另一件事是我改变了以前的做法,那就是笔画强度。
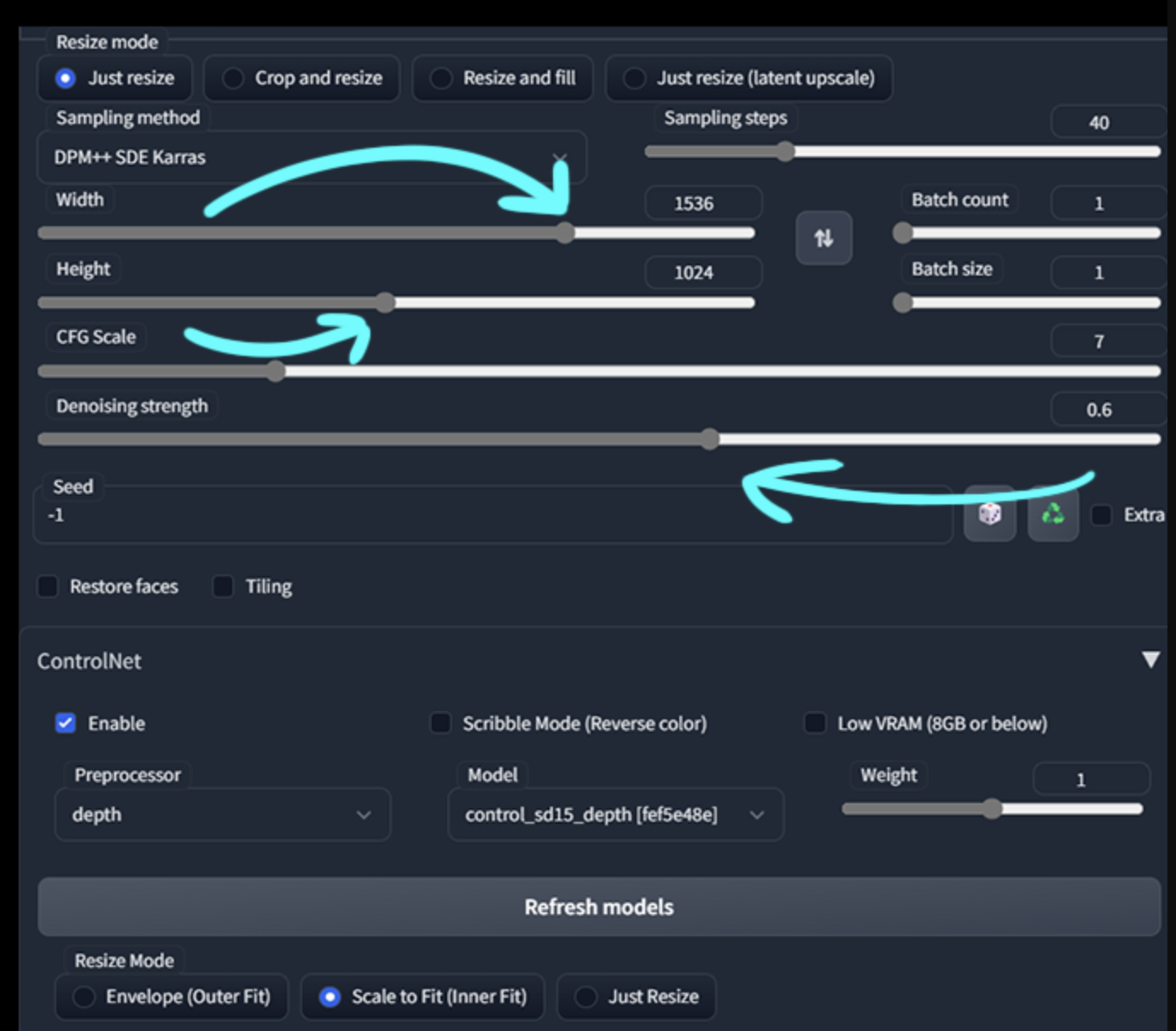

第三步:
在重新绘制了一个我满意的高分辨率版本后,我们导入到 inpainting,并开始逐个修复画面,我从人物开始。 下面是关于 inpainting 的提示,别忘了现在就禁用controlnet!。
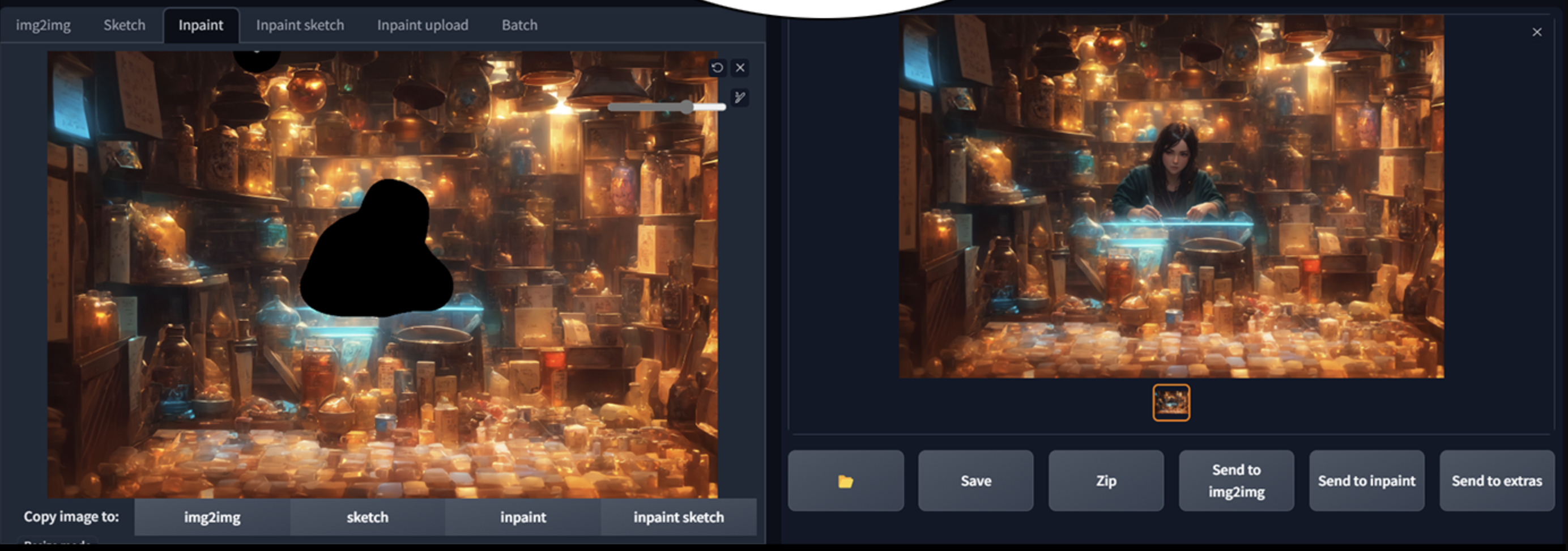
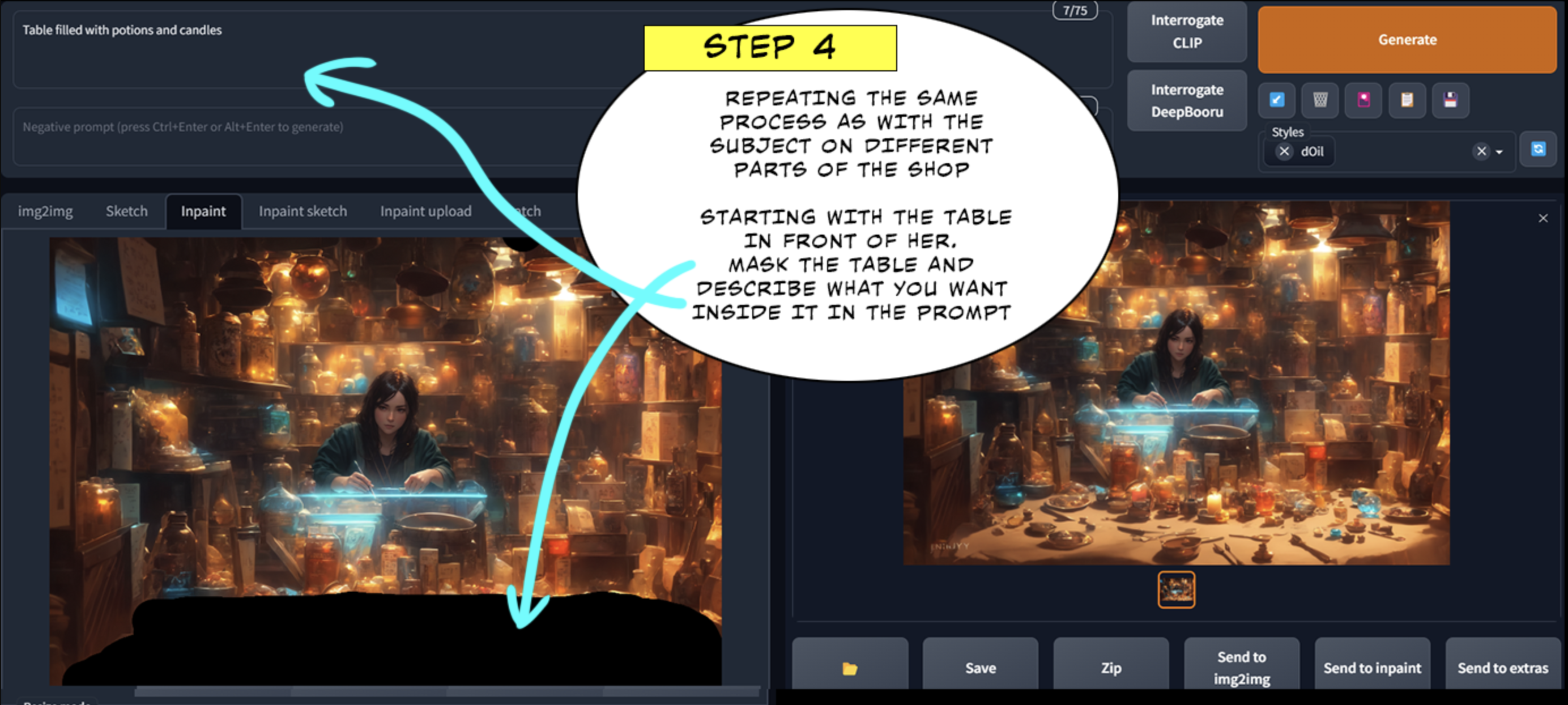
第四步:
在商店的不同地方重复与主体相同的过程。 从她面前的桌子开始。遮住桌子,在提示中写下你想要的东西。
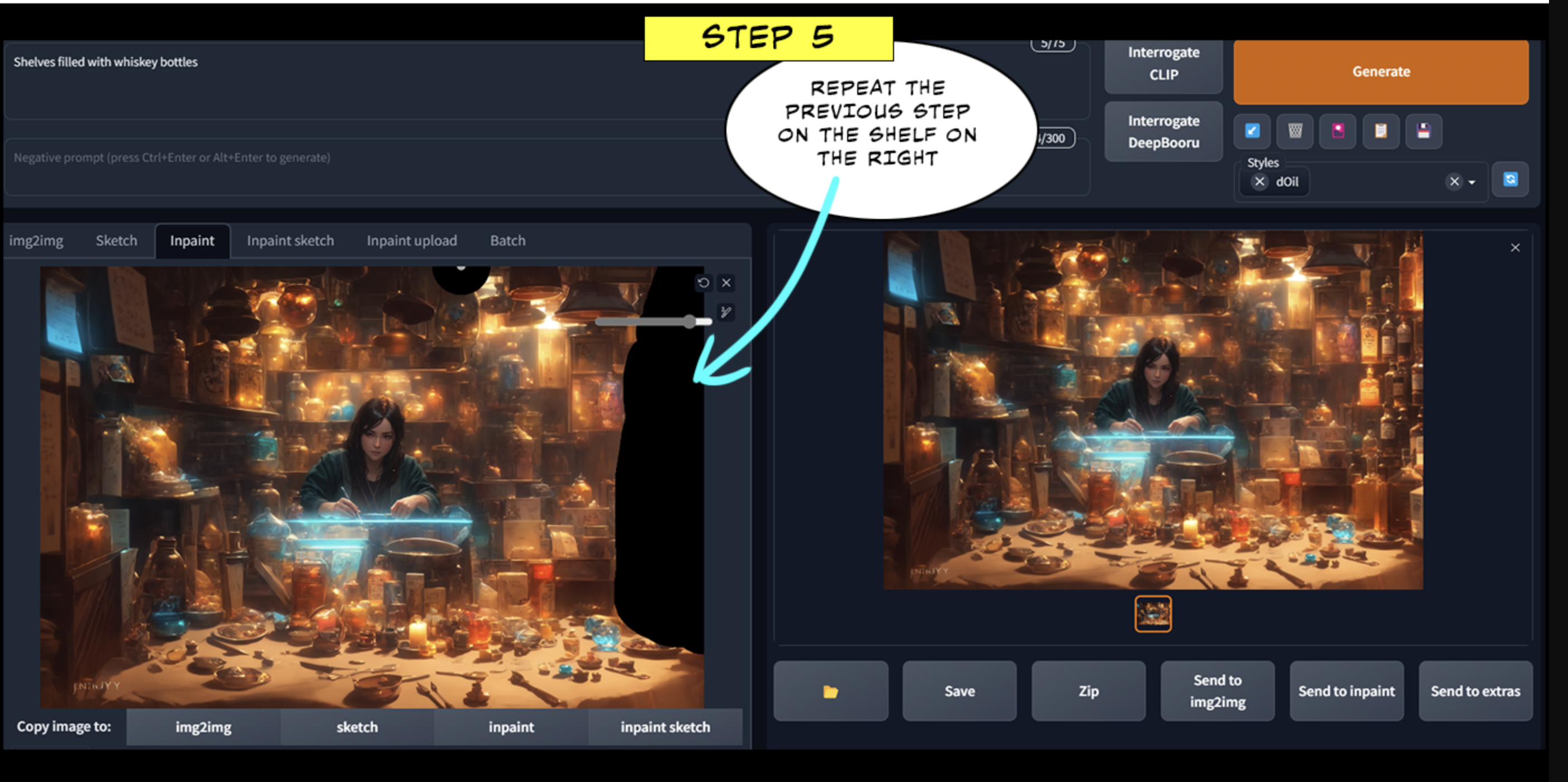
第五步:
在右边的架子上重复前一个步骤。
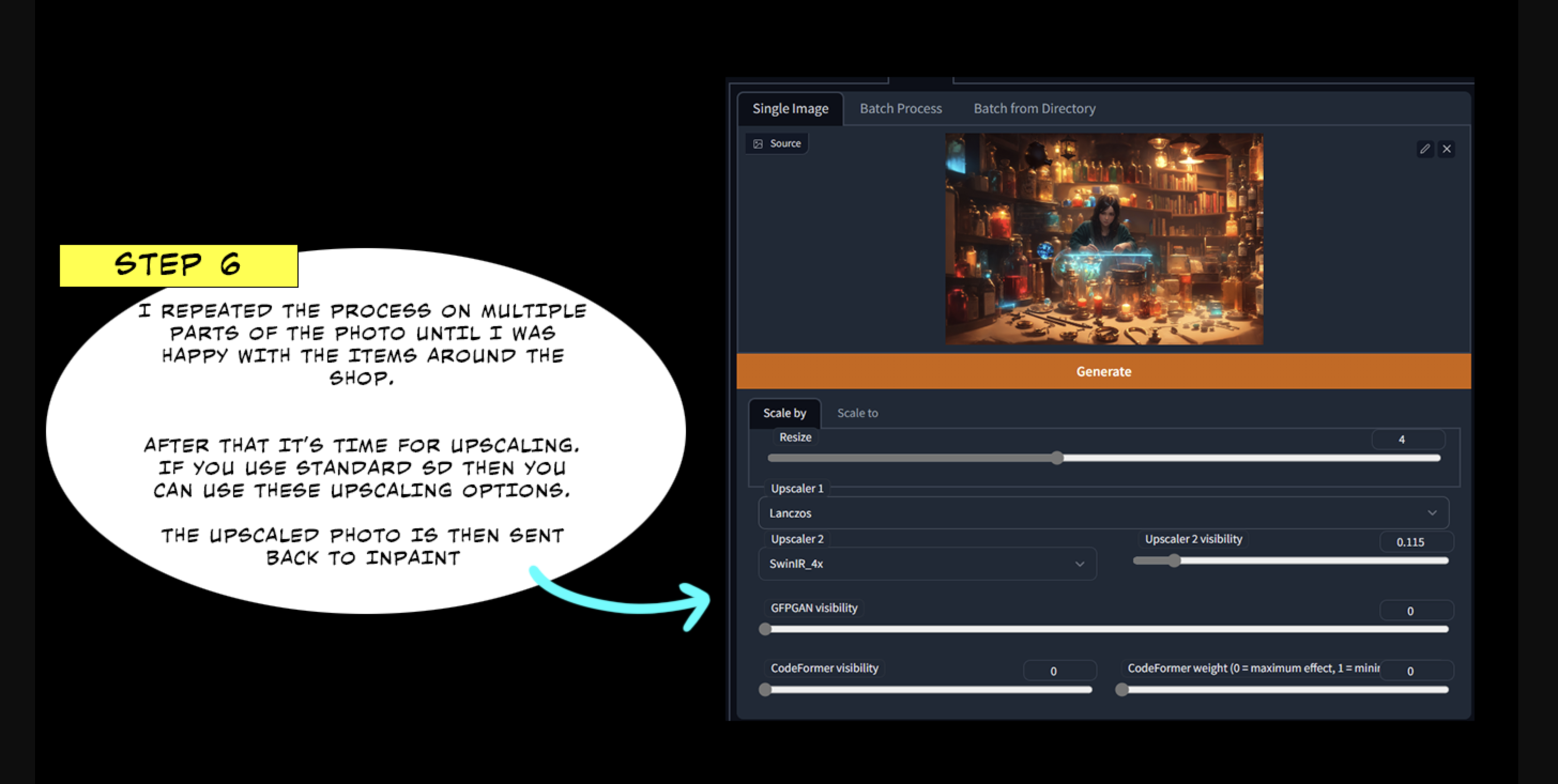
第六步:
我在照片的多个部分重复这个过程,直到我对商店周围的物品感到满意。 在这之后,就到了放大的时候了,如果你用的是标准SD,那么你就可以使用放大的选项了。
缩放后的图片将被送回 Inpaint。
第七步:
遮盖主体,并在参数中描述遮盖物内的内容。 在这一点上,你的SD已经根据放大的图像自动更新了分辨率,你需要在点击生成之前将其降低,你可以再次复制下面的设置。
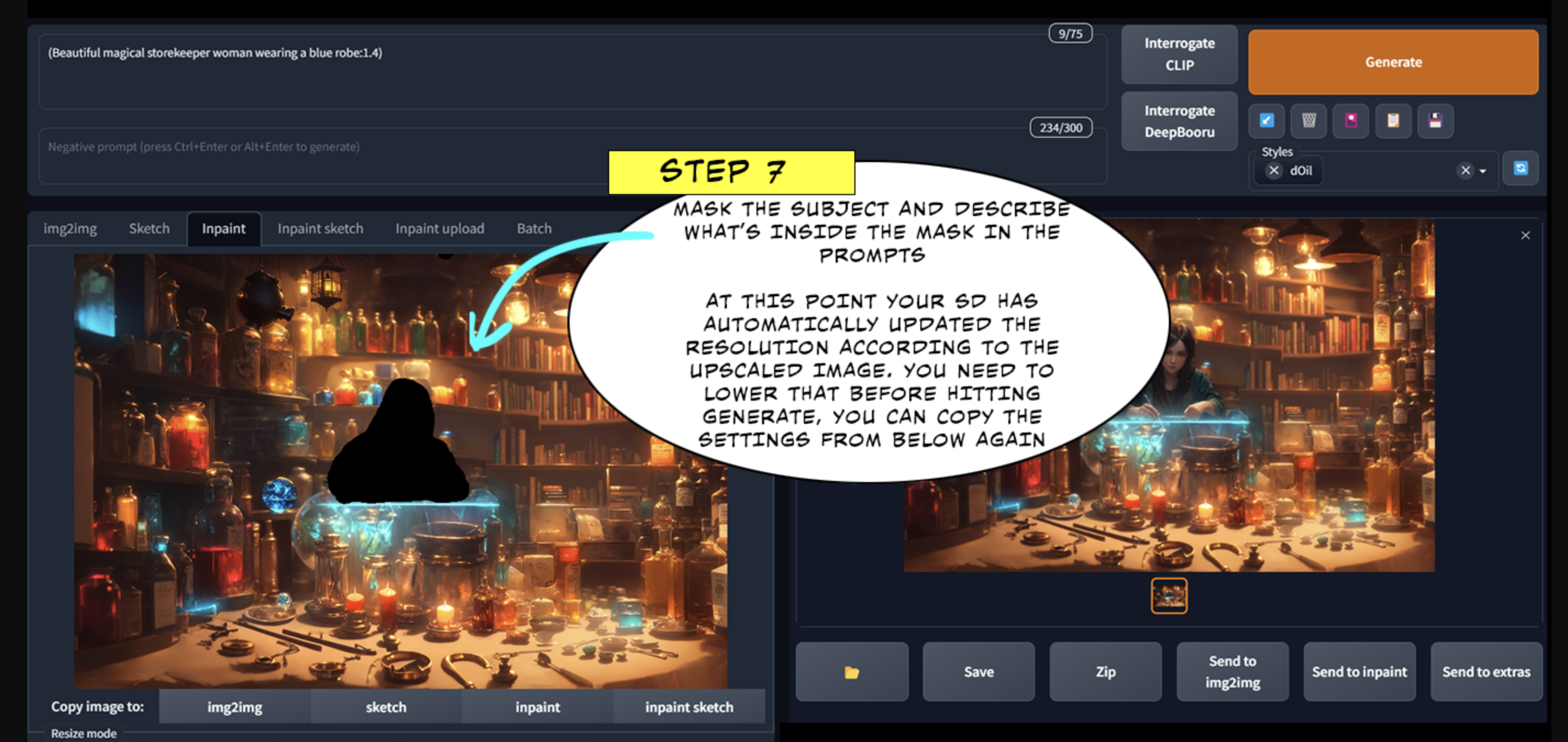
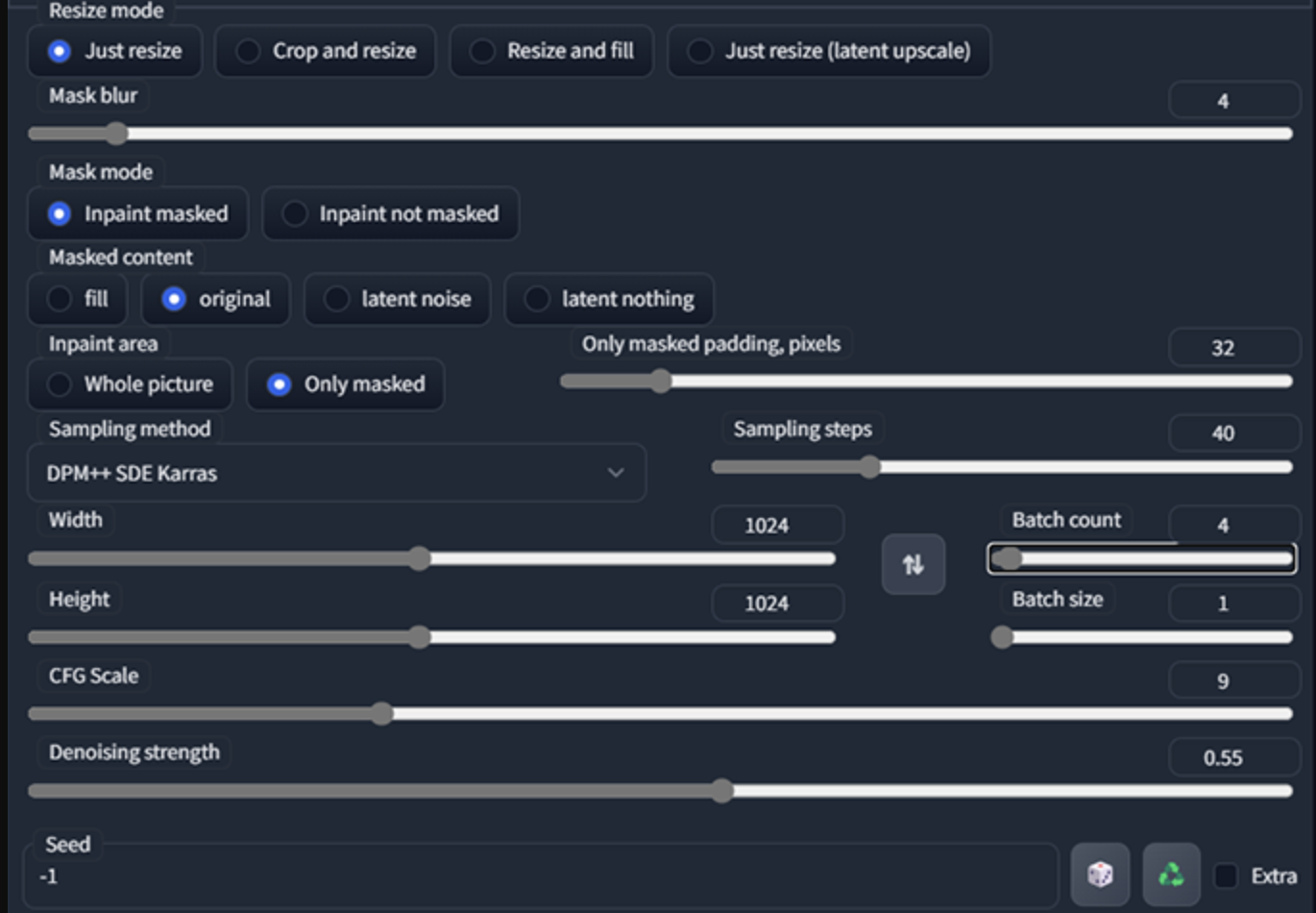
第八步:
在把主题画成你喜欢的样子后,你可以再回到商店的物体上,可能是一次一个物体,这是非常重要的,但也非常耗时,我最后去Photoshop做了一些润色。 到这里我们就全部完成了。
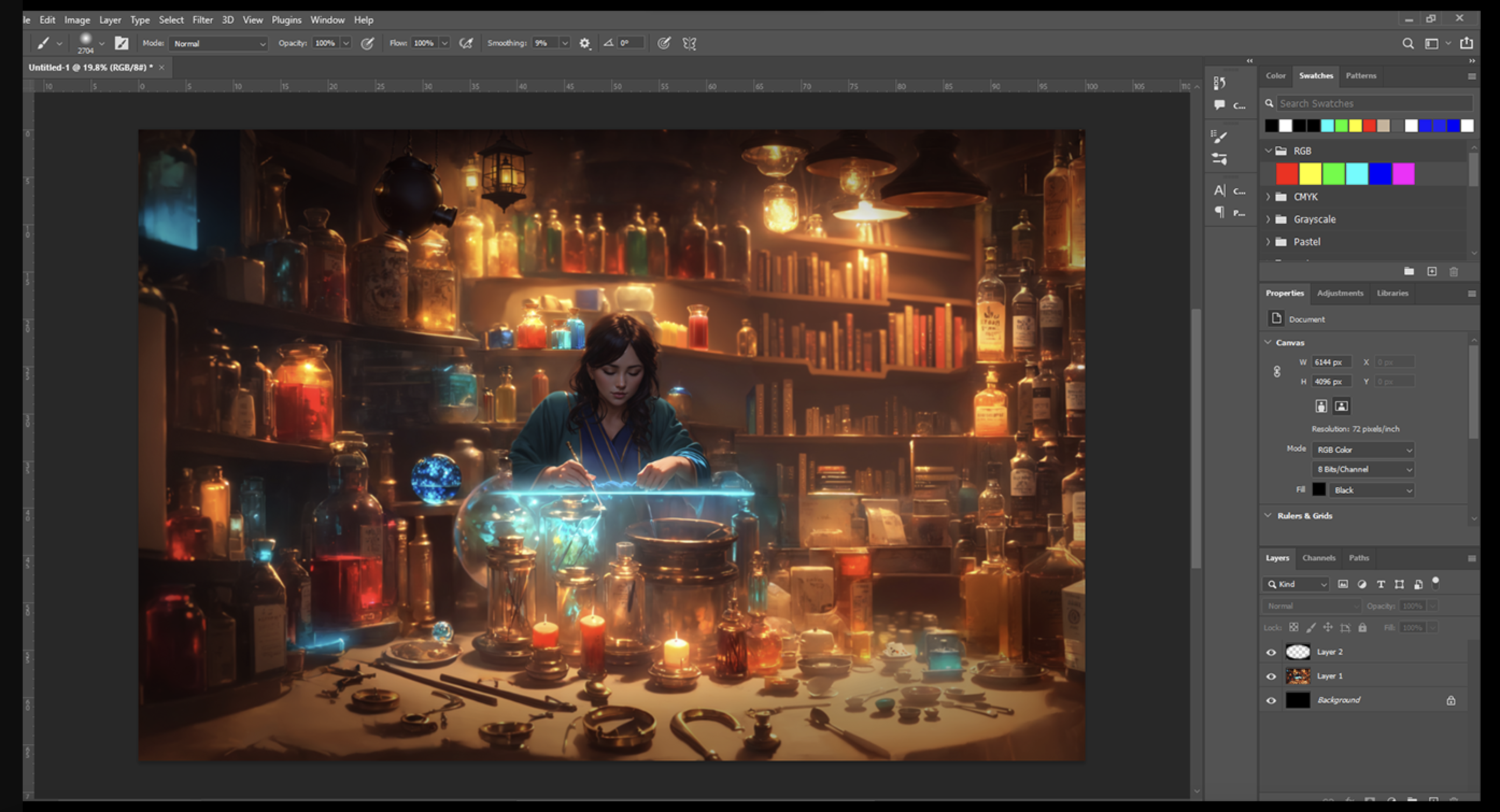
最后成果












































![Amazon亚马逊 I 主图A+ [合集]](https://img.zcool.cn/community/6a38dcce3687ayo427oj4f8979.png?k=a25b8da5cbfa0567e23934d76e205064&t=6a6a2380&x-oss-process=image/resize,m_fill,w_520,h_390,limit_1/auto-orient,1/sharpen,100/quality,q_80)
























