SUS可用性测试你应该不陌生,日常工作中或多或少会接触到。但可能没有深入理解它的原理,导致每次使用时都需要重新查资料......今天我们就简单聊一下这个测试工具~
SUS使用了Likert量表(一种用于测量态度或感知的心理量表,
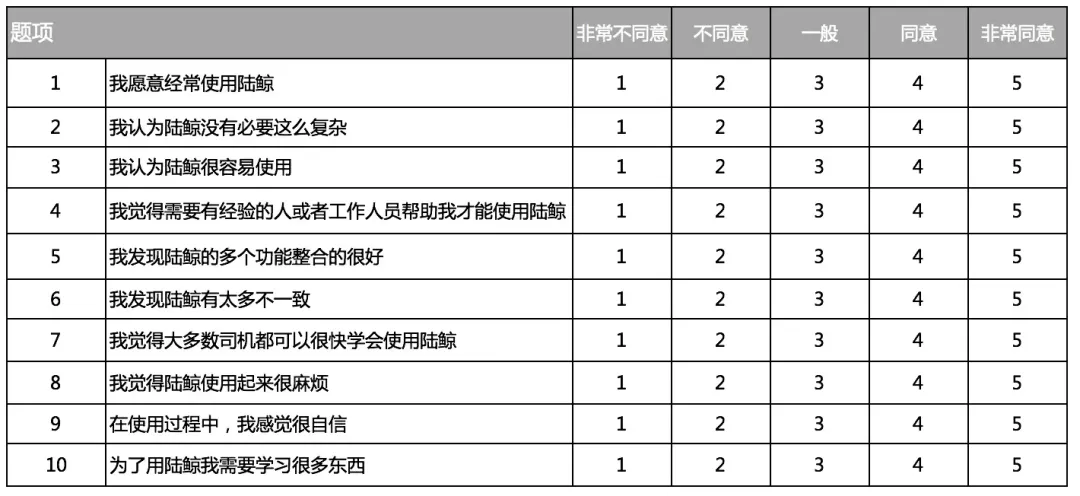
由10个正负交错的问题组成
),让受访者对某些陈述做出反应,用户需要在“非常同意”和“非常不同意”之间打分。通过
捕捉用户的主观体验,反映他们对系统的直觉和情绪感受。 最终通过量化分析,形成整体评价。
SUS量表由10个问题组成,是结合便捷性和有效性综合考量的结果。
简洁性:
首先10个问题,满足了不同维度评估可用性(如:复杂性、易用性)。其次不会占用受访者太多时间,实施起来快速高效。
全面性:
10个问题由正面和负面陈述交错出现,帮助平衡用户的主观体验,减少偏差。
常用的测试量表都是从1-5(非常不同意-非常同意)组成
这是因为5级量表相较于7级或10级量表更能减少用户的认知负荷。当我们面临更多选项时,往往会更加犹豫不决,而5级量表的选项较少,用户能更迅速凭感受做出选择。
另一方面,5级量表也简化了后续的量化分析,范围较小,结果更易于汇总和解读。
准备好测试产品:
请注意,SUS用于评估用户体验,而非功能性测试。因此,在测试前需要准备好你要测试的产品(开发产品、可交互的demo)。
选择受访者:
受访者应为系统的目标用户。参与者不需要具备技术背景,重点是捕捉他们的主观感受。一般来说,5-8名受访者即可。
引导用户体验:
给用户一个任务,让他们在不受干扰的情况下完成。过程中不要提供过多指导,让他们根据自己的理解去操作。
SUS问卷打分:
用户完成任务后,立即让他们对SUS10个问题进行打分,问题可围绕:用户完成任务后,立即让他们对SUS的10个问题进行打分,问题可以围绕以下内容:
以上这些问题可以进行小幅度调整,但正负交错排序不可改变!
量表评分计算:
根据问题序号,1、3、5、7、9题的用户打分减去1,得到最终分数(例如:用户打了4分,最终得分为4-1=3分);2、4、6、8、10题则用5减去用户的打分,得到最终分数(例如:用户打了2分,最终得分为5-2=3分)。将10道题的分数相加,得到用户的总得分(总得分在0-40分之间)。接下来,将总得分乘以2.5,换算为0-100的范围。
题目按序号分基数、偶数来分别计算式为了能让得分落在“相同”的数值上。因为我们的题目的问法是正反交错的,只有按照这样来计算最后的分数才能统一成一个方向。(如:你是否觉得这个产品好用?和你是否觉得这个产品难用?用户对这两个问题分别打了4分和2分,那其实按照上面说的计算方式,才能将这两个回答统一成3分!)
乘以2.5的目的是将结果换算成100分制,方便与SUS量表评估标准进行比较。因为正负题的分数最大值为4,10题的总分最大为40,换算成100分制即为乘以2.5。
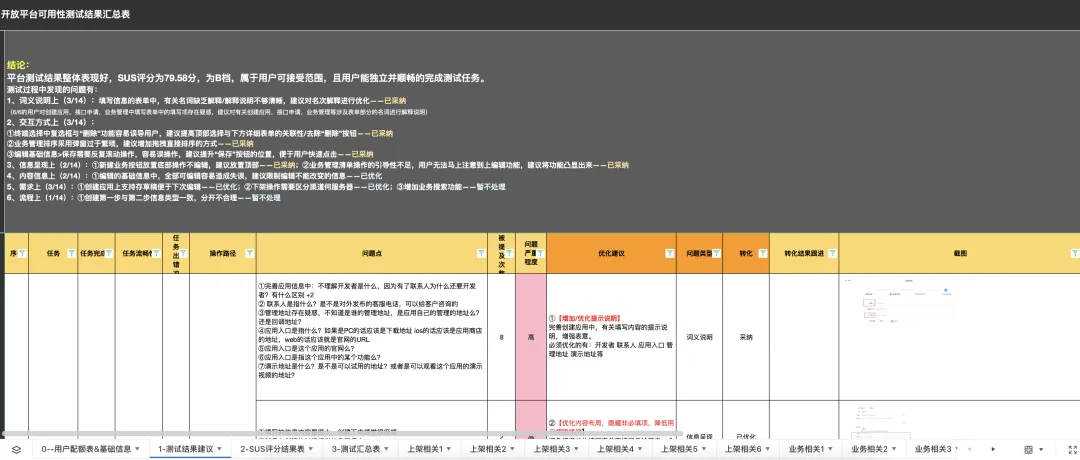
完成SUS测试后,结论才是最终的产出。根据测试目的提炼结果,给出项目后续的产品改进建议。例如:
以上就是我对SUS在项目中的实际应用,以及其运作原理和计算方式的解释。我还整理了一份SUS量表及示例的模板,想要获取可以关注公众号:小发的设计笔记,在后台回复“
可用性测试
”。