2025年AI发展迅猛,AI视频大模型百花齐放,各种创作形式推陈出新,我也在这样的风潮下自己尝试做了一期数字博客的中视频。
制作这一期内容,我一共分为四个部分:
播客文案转换、AI声音生成、视频对口型生成、后期剪辑
。下面,我将逐步介绍我这四个阶段的具体制作流程:
首先,我选了一篇我自己的原创文案,这篇文案其实是我自己针对凡人修仙传观后感的一个观点的表达。我将这篇文案先后喂给了豆包、deepseek,帮我生成对话式的播客内容。在测试中,豆包和deepseek为我生成的文案内容都较好的完成了我的要求。在经过几轮调试和对比之后,我得到了一篇自己还较为满意的文案脚本。
这次用到的是海螺AI的minimax speech-2.5模型,我通过这个模型创建了两个属于我自己的音色。将之前文本中两位主播的口播内容进行了声音的转换。
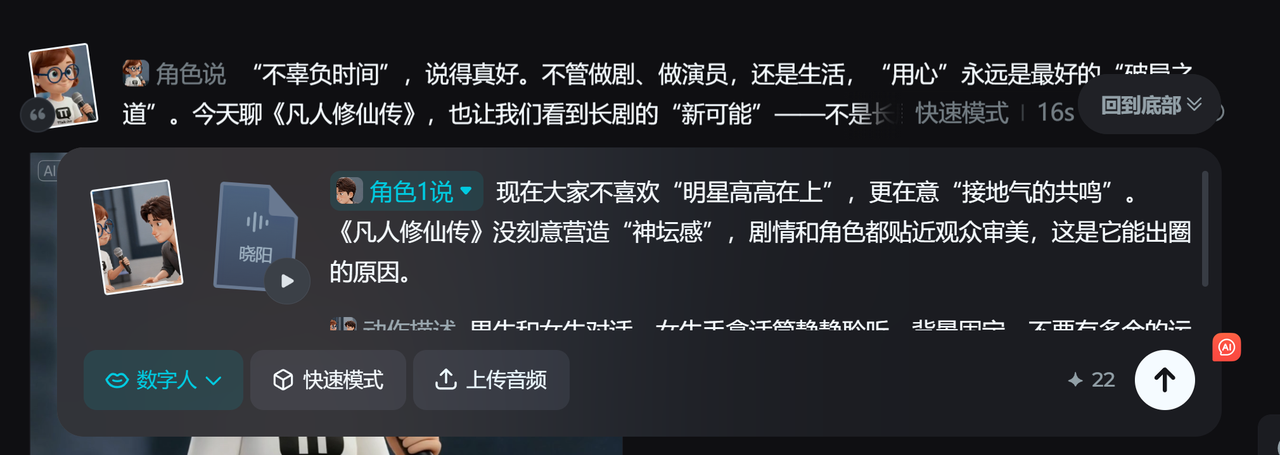
我的思路是,首先先生成二人同框的全景画面,然后再根据人物的对白,分别生成各自的切镜画面。
对口型这一步其实我花了很长时间,因为一直在测评市面上一些对口型的大模型。比较了很多之后我最终还是选择了即梦的商业模型来处理视频对口型生成。因为视频生成的市场受限,所以我也在这个阶段花了很多时间来生成。