AI助力下的 3D 图标创作变革

杭州/设计爱好者/204天前/492浏览
版权
AI助力下的 3D 图标创作变革
写在前面,在写这个之前一直在想,之前的设计经历和工具都是陈旧的,可能对大家的意义不大,但是还是想分享一下自己的学习历程,也算是另外一个开端。整理时都用的初学的图,发现AI是真的震撼!!!
终于从项目间隙中抽身,整理这些年的设计资料。翻看旧项目里那些从简单到复杂的3D文件,不禁感慨万分。这条路的变化比我想象中更快——从最初在PS、Sketch里一点点绘制banner,到对着建模软件熬夜渲染、修改细节,再到如今借助AIGC快速生成符合需求的高质量效果。
尤其是最近体验即梦4.0时,那种“效率再次被刷新”的震撼,让我决定好好聊聊自己与3D banner、icon设计的这些年,让我想把这些年的实战经历、踩坑教训和思考整理出来,对自己的成长进行一次复盘,这是一条从“亲手雕琢”到“与AI共舞”的进化之路。
我从下面几个方面来进行展开:
- 起点:传统3D图标的“慢工出细活”
- 探索期:从 Cinema 4D 到 Blender 的工具迁徙
- 转折点:AIGC的学习曲线—从抗拒到共舞
- 实战对比:SD vs 即梦,谁更适合中文设计师?
- 回归设计:工具在变,但 “设计的本质” 从未变
一、起点:传统3D图标的“慢工出细活”
最早接触 3D 设计时,,轻量化工具还未普及,全程依赖传统软件手动打磨,一个图标的诞生,从需求拆解、草图构思到上色渲染,往往需要耗费数小时。我的制作方法是:画完草图后,在 Adobe Illustrator 中绘制矢量图标轮廓(确保边缘光滑),导出后导入 Sketch 分层上色,再用 “内阴影 + 渐变 + 纹理叠加” 模拟 3D 质感 ,单一个icon从轮廓绘制到光影调试,往往要耗上一两个小时甚至更多。
那时最核心的矛盾在于 “细节与效率”的博弈:想让图标更具科技感,就需增加复杂的纹理和结构,但所需时间会成倍增加;若为了追赶项目进度而简化模型,视觉效果又会大打折扣。每次接到需求,脑海里总会想“这个效果用现有工具能不能实现、要花多久”。
现在回看那些旧作,虽然带着“手工打磨”的青涩痕迹,但正是这段经历,让我深刻理解了3D图标 “适配UI场景”的核心逻辑:并非越复杂越好,关键在于在视觉表现力与实际应用体验间找到最佳平衡。
这段经历也并非全无价值:手动调试光影的过程,让我摸清了 3D 设计 “适配 UI 场景” 的核心逻辑 ——UI 中的 3D 效果,从来不是 “越复杂越好”,而是 “在视觉表现力与使用体验间找平衡”。比如移动端图标,即使做了复杂的浮雕纹理,缩小到 24px 后也会模糊,最终还是要回归 “简洁光影 + 清晰轮廓” 的设计原则。但 “每一个倒角角度、每一束高光位置都由自己掌控” 的过程反而让我感觉很兴奋,同时奠定了我对 “3D 设计细节把控” 的敏感度。

二、探索期:从 Cinema 4D 到 Blender 的工具迁徙
最初接触建模工具,多少有些被设计师圈子的“内卷”推动——看到身边同行都在用3D提升设计质感,我也踏上了学习之路,至今仍记得,当简单的几何体被赋予材质与灯光,经过渲染呈现出逼真质感时,那份创造的喜悦是无与伦比的。
最先上手的是 Cinema 4D(简称 C4D),毕竟当时行业教程多、社区支持完善,至今记得第一次用 C4D 建模时的场景,新鲜感过后,现实问题接踵而至:我使用的Mac电脑,与C4D的渲染插件适配性不佳,每次渲染一张玻璃质感的banner或图标,都需要漫长的等待。而那几年,恰逢玻璃拟态风格席卷UI领域,无论是网站头图还是产品图标,都追求那种通透、有层次的质感,对于需要快速迭代的 UI 项目来说,效率太低。(看看初学的作品吧,我觉得非常具有纪念意义)

直到开源免费的Blender“横空出世”。它对Mac非常友好,渲染速度显著提升,我毅然加入了“Blender大军”。最让我惊喜的是其修改器功能与参数化建模思路,调整参数即可实时预览效果,将我从大量重复的体力劳动中解放出来。看当初的学习路径,从玻璃渲染到几何节点也是废了老大劲了,笔记记了一大堆。现在回头看当初的作品,渲染出的光影关系还是有些混乱。
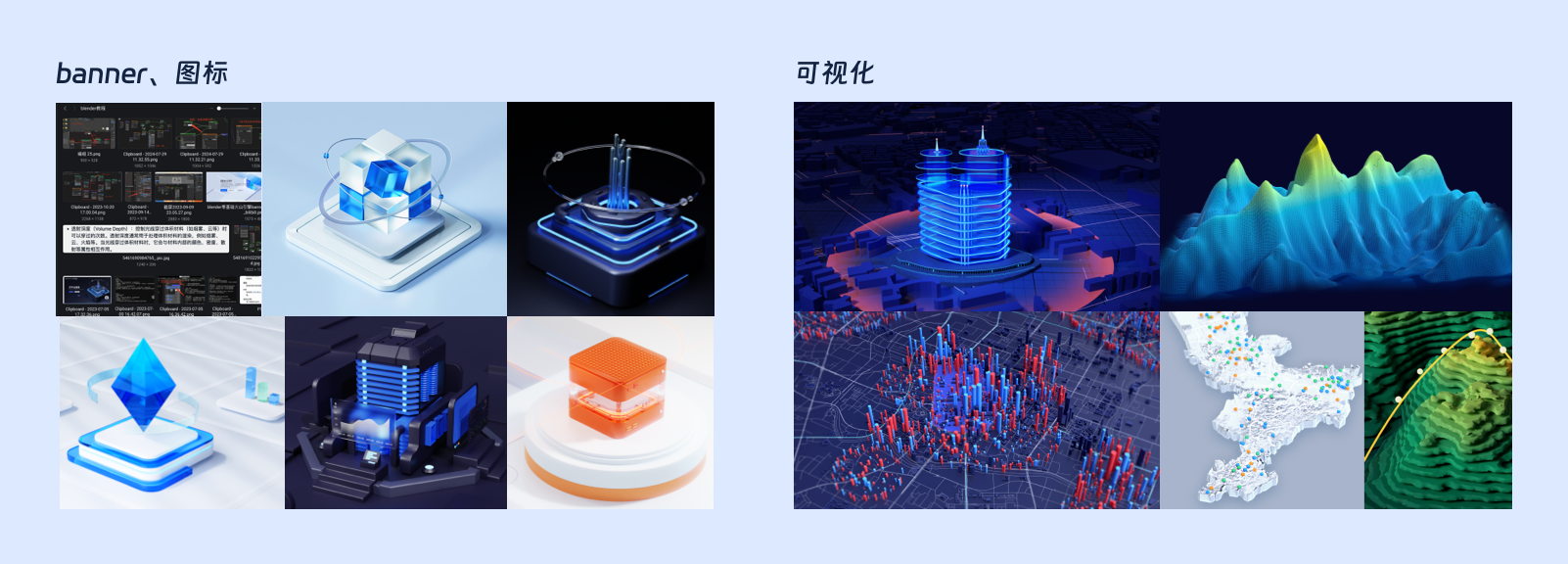
三、转折点:AIGC的学习曲线—从抗拒到共舞
2022 年 MidJourney 发布后,AIGC 开始冲击设计行业。最初我是抗拒的:总觉得 AI 生成的效果 “太飘”不符合 UI 规范,而且 “版权风险”“不可控性” 都是绕不开的问题。但当看到网络上同行用 AIGC 输出各种风格图时,第一次让我意识到:创意的源头,不再完全依赖于设计师个体。
在那段时间,我密集体验了多款工具,也经历了“乱出图”、“不可控”、“版权风险”等普遍性质疑。尤其是在UI这个强调精准、一致性的领域,总觉得它们差了点什么。我的体验如下(也可能是我使用没到家哈):
- Midjourney:界面直观、操作简单,新手友好,是激发灵感、进行创意脑暴的绝佳帮手;局限性是控制力弱,难以保证风格统一
- Stable Diffusion:界面复杂,学习曲线陡峭,但可控性极强,自由度极高。其LoRA模型和ControlNet功能能提供极强的控制力,非常适合对输出一致性和风格统一性要求高的项目,上限很高。
- 神采 AI:介于MJ和SD之间,操作比SD简单,支持中文提示词输入,在当时是难得的对中文用户友好的工具;但缺点是 “风格扩展性弱”,生成的效果偏常规,难以做出极具个性化的 3D 质感
我当初学习的目的,是探索如何通过文字、符号等方式,将AIGC稳定地应用于UI工作中,让AI能根据我的明确意图进行创意辅助。下图展示了当时利用“图形控制”功能,SD与神采AI的生成效果对比。直观感受是,神采操作更简洁,而SD则潜力巨大。

随着社区发展,网络上出现了大量专门针对UI设计的“炼丹”成果,例如能够稳定生成毛玻璃风格的LoRA模型。同时,更多AI工具涌现,特别是 “即梦”的出现,让我第一次感觉到AIGC不仅能用于视觉输出,更能在专业的UI领域精准、高效地发挥作用,也让我看到“本土化AI设计的潜力”至此,我对 AIGC 的心态彻底从 “抗拒” 转为 “共舞”—— 不再把 AI 当成 “替代设计师的工具”,而是 “放大创意效率的助手”。
四、实战对比:SD vs 即梦,谁更适合中文设计师?
“当你体会过SD的‘咒语’有多难驾驭,就会明白即梦的提示词有多么友好。”这是我使用即梦后的最直接感触。如果说SD的提示词是“咒语”,需要反复调试才能精准命中,那么即梦的提示词更像是“对话”——自然、直接、理解力强。以下是我基于3D图标实战的几点对比:
1、词义理解:中文思维的天然优势
UI 设计中,我们常需要精准控制图标形态,我曾需要做一个“定位”图标。在即梦中,直接输入“定位”,生成的结果在造型上基本符合预期。而在SD中,我尝试了“position、location、address、registration”等多个词汇,都难以生成我心目中那个简洁的图标符号,这对于不精通英语的设计师来说,是一个不小的门槛(也有可能是我个人门槛😜)

2、工作流与统一性
UI 项目常需要 批量生成同风格图标,我的通用流程是:固定基础提示词 + 更换主体名称,确保系列图标风格统一。
- SD:固定种子、参数、LoRA模型等各种参数,输出效果基本可以保证统一
- 即梦:支持多轮对话记忆,中文延展性强,更方便我用“大白话”去修改
但整体上个人感觉,即梦对中文提示词的延展性理解更好。例如,输入“望远镜”,即梦会生成包含单筒、双筒等不同样式的图标;而在SD中,我则需要分别输入“telescope”和“binoculars”来获取。
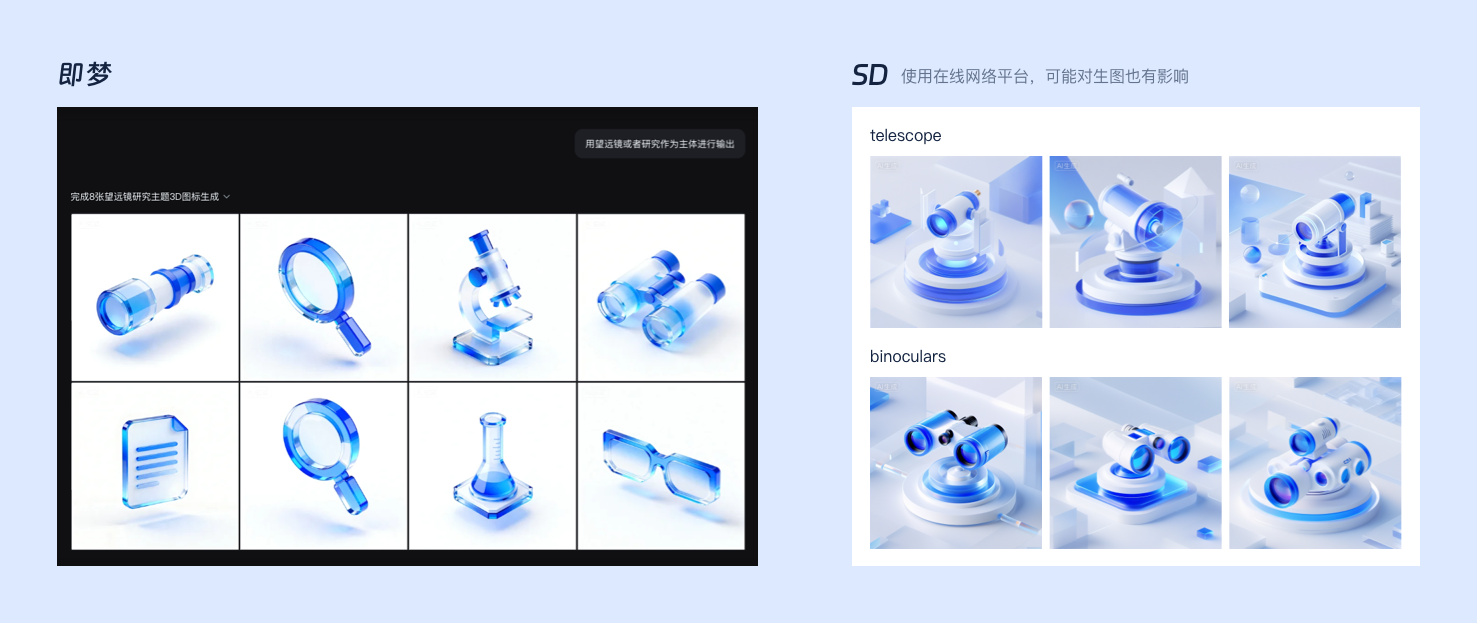
3、落地实践与效率
在生成复杂图标时,主体和底座有时会不如人意。我的解决方案是:分开生成,后期合成。即分别生成图标主体和底座,然后在图形软件(如PS或Sketch)中进行拼合与再处理,这种方法同样适用于复杂的banner设计。

总结
:目前在我的日常工作中,即梦的使用频率更高。尤其是4.0版本在3D玻璃图标的层次感、通透度上表现惊人,其多轮对话能力也在一定程度上缓解了我构思提示词的压力。但必须承认,如果你追求的是国际化的、拥有极致3D写实质感或强烈科技风的图标,SD在极致效果的上限方面,依然是首选。
如今不少 AIGC 工具已拓展出视频生成能力,即梦也不例外。不过目前我对这一功能的探索还比较浅,仅做了简单的试用,尚未深入研究复杂场景的表现。从初步尝试来看,即梦的视频生成对 “简单提示词” 的响应度较高,生成速率个人觉得也很快,仅从当前的初步体验来看,即梦 “用简单提示词就能生成可用视频” 的特性,已经为 UI 设计师提供了 “静态 3D 图标 + 动态视频” 的一体化创作可能性,减少了跨工具协作的成本,这一点还是值得肯定的。后续若有项目需求,会进一步深入探索,可以先看一下简单效果,右侧动图是根据上面提示词优化重新生成的(使用在线网页替代sd,生成速率太慢了,还没有很多实践):
Current Time 0:00
/
Duration Time 0:00
Progress: NaN%
Playback Rate
1.00x
五、回归设计:工具在变,但 “设计的本质” 从未变
回顾这些年用不同方式创作3D图标的历程,从手工建模到AIGC赋能,我最大的感悟是:工具永远在迭代,效率永远在提升,但“设计的本质”从未改变——无论通过何种手段,最终都要回归到“用户体验”和“场景适配”这一核心上来。
AI的出现,让我的设计方法论变得更加多元。有时,我依然享受手绘草图的心流;有时,则利用AI进行疯狂的创意脑暴;有时,它又化身我的高效渲染引擎,关键是,我学会了打造属于自己的节奏与风格,让工具为我所用。
回头看这条路,从最初的“慢”到如今的“快”,从“单打独斗”到“与AI协作”,这不仅是技能的成长,更是心态的转变——我不再执着于“每一步都必须亲手完成”,而是学会了如何利用工具最大化地放大自身的设计价值。未来,必然还会有更强大的工具出现,但只要守住 “以用户为中心” 的设计初心,无论技术如何变迁,我们都能创造出真正有价值的产品。
写在最后:设计没有终点,只有持续的进化,共勉!!!
5
Report
声明
10
Share
相关推荐


















in to comment
Add emoji
喜欢TA的作品吗?喜欢就快来夸夸TA吧!
推荐素材















You may like













相关收藏夹
























Log in
5Log in and synchronize recommended records
10Log in and add to My Favorites
评论Log in and comment your thoughts
分享Share