其实关于AIGC,我想写的其实有很多,也算是见证它的兴起并一直尝试使用。从最开始的mj,到stable diffusion,再到一些国产ai工具的百花齐放,以及本篇我要讲的comfy UI 工作流。
目前更多的是把他们应用在工作上,现在这个时代大家都在不断的卷,我也不例外,在我的印象中,我似乎没有度过一个完整的完全不碰设计软件的周六日,只是觉得作为一个普通人只有不停的让自己进步才有可能在未来抓住属于自己的一个机会,不想完全没有成就的度过自己的一生,有时候音乐的深夜陪伴是作为设计师的主旋律,这句话可能有一部分设计师深有共鸣。
给大家分享我学习的comfyui工作流,在这里你可以学习到:
(温馨提示,这是我之前提到的工作流,分享我直接放到这里了: 链接: https://pan.baidu.com/s/1aFOCBRgihPoWWAMx02b99Q?pwd=wwq2 提取码: wwq2)
首先打开哩布哩布的在线工作流,这也是比较常用的在线工作流,基本能满足我们日常百分之95的需求,很多插件官方都帮助我们安装好了,地址在这里 https://www.liblib.art/
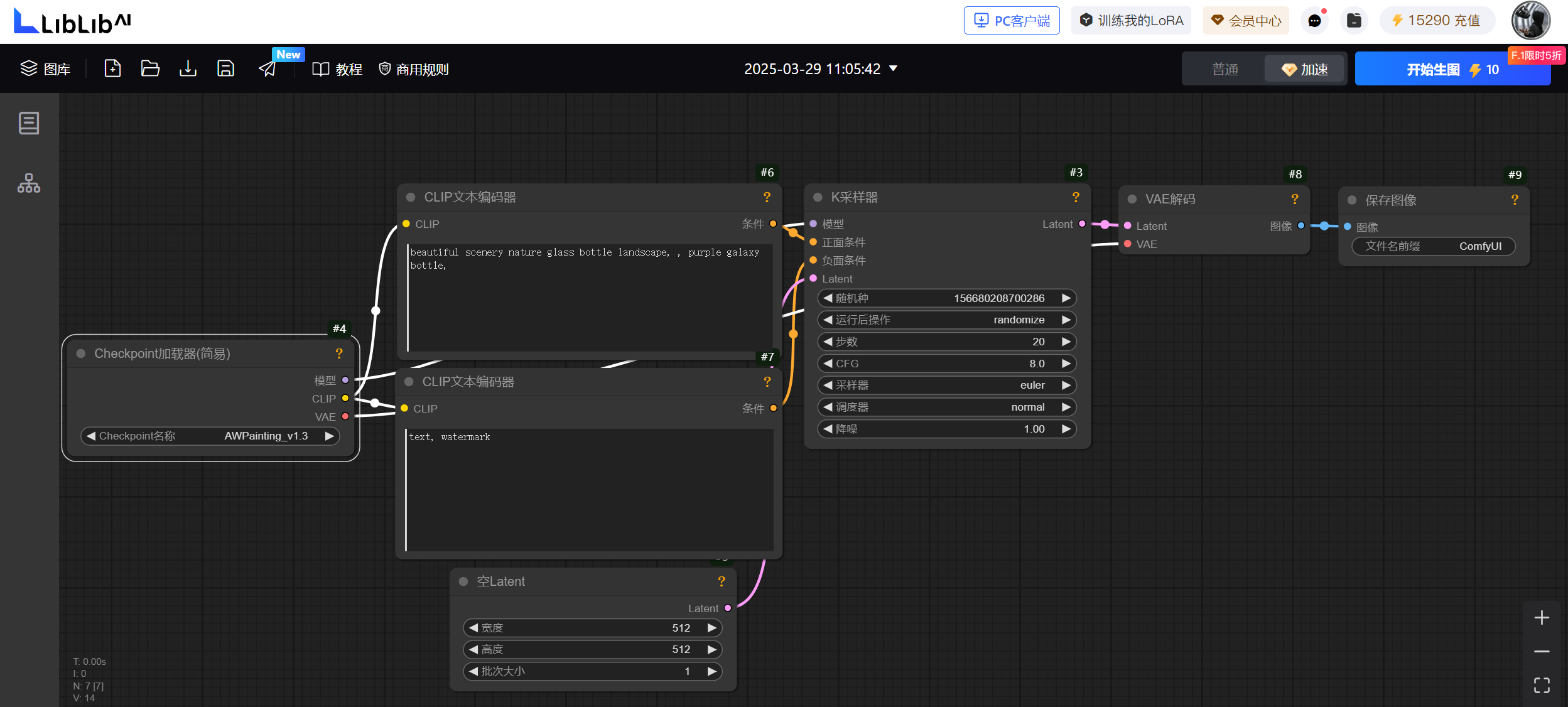
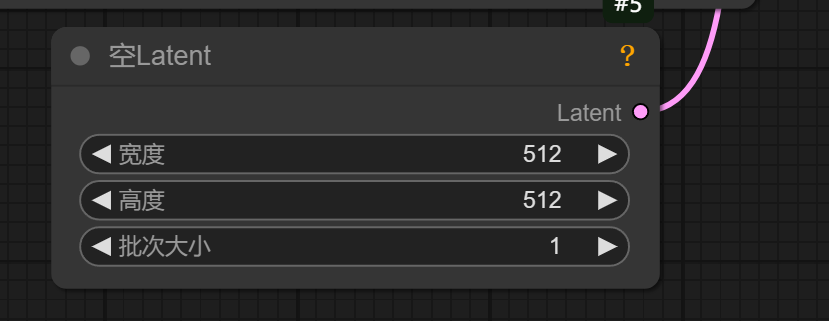
点击上方的默认工作流,就来到了我们一个默认的一个加载界面:
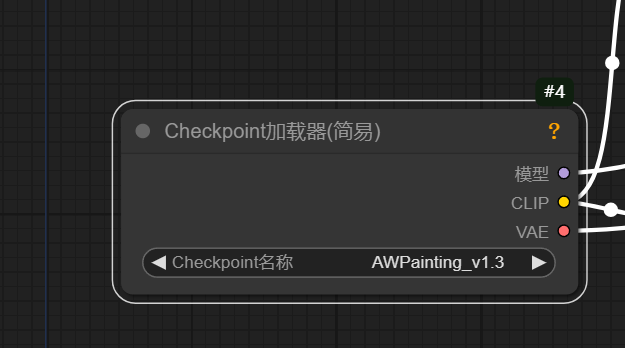
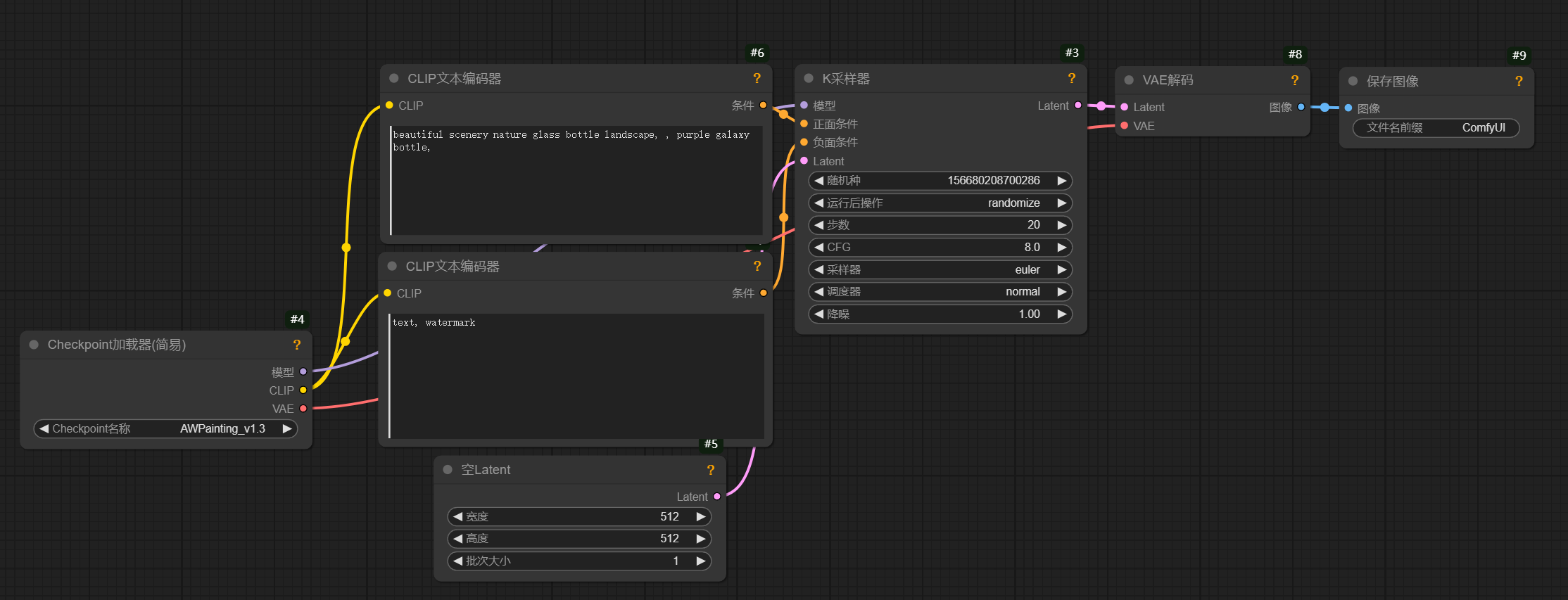
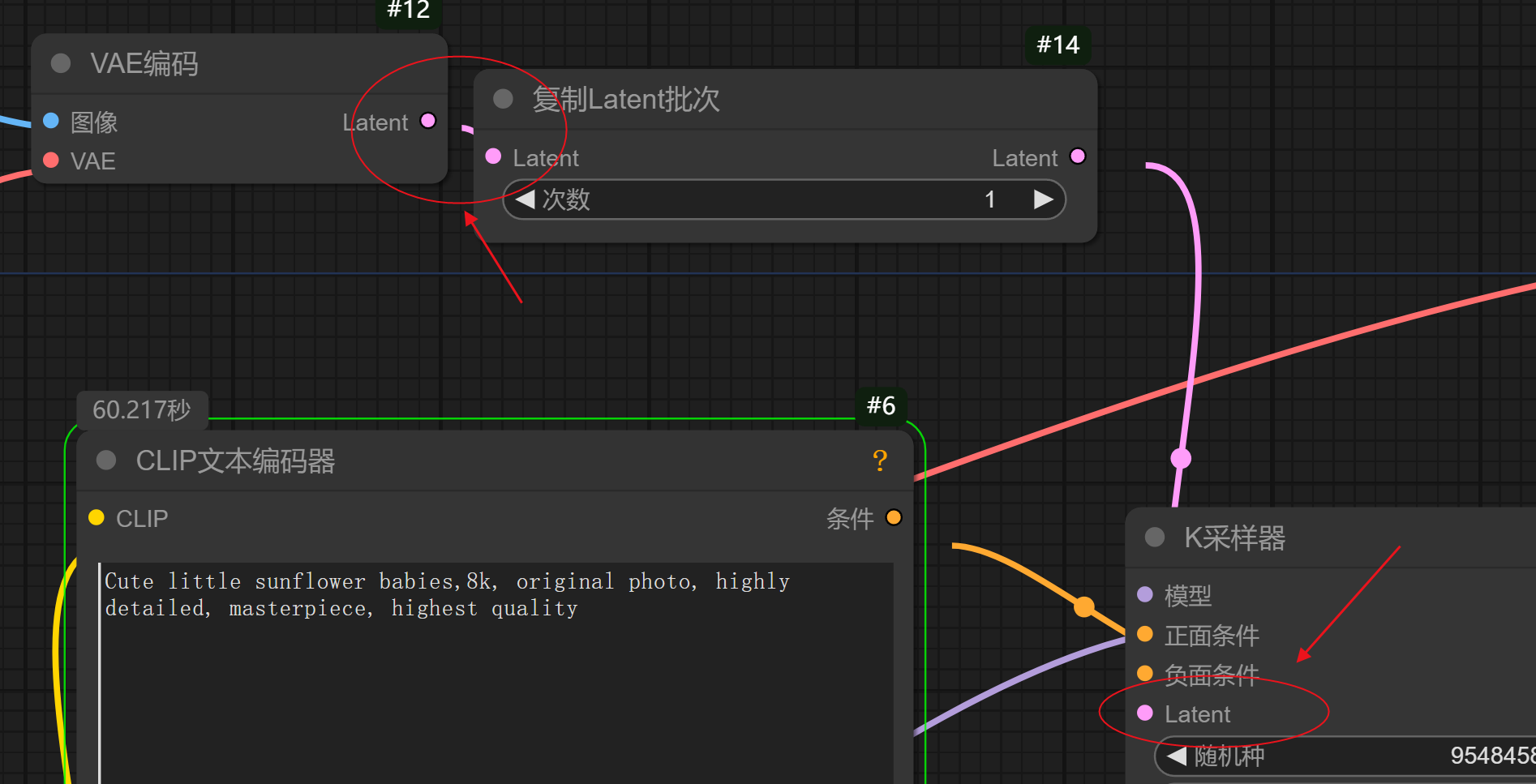
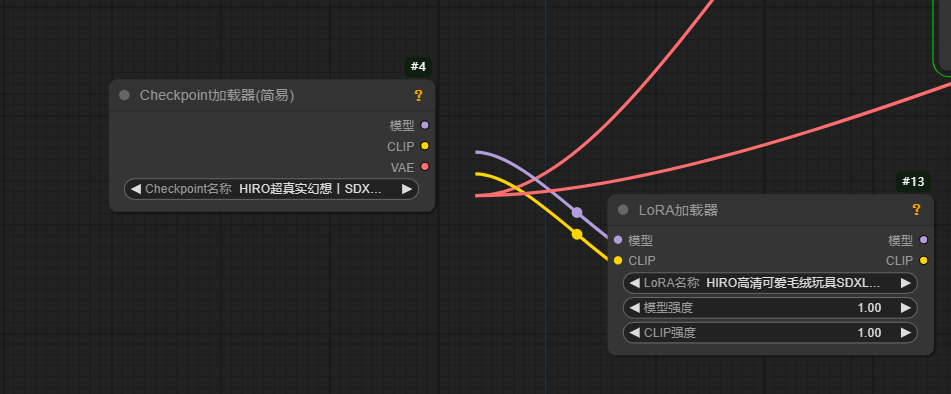
01 checkpoint加载器
:就是加载我们的大模型的,大模型就是一个所有图像生成的一个向量,数据都在这里,相当一个我们的大脑数据中心。
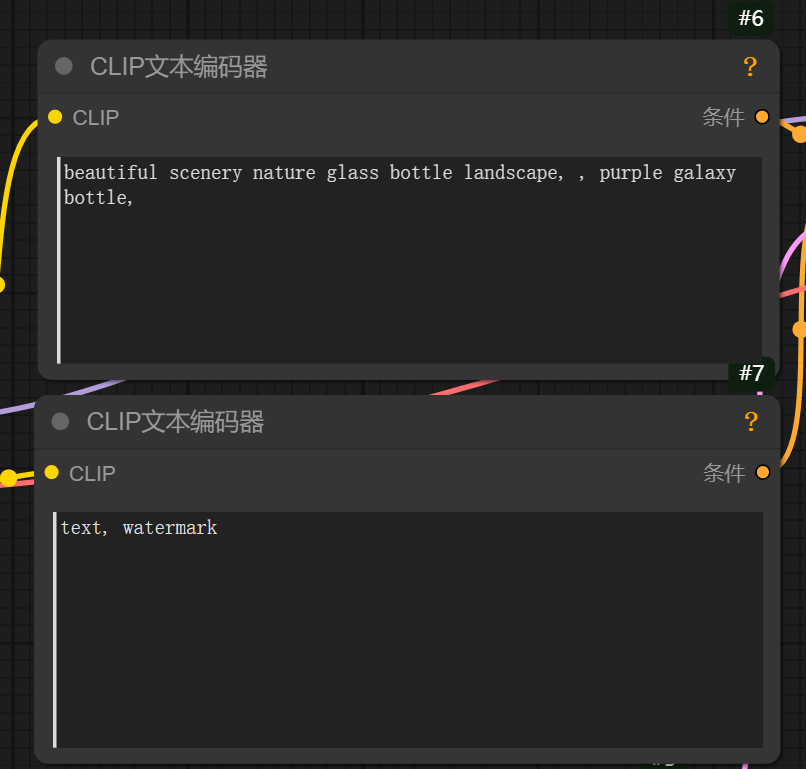
02 clip文本编码器:
顾名思义,就是写文字的,他有两个栏,一个是写正面提示词,就是你想要描述的画面,一个是写负面提示词,就是你不想出现的画面
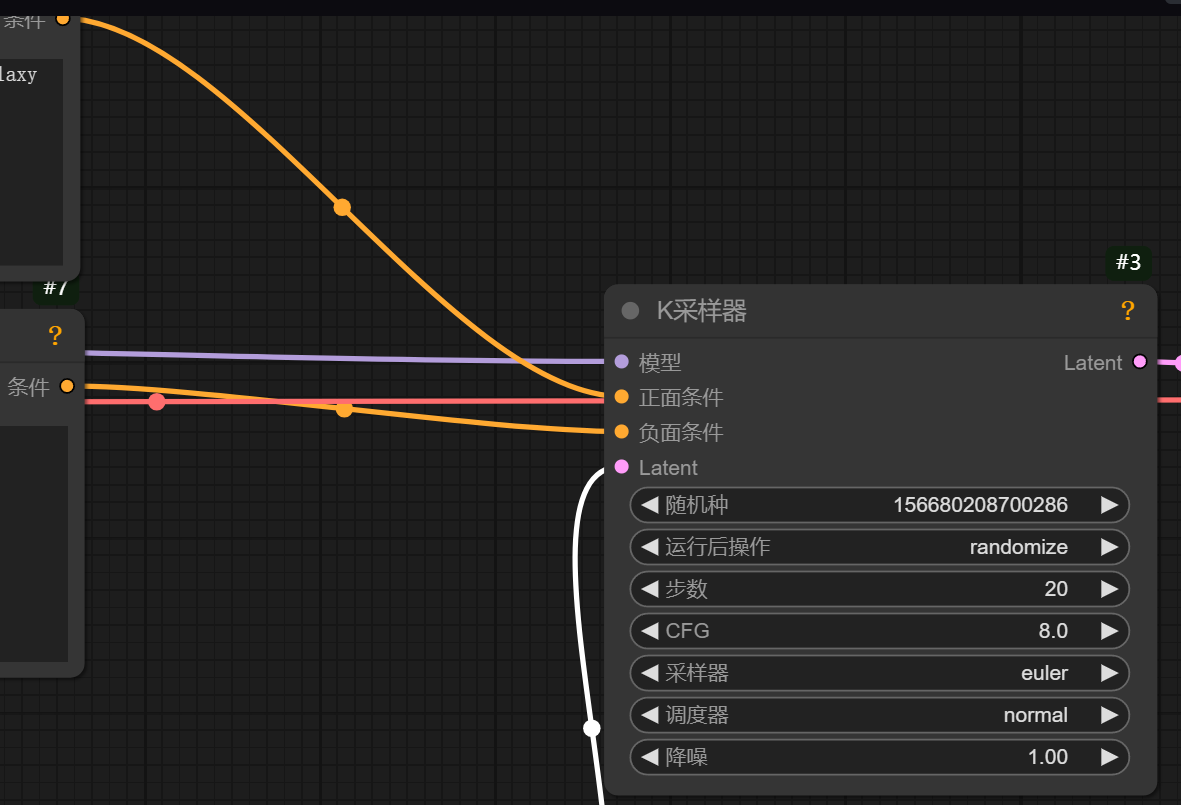
04 k采样器:
这个也是比较核心的节点了,分别对应连接文本的正负面提示词,也可以通过控制图片的噪点从而去调控图片的质量。
随机种子:
就是每个图片应有的属性,就像你的身份证,改变种子就是改变它的属性。也是随机的噪声图。
运行后操作:
这里默认随机就可以,可以保证每次运行后生成不同的图像。
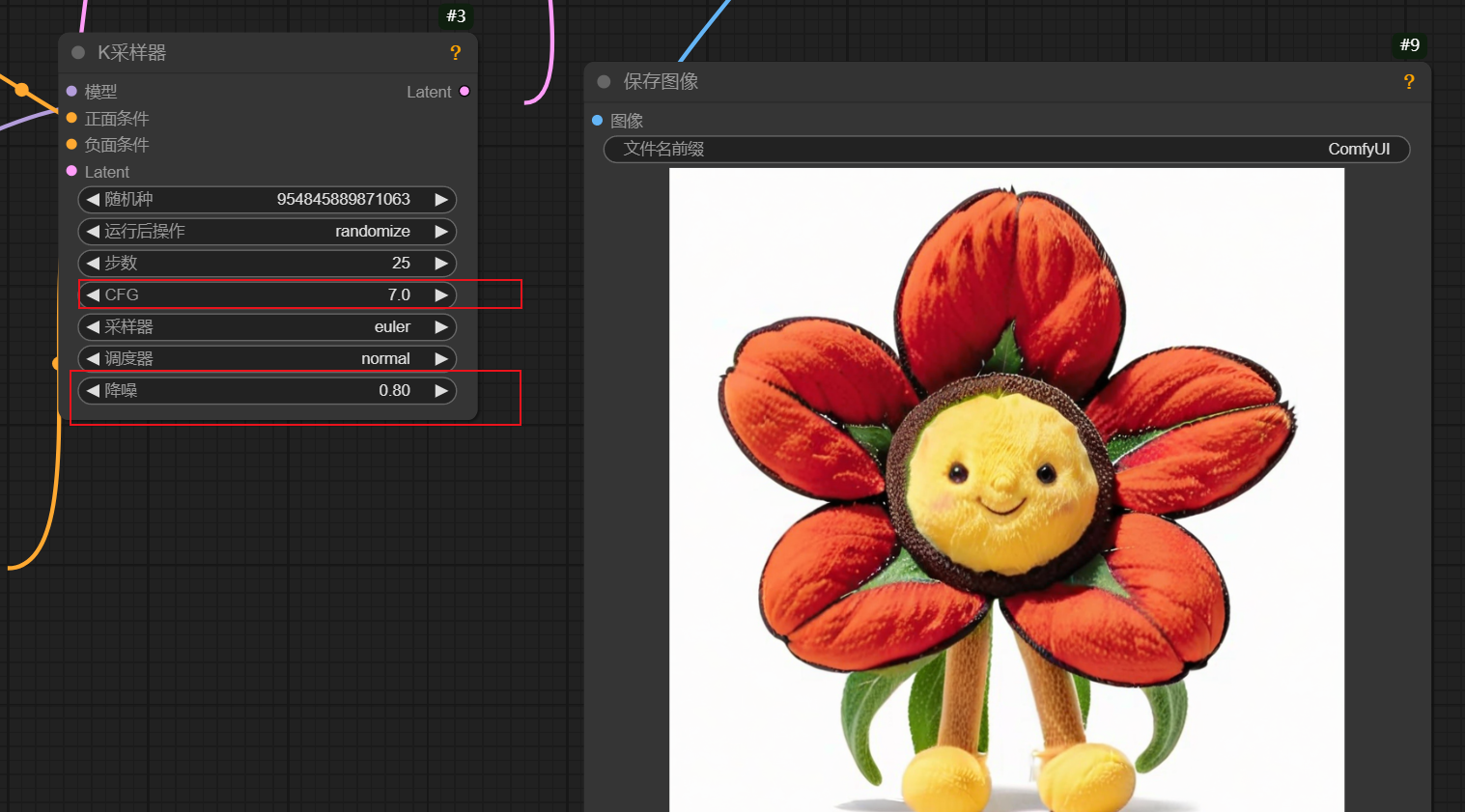
步数:
降噪的次数,越多越清晰,一般25-30就可以
CFG:
数值越高和图片的关联性越强,过大会优化图片细节,过小识别不了提示词,一般默认就好
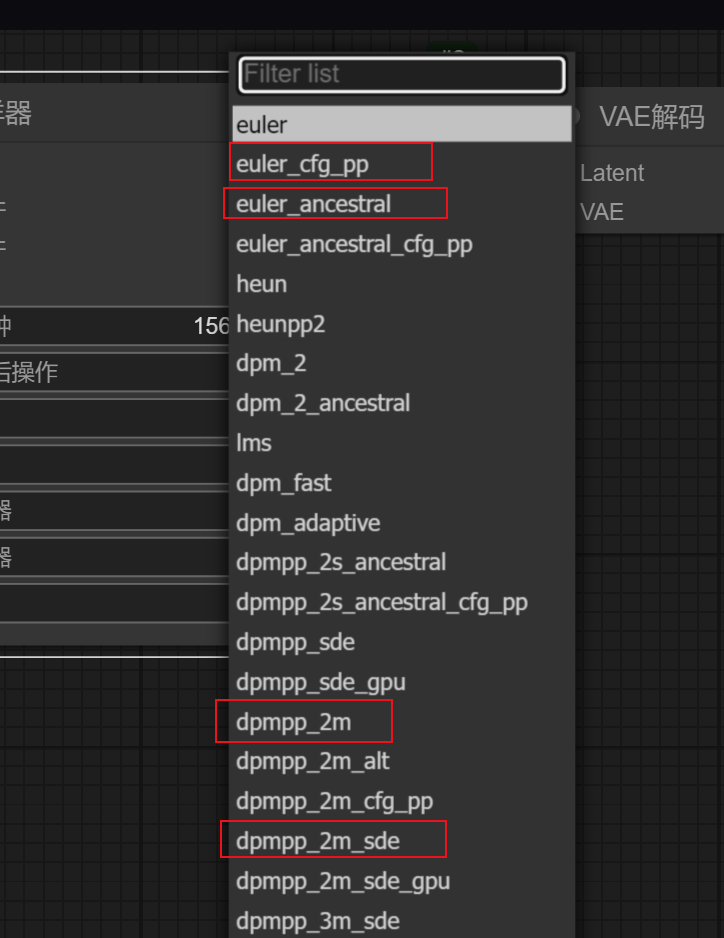
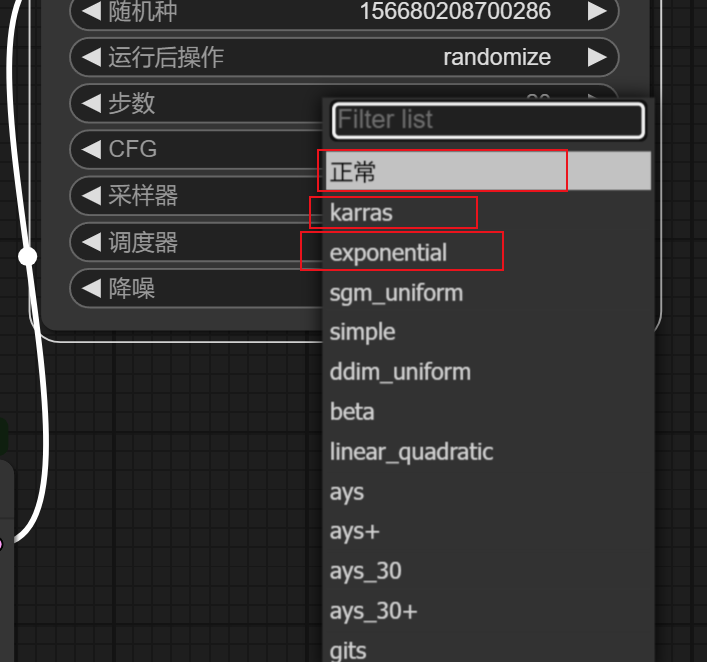
采样器调度器:
其实这俩参数在webui里面是一起的,这里分开了,作为控制采样器的节奏。一般其实也可以默认。
调度器这三个选择试一下就好,常用是这个karras,也可以自己抽卡测试一下别的
学过webui的应该知道,采样器和调度器就是这个采样方法,这里只是分开了。
05 vae解码:
把采集的文字信息的模糊图片转化为清晰图片
最后就可以输出我们的图像了,这就是比较基础的文生图工作流了。
这些节点就按照颜色链接就可以了,
ctrl+鼠标左键框选多个框,shift+鼠标左键移动多个,ctrl+g对多个框框打组分类,基本也就这些。
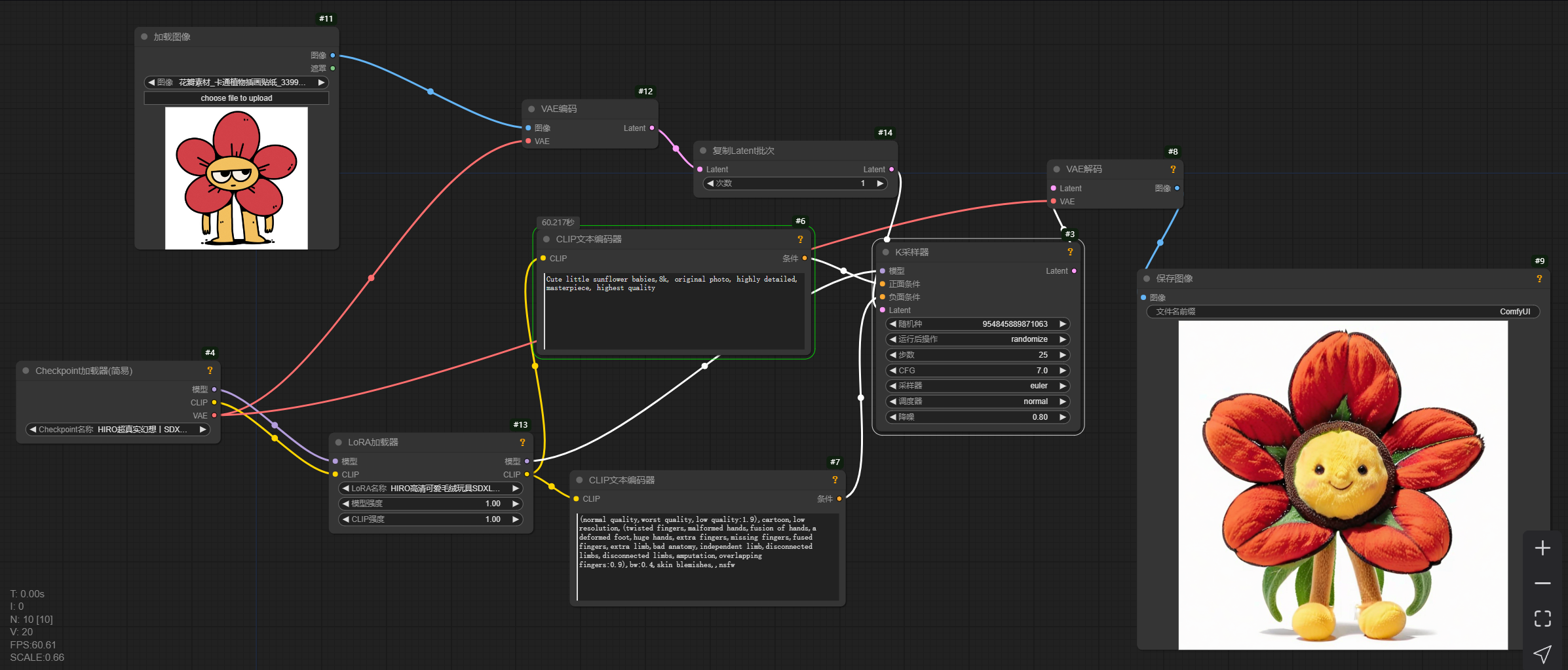
这里其实和文生图参数基本一致,需要我们认识的几个参数如下:
02 VAE编码:
就是把我们输入的图片数据转换为向量数据,一般用在图生图中。他和vae解码的区别是一个图片转换向量数据,一个是数据噪点转化图片,我是这么理解的。
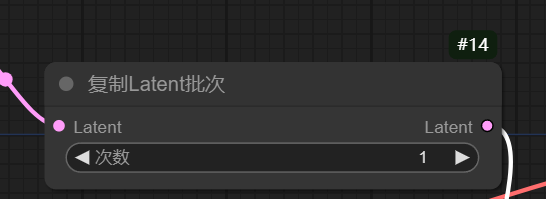
03 复制latent批次:
就是输入几张图,可以看到他是双向的,上面介绍的一个空laten是单向的,图生图我们要用这个双向的
如果生成的图不像,就调节一下这个CFG和降噪,最终实现一个可控的数值。
lora是采用的下面毛绒效果,所以大家想换风格,可以再去哩布搜一下别的风格的lora,图生图基本框架就是这样,我只介绍这一种。
这里怕大家不懂,我再解释一下大模型和lora的关系:
大模型就是你修炼的功力,这也是你的内功,你的图质量高不高本质也是大模型决定的,lora就是你武功的特色,比如“乾坤大挪移”,它是有固定风格的。所以出图的风格的控制lora很关键
还有,如果我们想要搜索节点,可以空白出双击鼠标左键,就可以输入你想要的节点。
由于篇幅可能过长,有关现在流行的FLUX大模型和基本工作流我放到下一篇文章再去详细讲一下。那先讲解这么多,下一篇文章见