《大模型上下文工程(Context Engineering)指南》正式发布 | 中科算网算泥社区

北京/设计爱好者/142天前/302浏览
版权
《大模型上下文工程(Context Engineering)指南》正式发布 | 中科算网算泥社区
3月13日,由中科算网算泥社区主编的
《大模型上下文工程(Context Engineering)指南》
正式发布!该指南旨在为所有致力于构建高级AI应用的开发者、架构师和产品经理,提供一个全面、系统且可实践的知识框架。
一、上下文的重新定义
在大型语言模型(LLM)的世界里,“上下文”(Context)是一个无处不在却又极易被误解的核心概念。长期以来,它被简单地等同于模型的“上下文窗口”(Context Window),一个衡量模型一次性可以处理多少文本(以Token计算)的技术参数。然而,随着LLM从实验室走向千行百业的复杂应用,这种狭隘的定义已然成为我们构建更强大、更智能系统的思想枷锁。要真正释放AI的潜力,我们必须首先打破这个枷锁,重新认识上下文的广阔内涵。
1.1 狭义上下文:Token Window作为“技术参数”的时代
在LLM发展的早期,特别是以GPT-3为代表的时代,模型的上下文窗口是其能力最显著的瓶颈之一。一个2k或4k的窗口,意味着模型在生成下一个词时,只能“看到”紧邻的几千个Token。这就像一个记忆力只有几分钟的对话者,虽然能在短时间内展现出惊人的语言天赋,但稍微复杂的任务、稍长一些的对话,就会让他“忘掉”了开头,迷失了目标。
在这个阶段,所谓的“上下文工程”几乎等同于“窗口管理术”。开发者们绞尽脑汁,试图在有限的窗口空间内,塞进最有价值的信息。这催生了Prompt Engineering的繁荣,其核心任务之一就是在给定的Token预算下,设计出最高效的指令和示例。上下文是一个被动的、需要被精打细算的技术约束,而非一个可以主动设计和利用的战略资源。
1.2 广义上下文:迈向系统状态的整体视角
真正的变革,源于我们将视角从“模型能看到什么”转向“系统能感知和利用什么”。
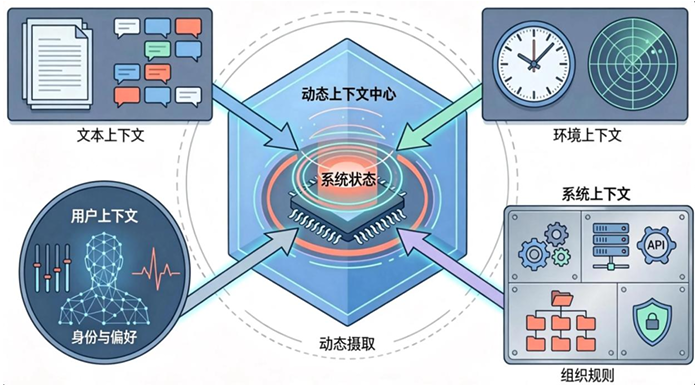
一个先进的AI应用,其智能不仅仅来自模型本身,更来自它所嵌入的整个信息系统。在这个系统中,上下文是驱动模型决策的全部信息流的总和。它是一个动态的、多层次的、结构化的系统状态。我们可以将广义上下文解构为以下五个核心类别:

1.2.1 文本上下文(Textual Context)
这是最基础、最直接的上下文。它构成了模型“工作记忆”的全部内容,是所有推理和生成任务的起点。它不仅包括用户当前的提问(Prompt),还包括:
系统指令(System Prompt):
定义了AI的基本角色、性格、能力边界和行为准则。
历史对话(Conversation History):
确保多轮交互的连贯性。
Few-shot示例:
通过具体的例子向模型演示任务要求。
RAG检索内容:
从外部知识库动态获取的、与当前问题最相关的信息片段。
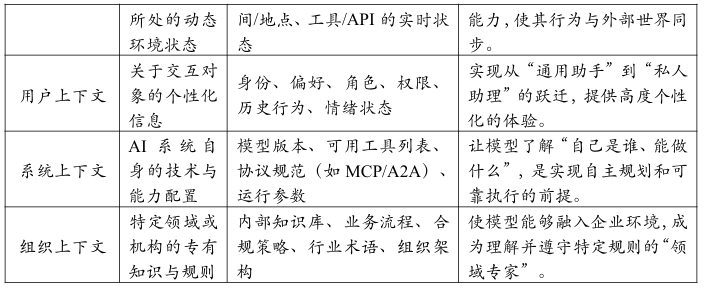
1.2.2 环境上下文(Environmental Context)
如果说文本上下文是AI的“内在思想”,那么环境上下文就是它对“外部世界”的感知。它让AI的行为不再是孤立的文本生成,而是与真实世界状态绑定的行动。例如,一个智能客服Agent需要知道:
任务状态:
当前是在“识别问题”、“查询订单”还是“处理退款”阶段?
会话Session:
当前会话的ID,关联的技术日志,用户的等待时长。
时间与地点:
现在是工作时间还是非工作时间?用户位于哪个时区?
工具状态:
支付API是否可用?物流查询接口的响应延迟是多少?
1.2.3 用户上下文(User Context)
用户上下文是个性化体验的核心。它将AI从一个对所有人都说一样话的“通用模型”,转变为一个懂你的“专属顾问”。这需要系统能够持续地学习和更新关于用户的一切:
身份与角色:
他是普通用户、VIP客户,还是内部管理员?
偏好与习惯:
他喜欢简洁的回答还是详尽的解释?他常用的功能是什么?
历史行为:
他过去购买过什么?浏览过哪些页面?提过哪些问题?
情绪状态:
从他的用词和语气中,能判断出他当前是满意、焦虑还是愤怒?
1.2.4 系统上下文(System Context)
系统上下文是AI的“自我认知”。它需要清楚地知道自己作为一个软件实体的配置和能力。这对于构建能够自主规划和执行复杂任务的Agent至关重要。
模型版本:
我是基于GPT-4.1-Turbo还是Sonnet-4.5?我的知识截止日期是什么?
可用工具(Skills/Plugins):
我能调用哪些API?每个API的参数和功能是什么?
协议规范(Protocols):
我应该如何通过模型上下文协议(MCP)与其他服务交互?我应该如何通过智能体间协议(A2A)与其他Agent协作?
运行参数:
我的Token生成速率限制是多少?当前的安全过滤级别是什么?
1.2.5 组织上下文(Organizational Context)
当AI被部署在企业环境中时,它必须成为组织的一员,理解并遵守其独特的知识、流程和规则。组织上下文就是AI的“入职培训材料”。
知识库:
公司内部的Wiki、产品文档、最佳实践案例。
流程与制度:
如何创建一个工单?一个退款请求需要经过哪些审批?
合规策略:
哪些客户数据是敏感信息,绝对不能在日志中记录?与客户沟通时,有哪些必须声明的法律条款?
行业术语:
在本行业,“SLA”、“ARR”分别指什么?
1.3 范式跃迁:从被动输入到主动经营
将上下文从狭义的“Token窗口”扩展到广义的“系统状态”,带来的绝不仅仅是概念上的丰富,而是一场深刻的开发范式革命。

这场跃迁意味着,我们的核心工作不再是“写出完美的Prompt”,而是“设计一个能为模型持续提供完美上下文的系统”。这个系统能够动态地从不同来源拉取信息,根据任务进展更新其状态,依据用户身份调整其行为,并严格遵守安全与合规的边界。这,就是上下文工程的真正要义,也是通往更高级别人工智能的必由之路。
二、上下文技术的三次飞跃
上下文工程并非一日建成,它的演进与大型语言模型自身的发展紧密相连,是一部从“螺蛳壳里做道场”的精巧技艺,走向构建宏大、复杂信息系统的工程科学史。
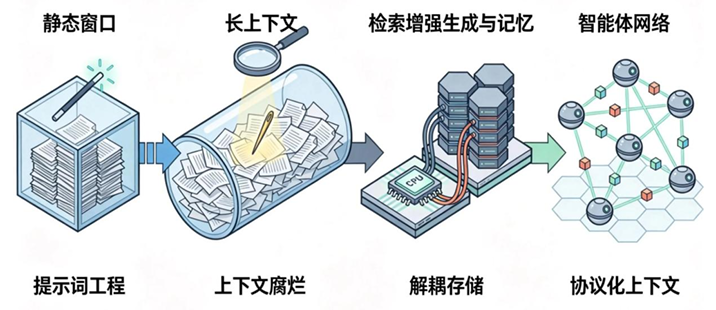
回顾这段历史,我们可以清晰地看到三次关键的范式飞跃,每一次都极大地扩展了我们对“上下文”的认知边界和应用深度。
2.1 静态输入窗口时代(2017–2022):Prompt Engineering的黄金年代
2.1.1 一切的起点:Transformer与有限的注意力
2017年,一篇名为《Attention Is All You Need》的论文横空出世,宣告了Transformer架构的诞生。它彻底摒弃了之前在自然语言处理领域占主导地位的循环(Recurrence)和卷积(Convolution)结构,完全基于“自注意力机制”(Self-Attention)来构建模型。这一设计的核心思想是,在处理一个序列(如一个句子)时,模型中的每个元素都可以直接“关注”到序列中的任何其他元素,并根据相关性权重来计算其表示。
这种架构带来了无与伦比的并行计算能力,使得训练更大、更深的模型成为可能,为后来GPT系列等巨型模型的出现铺平了道路。然而,它也带来了一个与生俱来的“原罪”:有限的上下文窗口。
自注意力机制的计算复杂度与序列长度(即上下文窗口大小)的平方成正比(O(n²))。这意味着,上下文窗口每扩大一倍,计算量和内存占用就会增长四倍。这个二次方的“诅咒”使得早期的Transformer模型,如BERT和GPT-2,其上下文窗口通常被限制在512或1024个Token。这便是“静态输入窗口时代”的技术底色——上下文是一个宝贵但极其有限的资源。
2.1.2 GPT-3的惊鸿一瞥:In-Context Learning的魔力
2020年,OpenAI发布了拥有1750亿参数的GPT-3,并在一篇题为《Language Models are Few-Shot Learners》的论文中,揭示了一种名为“上下文学习”的惊人能力。
在此之前,让模型学会一个新任务,通常需要“微调”(Fine-tuning)——用成千上万个标注好的新数据来更新模型的权重。而GPT-3展示了,无需任何权重更新,仅仅通过在Prompt中提供几个任务示例(shots),模型就能“凭空”学会执行这个新任务。例如,要让它做法语到英语的翻译,你只需要在Prompt里这样写:
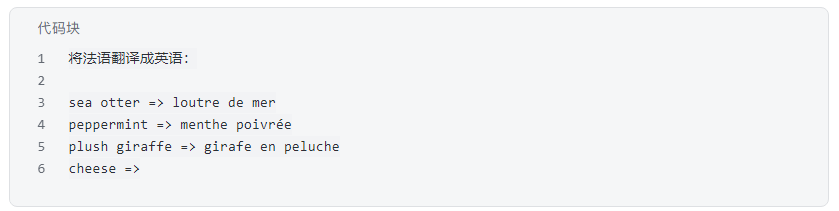
模型就会在“cheese =>”后面,神奇地补完“fromage”。它仿佛从这几个例子中“领悟”到了翻译任务的模式。这种能力,就是In-Context Learning。它极大地改变了人们与模型互动的方式,使得“调教”模型变得前所未有的简单和即时。
ICL的发现,直接催生了“提示工程”(Prompt Engineering)的黄金时代。开发者和研究者们的热情被瞬间点燃,大家开始疯狂探索如何通过设计不同的Prompt来激发模型的潜能。从简单的角色扮演(“你现在是一个莎士比亚风格的诗人…”)到后来的思维链(Chain-of-Thought, CoT),提示工程变成了一门显学。
2.1.3 黄金期的局限:Prompt Engineering的根本困境
然而,在繁荣之下,Prompt Engineering的根本局限也日益凸显。这些局限,本质上都源于其所依赖的“静态输入窗口”。
脆弱性与不稳定性:
Prompt的效果对措辞、格式甚至标点符号都极为敏感。同一个意思的细微表述差异,可能导致模型输出质量的天壤之别。这使得Prompt的开发过程充满了大量的试错,缺乏工程上的确定性和可复现性。
知识的静态性:
Prompt中的知识是“一次性”的。它无法连接到实时变化的世界。如果你的知识库更新了,你必须手动去修改所有相关的Prompt。它也无法处理需要外部数据库或API才能回答的问题。
任务复杂度的天花板:
对于需要多步骤、多工具协作的复杂任务,单靠一个Prompt很难进行清晰的规划和状态管理。随着任务逻辑变长,Prompt会变得臃肿不堪,很快就会撑爆有限的上下文窗口,并且极难维护。
缺乏记忆与个性化:
静态的Prompt是无状态的。它无法记忆用户之前的偏好,也无法在跨会话的交互中积累知识。每一次交互都是一次“冷启动”,这使得提供真正个性化的、持续的服务成为泡影。
研究和实践都表明,单纯的提示工程存在明显的性能上限。当一个任务超出了模型在预训练阶段所“内化”的能力范畴,无论你如何精心设计Prompt,模型都无法完成。就如同一项研究指出的,如果模型没有真正学会某项任务,任何提示都无法让它执行。
正是在这些深刻的痛点驱动下,社区开始意识到,我们不能永远在螺蛳壳里做道场。我们需要的不是更精巧的“咒语”,而是能够突破静态窗口限制、连接外部世界、管理复杂状态的全新方法论。上下文技术的第一次飞跃虽然辉煌,但它的历史使命已经接近终点。一场向着更广阔天地的探索,即将拉开序幕。
2.2 长上下文窗口竞赛(2022–2024):从“寸土寸金”到“军备竞赛”
随着Prompt Engineering的局限性日益暴露,业界和学术界都意识到,要让LLM处理更复杂的任务,必须打破那个该死的O(n²)计算瓶颈,从根本上扩大上下文窗口。于是,一场围绕“长上下文”的技术军备竞赛在2022年左右拉开帷幕。
这场竞赛的目标非常明确:在保持(甚至提升)模型性能的同时,用更高效的算法将上下文窗口从几千个Token,推向几万、几十万,乃至百万级别。这标志着上下文技术的一次重大飞跃,其核心驱动力来自一系列对Transformer底层架构的精妙改造。
2.2.1 解除封印:突破二次方诅咒的关键技术
众多技术创新共同促成了长上下文的实现,其中最具代表性的可以分为三类:
高效的注意力算法(Efficient Attention Algorithms)
FlashAttention:
2022年,斯坦福大学的研究者提出了FlashAttention,这可以说是长上下文革命的“引爆点”。它本身并没有改变注意力的计算逻辑,但通过一种“IO感知”(IO-aware)的设计,极大地优化了GPU显存(HBM)的读写方式。它利用tiling(分块)技术,将巨大的注意力矩阵拆分成小块进行计算,从而显著减少了数据在不同层级内存之间的移动次数。这使得完全相同的注意力计算,速度提升了数倍,内存占用却大幅降低。FlashAttention的出现,让之前因为算力限制而不敢尝试的更长上下文长度,变得触手可及。
更聪明的“位置编码”(Smarter Positional Embeddings)
传统的Transformer需要明确地为每个Token注入其在序列中的绝对或相对位置信息,这被称为位置编码。但当序列变得非常长时,旧的位置编码方法会失效。为了解决这个问题,新的方法应运而生。
旋转位置编码(Rotary Position Embedding, RoPE):
由Google在2021年提出,RoPE通过一种巧妙的数学变换,将位置信息编码到了Query和Key向量的“相位”中。它的优点是具有良好的外推性(extrapolation),即在比训练时更长的序列上也能保持较好的性能,因此被Llama等众多主流模型采用。
线性偏置注意力(Attention with Linear Biases, ALiBi):
由Meta AI在2021年提出,ALiBi更加简单直接。它完全抛弃了在词嵌入阶段添加位置编码的做法,而是在计算注意力分数时,直接给每个分数加上一个与Token之间距离成正比的“惩罚项”(一个负的偏置)。距离越远的Token对,惩罚越大。这种设计天然地赋予了模型一种“关注就近”的归纳偏置,并且外推能力极强,即使在比训练长度长得多的序列上也能稳定工作。
稀疏注意力(Sparse Attention)
另一条思路是,既然完全的“全局注意力”计算量太大,我们是否可以让每个Token只关注一部分“重要”的邻居?这就是稀疏注意力的核心思想。例如,Longformer 结合了局部窗口注意力和全局注意力,让每个Token关注附近的几个词,以及少数几个被设定为“全局重要”的词。BigBird 则引入了随机注意力,让每个Token再额外随机关注几个词。这些方法在特定任务上取得了成功,但因为其“稀疏”的假设,通用性不如前两类方法。
2.2.2 从1k到1M:Token窗口的“通货膨胀”
在这些技术的加持下,上下文窗口的长度开始了一场惊人的“通货膨胀”。
2023年初,主流模型的上下文窗口还在4k-8k的范围。
Anthropic的Claude率先将窗口扩大到100k。
不久,Google在其Gemini 1.5 Pro中展示了惊人的100万Token上下文窗口,并成功通过了“大海捞针”(Needle in a Haystack)测试——即在百万级别的文本中,准确地找到并利用一个被刻意隐藏的“针”(一个特定的事实)。
随后,几乎所有主流模型提供商都迅速跟进,128k、200k甚至更长的上下文窗口成为了旗舰模型的标配。
上下文似乎在一夜之间从“稀缺资源”变成了“无限供应”的商品。这极大地扩展了LLM的应用场景,例如直接处理一整本书、分析数百页的财报、或者消化整个代码库。
2.2.3 “长”的代价:上下文腐烂与注意力稀释
然而,看似无限风光的长上下文,很快也暴露出了其固有的问题。窗口变长,并不意味着模型能同等有效地利用所有信息。一个核心问题浮出水面——上下文腐烂(Context Rot),也常被称为“注意力稀释”(Attention Dilution)或“迷失在中间”(Lost in the Middle)现象。
研究者们通过“大海捞针”测试发现,模型能否找到“针”,很大程度上取决于“针”在上下文草堆中的位置。
当信息位于上下文的开头或结尾时,模型的召回率非常高。
然而,当信息被放置在上下文的中间部分时,模型的性能会急剧下降,仿佛“忘记”了那里的内容。
这种现象揭示了长上下文的一个残酷真相:更长的上下文并不等于更强的理解力。仅仅扩大窗口,而不优化信息的组织和利用方式,就像给一个学生发了一堆没有重点的复习材料,他很可能会“划重点”式地只记住开头和结尾。过量、未经处理的上下文信息,反而会“稀释”掉模型的注意力,使得关键信息被淹没在噪声之中。
长上下文竞赛的实践,让我们深刻地认识到上下文工程的第二个真理:上下文的质量,远比其数量重要。简单粗暴地堆砌信息是行不通的。如何在一个巨大的窗口中,结构化地组织信息,突出重点,引导模型的注意力,成为了新的、更高级的挑战。这直接催生了上下文技术的第三次飞跃——从依赖“内置”的短期记忆,转向构建“外置”的、可持久化的长期记忆系统。
2.3 外部记忆与RAG的兴起(2023–2025):解耦计算与存储
长上下文竞赛很快让业界达成一个共识:仅仅扩大模型的“工作记忆”(即上下文窗口)是远远不够的。一个真正智能的系统,不能只依赖于短暂、易失的在场信息,它还需要一个庞大、持久、可检索的“长期记忆”。这一需求,催生了上下文技术的第三次、也是迄今为止影响最为深远的一次飞跃——外部记忆与检索增强生成(Retrieval-Augmented Generation, RAG)的全面兴起。
2.3.1 RAG的核心思想:解耦“计算”与“存储”
RAG的理念,最早在2020年由Facebook AI(现Meta AI)的研究者提出,但直到2023年,随着LLM应用的爆发,它才真正成为主流。其核心思想优雅而强大:将大型语言模型的“计算”(推理能力)与“存储”(知识)彻底解耦。
在RAG出现之前,我们试图将全世界的知识都“塞”进模型的参数里,通过不断增大模型规模来提升其“博学”程度。这种方式的弊端显而易见:
知识更新困难:
模型一旦训练完成,其内部知识就被固化。要更新知识,就必须进行成本高昂的重新训练。
事实不可靠:
模型在回答时,本质上是在进行“有根据的猜测”,这很容易导致“幻觉”(Hallucination),即一本正经地编造事实。
缺乏透明度:
我们无从知晓模型是根据哪个知识来源给出的答案,无法进行事实核查和溯源。
RAG彻底改变了这一模式。它不再强求模型“记住”一切,而是将模型定位为一个开放式的推理引擎,将知识存储在外部的、可随时更新的知识库中(通常是向量数据库)。当一个问题到来时,RAG系统的工作流程如下:
1.检索(Retrieve):
首先,用用户的查询去知识库中检索最相关的信息片段。
2.增强(Augment):
然后,将这些检索到的信息片段,连同用户的原始问题,一同“增强”到给模型的Prompt中。
3.生成(Generate):
最后,要求模型基于提供的上下文信息来生成答案。
这个简单的流程,却带来了革命性的变化:
知识变得可插拔、可更新:我们只需更新外部知识库,就能实时更新AI的知识,而无需触动模型本身。
答案变得有据可查:系统可以明确地告诉用户,答案是基于哪些文档或数据生成的,大大提升了可靠性和透明度。
成本效益更高:我们可以用一个相对较小的模型,通过外挂一个庞大的知识库,来达到甚至超过一个巨型模型的知识能力。
2.3.2 MemGPT:像操作系统一样管理上下文
如果说RAG为模型外挂了“长期记忆”的硬盘,那么MemGPT则为模型设计了一套先进的“内存管理系统”。2023年,加州大学伯克利分校的研究者提出了MemGPT,其灵感直接来源于计算机的操作系统。
操作系统通过“虚拟内存”机制,让程序感觉自己拥有比物理内存大得多的内存空间。它会自动地在高速但昂贵的物理内存(RAM)和低速但廉价的硬盘(Disk)之间,来回“换页”(Paging),将当前最需要的数据放入内存,将暂时不用的数据存回硬盘。
MemGPT将这一思想引入了LLM的上下文管理。它将模型的上下文窗口视为有限的“物理内存”,将外部的向量数据库或文件系统视为无限的“虚拟内存”。MemGPT赋予了LLM一种“元认知”能力,让模型自己来决定:
何时将信息从主上下文(物理内存)中移出,进行摘要或归档,存入外部的长期记忆(虚拟内存)。
何时需要从长期记忆中检索关键信息,调入主上下文,以辅助当前的任务。
如何与用户互动,以确认哪些信息是重要的,值得被长期记住。
通过这种方式,MemGPT让LLM的上下文管理变得像操作系统一样智能和高效。它不再被动地接收信息,而是主动地、分层地管理自己的记忆,从而在理论上实现了“无限上下文”的能力,即便其物理上下文窗口是有限的。
2.3.3 持久化上下文的黎明
RAG和MemGPT的兴起,标志着用户上下文和组织上下文终于进入了“可持久化、可检索”的长期记忆层。这意味着AI应用第一次有可能构建起真正的、跨越时空的记忆。
对于个人用户:
AI助手可以记住你几周前的工作内容、你的长期目标、你的沟通偏好,从而提供真正连贯和个性化的辅助。
对于组织:
AI系统可以沉淀每一次客户服务的经验、每一个项目的决策过程、每一个团队成员的专业知识,形成一个动态演进、人人可用的“组织大脑”。
上下文不再是一次性交互中的匆匆过客,而是可以被系统性地捕获、存储、检索和利用的宝贵资产。上下文技术的重心,从“如何塞满窗口”和“如何扩大窗口”,演进到了“如何构建和运营一个高效的记忆系统”。这为即将到来的、更高级的智能体时代,奠定了至关重要的基础。
2.4 智能体与协议化上下文(2025–2026):上下文成为主动的、分布式的系统状态网络
随着RAG和记忆系统的成熟,上下文技术正迎来其第四次、也是最具颠覆性的飞跃:智能体(Agent)的普及与上下文的协议化。如果说前三次飞跃的核心是“如何让一个模型看到更多、记得更牢”,那么这一次飞跃的核心则是“如何让众多能够看见和记忆的智能体,安全、高效地协同工作”。上下文的定义,也因此从单个模型的信息输入,演进为整个分布式智能系统中的主动状态网络。
2.4.1 智能体:上下文的终极载体
一个AI智能体(Agent)的本质,是一个能够自主感知环境、制定计划、执行动作以达成目标的系统。在这个定义下,上下文构成了智能体存在的全部基础。一个智能体的上下文,可以被精确地定义为其在某一时刻的完整状态描述,它至少包含:
目标(Goal):
我被要求完成什么?最终的成功状态是怎样的?
状态(State):
为了达成目标,我已经完成了哪些步骤?当前卡在哪一步?
环境(Environment):
我能感知到的外部世界是怎样的?时间、用户、可用资源有何变化?
能力(Capabilities):
我能调用哪些工具(Skills)?每个工具的用途和限制是什么?
这种“上下文即智能体”的视角,意味着上下文管理不再仅仅是为模型“准备资料”,而是要动态地、结构化地维护智能体完成任务所需的全套信息。这要求上下文本身是主动的、结构化的,并且是可被机器读写的。
2.4.2 MCP:标准化“单智能体如何接入世界”
当每个开发者都用自己的方式为智能体提供工具和数据时,整个生态是混乱且不可扩展的。为了解决这个问题,模型上下文协议(Model Context Protocol, MCP)应运而生。MCP由Anthropic等公司在2024年底倡导,旨在为“模型如何与外部工具/数据源交互”提供一个开放的标准。
MCP的核心,是定义了一套标准的“语言”,让任何外部资源(如一个API、一个数据库、一个知识库)都能将自己的能力“自我描述”清楚。这种描述(Schema)包含了:
能力是什么:
工具的功能描述。
如何使用:
调用该工具所需的参数和格式。
能得到什么:
工具返回结果的结构。
通过MCP,一个智能体在需要使用工具时,不再需要开发者为其硬编码一套特定的调用逻辑。智能体可以直接“阅读”MCP服务器提供的能力清单,然后自主决定调用哪个工具、如何传递参数。这使得外部世界的所有资源,都能以一种标准化的方式,动态地成为智能体上下文的一部分。MCP的出现,标志着系统上下文和环境上下文开始被标准化和协议化。
2.4.3 A2A:标准化“多智能体如何互联”
如果说MCP解决了单个智能体“接入世界”的问题,那么智能体间协议(Agent-to-Agent, A2A)则致力于解决“智能体之间如何协作”的难题。A2A协议由Google等公司在2025年提出,其目标是创建一个智能体的“互联网”,让不同公司、不同平台开发的智能体能够互相发现、沟通和协作。
A2A协议的核心是定义了一套标准的会话消息结构,其中包含了任务协作所需的关键上下文信息:
目标(Goal):
我希望你帮我完成什么任务?
上下文(Context):
为了完成这个任务,你需要知道的背景信息、数据和我已经完成的步骤。
能力(Capabilities):
在这次协作中,我授权你可以使用我的哪些能力或资源?
结果(Result):
任务完成后的交付物应该是什么格式?
通过A2A,一个复杂的任务可以被分解给多个各有所长的专业智能体。例如,一个“旅行规划总管Agent”可以:
向“机票查询Agent”发起请求,并传递目的地和时间作为上下文。
从“酒店预订Agent”那里获取符合预算的酒店列表。
将机票和酒店信息,连同用户的饮食偏好,一同作为上下文发送给“当地美食推荐Agent”。
在这个过程中,每个智能体都只暴露完成协作所必需的上下文“切片”,而无需暴露自己的内部状态和全部记忆,从而保证了安全和隐私。
2.4.4 去中心化的上下文网络
MCP和A2A的结合,预示着一个去中心化的上下文网络的未来。在这个网络中,每个智能体都是一个独立的节点,拥有自己的本地上下文(记忆、技能)。同时,它又能通过标准协议,动态地引用和调用网络中任何其他节点的能力和上下文。
上下文不再是集中存储、由单一应用管理的“数据”,而是像互联网上的信息一样,成为一种分布式的、可链接的、按需流动的状态资源。一个任务的完成,可能是由网络上数十个智能体接力完成的,每一次接力,都是一次结构化上下文的传递和演进。
至此,上下文技术的演进完成了从“静态输入”到“动态网络”的四次飞跃,为我们今天所讨论的、宏大的“上下文工程”学科,铺就了完整的技术和思想基石。
以上内容为
《大模型上下文工程(Context Engineering)指南》
的部分内容节选,完整版指南请扫描下方二维码下载。

END
0
举报
声明
收藏
分享
相关推荐

















评论你的想法~
表情
喜欢TA的作品吗?喜欢就快来夸夸TA吧!
推荐素材
























你可能喜欢













相关收藏夹
























登录注册
推荐登录即可同步推荐记录哦
收藏登录即可加入我的收藏
评论登录即可评论想法
分享分享