草坪档案|优酷虚拟人YUMI的偶像之路

北京/艺术工作者/1年前/915浏览
版权
草坪档案|优酷虚拟人YUMI的偶像之路
优酷虚拟偶像YUMI,是由人工草坪 AI Design Lab 团队参与负责的AI数字人项目。作为超写实数字人,YUMI拥有青春甜美的长相,并具备多项AI技术能力。本文将全面介绍YUMI的设计流程和业务场景,希望在内容直播、短视频和影剧综等方面,有更多AI创新能力产生。


· YUMI人物简介
YUMI是阿里大文娱集团的AI虚拟偶像。YUMI不仅是偶像女团的一员,同时也是优酷的签约主播和歌手。她喜爱与人聊天,擅长唱歌跳舞。YUMI的身后,是阿里语义大模型通义星尘、形象驱动引擎和AI声音模型等技术的共同支持。
· YUMI人设定位

作为虚拟偶像,来听下YUMI在直播间的自我介绍吧:
“Hello,大家好!我是AI虚拟偶像YUMI~我是2003年3月5日出生于上海。双鱼座的我多愁善感,情绪细腻,喜欢新鲜事物和与人聊天。我的幸运色是海洋蓝和紫色,爱好是拉大提琴和花样滑冰,最喜欢的食物是生煎包。我的职业是优酷的情感主播、原创歌手和舞者,大家快来关注和支持我吧~”
我们希望赋予YUMI青春偶像少女的人物设定,和甜美纯欲的形象。符合20-45岁主流人群的审美的同时,能以写实数字人的实现方式,带给人们亲和力和真实感。根据YUMI人设来训练AI语言模型、声音模型,并指导妆造穿搭和后期内容创作。
· YUMI业务方向
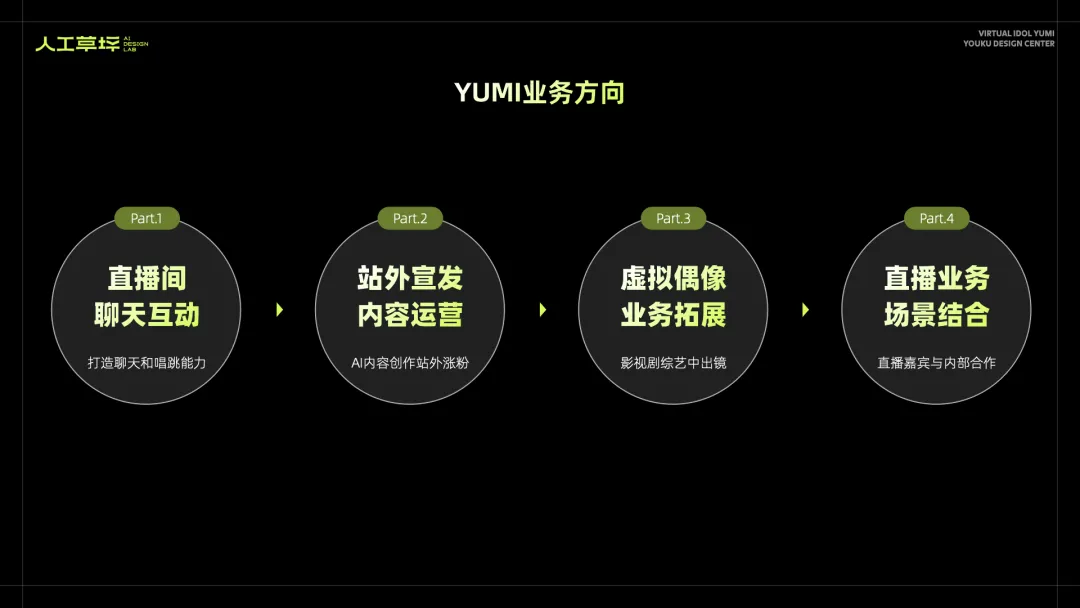
YUMI虚拟人项目在2023年10月后正式启动,根据业务目标和AI技术能力的发展,大致分成4个方向,并逐步推进落地:
1)优酷直播:打造可以实时聊天、互动点歌和跳舞的AI直播间。
2)站外宣发:通过AIGC的内容生产方式,实现YUMI在站外流量建设和涨粉。
3)业务拓展:在优酷的影视剧和综艺中出镜,成为虚拟演员和嘉宾。
4)直播结合:在优酷综艺中出席飞行嘉宾并参与互动;为YUMI开一场线上演唱会。

· 人脸和形象设计
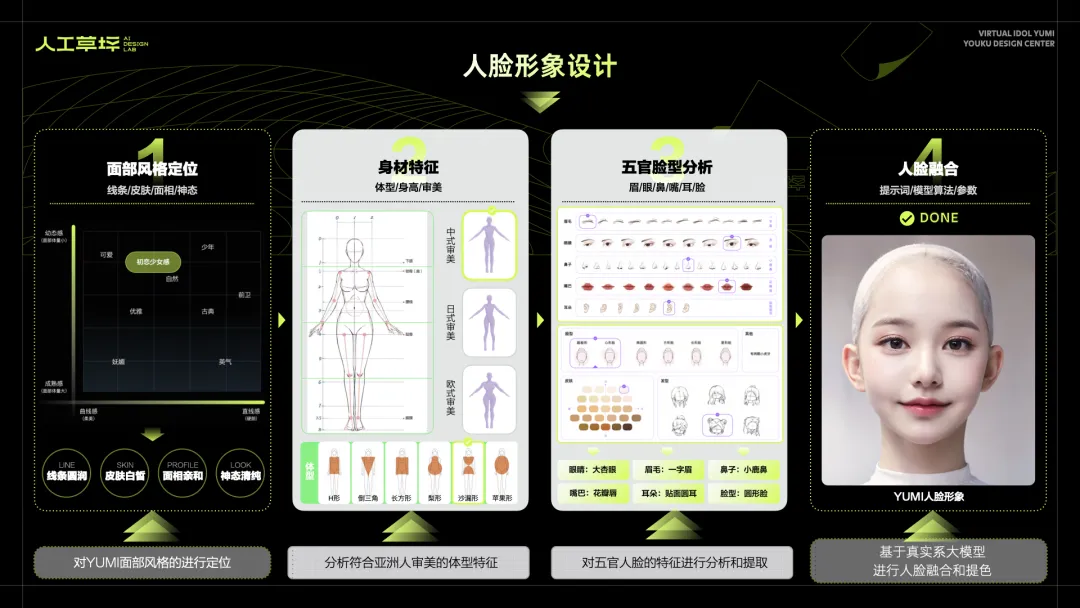
对于一个偶像IP来说,人脸形象的设计是非常关键的第一步。通过前期的调研,我们对YUMI面部风格进行分析和定位,并选定符合她的身材体型特征。通过筛选眼睛、鼻子、嘴巴和脸型特征,确定了YUMI面部形象的风格。面部形象确定后,需要使用SD炼制高质量的人像LORA,做最终的人脸融合使用。以上是形象设计的准备工作。
由于YUMI的形象是超写实数字人,在SD训练上推荐使用真实系大模型来调试。在形象融合中,使用多款人脸LORA并不断调整权重参数,得到YUMI较满意的五官形象。另外,要通过正向提示词控制YUMI的面妆、皮肤质感、面光和发型等,使用Controlnet精准控制人物的动作和面部表情。
在不断地调整和抽卡过后,YUMI的最终形象诞生了!保留好所有的提示词参数和种子,确保YUMI形象稳定和人物灵活调整。
· 妆造与穿搭定位

完成形象设计,下一步是YUMI的妆造和穿搭。作为AI虚拟主播,在直播间里与观众互动是主要的场景。妆造和穿搭的亲和力,能拉近YUMI和观众的距离,让聊天更具吸引力。竖屏直播流9:16的比例,能更好展现YUMI的穿搭和身材。

来聊下YUMI主播的基础造型。YUMI作为甜美温柔的女主播,选择长发和自然棕作为发型的风格。妆容上,选择韩系的少女妆看起来更自然有活力,突出白嫩感(小编很喜欢的风格)。在穿着上,选择甜美元气系的韩系连衣裙,更能突出YUMI的时尚感和苗条身材。衣服尽量挑选修身收腰的款式,珍珠耳环的点缀,更加凸显偶像魅力。
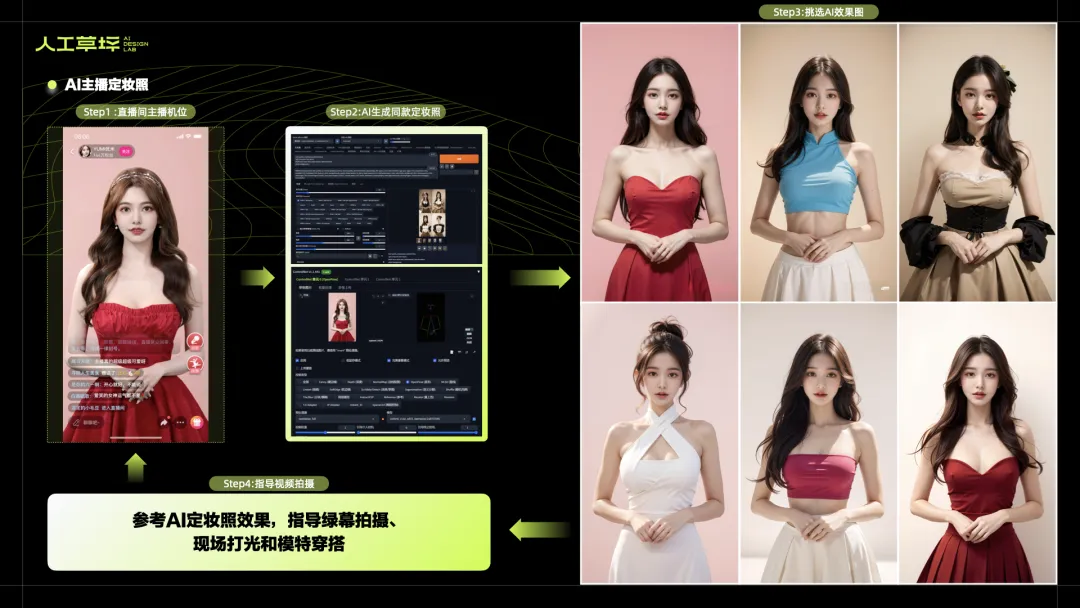
想提前看到YUMI妆造和穿搭在直播间的效果,AI生成定妆照是个好的办法。在SD中,首先使用YUMI的人脸LORA,保持形象的稳定;根据挑选的服装照片,让AI生成同款服装;使用直播间YUMI的最佳身位,作为Openpose的骨骼图锁定人物姿态;在提示中控制背景、光照、妆造和配饰,这样YUMI主播各衣服的定妆照就完成了。这对后期YUMI直播造型和录制素材,起到指导作用。
· YUMI形象模型与驱动
YUMI人脸模型的训练,主要是基于DFL技术。传统的DFL人脸模型训练过程,需要采集真人的面部各角度的视频,并且要录制真人各种表情,以满足训练集和后期影视人脸驱动的需要。通过DFL技术,可以做到高清晰度人脸融合,驱动速度可到达直播的级别。这也为YUMI出镜综艺互动和线上演唱会直播,提供了技术的可能性。
YUMI前期的采集方案,主要是通过单图融合和SD重绘的结合。DFL人脸模型,可以持续补充素材提高训练精度。


· 定制一款甜美的声音
YUMI音色的定位,可以概括为青春、活力和甜美。作为2003年出生的女团偶像练习生,声音的年龄和质感都要符合,同时也决定了唱歌的音色和美感。经过了对声优的筛选,录制了2小时以上的声音素材进行训练。这里使用的是阿里云的TTS音色模型技术,下面的视频是使用声优的原声驱动的。
· AI语义模型塑造人设
YUMI语言模型的定制,同样是基于阿里云通义星尘的语义大模型进行训练,分为几个阶段。首先,为YUMI撰写她的自我介绍,并喂给语义模型。用户在提问YUMI个人问题时,能有统一的人设回复。然后,作为优酷的主播,被问到最多的还是优酷影剧综相关的问题。将优酷影视剧相关的资料,整合成语义模型的素材做训练,这样YUMI就能准确地和用户探讨优酷的剧情了。最后,YUMI回答问题的语言风格,还要经过不断的指令调整,到达适合口播驱动的程度。
总结一下,YUMI虚拟人的实现包含形象LORA、DFL人脸模型、音色模型和AI语言模型的训练。完成这4个部分,就基本满足优酷站内直播和站外内容生产的基础能力了。


· 直播聊天与实时驱动
YUMI虚拟偶像的第一站,是成为优酷直播平台的AI虚拟主播。YUMI直播间在2023年12月25日正式上线,打造了国内第一个可实时聊天的超写实虚拟人直播间。我们来欣赏下YUMI在直播间互动聊天的表现吧。

YUMI直播间的亮点,是AI虚拟人的互动玩法创新。怎样让YUMI的直播内容更具吸引力呢?为YUMI主播规划6个AI直播能力:直播聊天、剧集讨论、互动点歌、打赏跳舞、日常换装和AI装扮礼物。主要讲下后4个互动能力的方案。

· 互动点歌玩法
互动点歌玩法,作为一个的亮点功能,既能展现YUMI偶像歌手的魅力,又能大幅提高互动率。用户在直播间主动选择“点歌”功能,YUMI会准备多首歌曲,每种歌曲演唱需满足互动条件。比如收到50个比心礼物,或是触发100次“YUMI真美”的热词。用户根据想听的歌曲,达成相应的互动条件,就能听到YUMI的真情献唱了。另外,大家会为同一首歌贡献自己的力量,一首歌也会演唱多次。
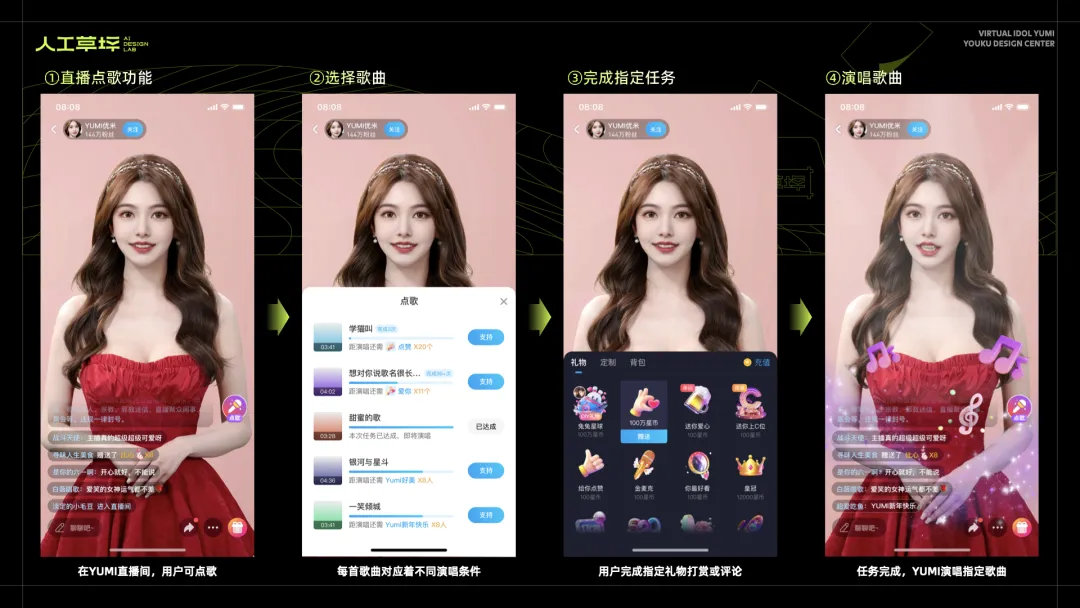
YUMI直播唱歌的实现方式,是又一个技术难点,这里概括为3个部分:
首先,我们要为YUMI这位虚拟偶像,量身定做属于她的原创歌曲。歌曲制作方面,我们先和原创音乐人合作,为YUMI写歌。邀请YUMI的声优,在录音棚完成YUMI的歌曲录制和编混。
歌曲有了,下一步是YUMI如何在直播间演唱。想要直播演唱效果好,YUMI直播模型的驱动是关键的一步。在同一直播间完成聊天和唱歌无缝衔接,需要使用同一个YUMI形象模型进行驱动。在制作模型的素材采集和训练时,就要保证演员视频的口型和姿态,能自然匹配说话和演唱两种形态。后期的YUMI唱歌的口型训练也是必不可少的。
直播演唱时的氛围,同时需要量身设计。在YUMI演唱时,精美的唱歌动效能大幅提升歌曲的视听效果,氛围感拉满。
· 直播跳舞打赏
YUMI在直播间的打赏跳舞,是另一种创新互动玩法。为确保YUMI跳舞时的形象统一,同样使用红裙子模型作为驱动的素材。介绍下YUMI舞蹈的生成方式,这里使用的是阿里云的AI图片驱动技术:
①选取YUMI跳舞的视频素材,视频中舞者的最好是全身,舞蹈幅度小便于驱动;
②选取视频单帧,抽取骨骼图,通过AI重绘成YUMI的形象。直播间使用红裙子的单帧即可;
③使用视频素材的骨骼动画,对YUMI形象图片进行驱动,制作视频。
· 直播换装玩法
换装直播和AI虚拟人的结合,是不错的创新点。在直播模型的过程中,我们拍摄了红色、蓝色、白色三套不同的视频素材,经过训练制作了3套可直播驱动的模型。YUMI日常直播,可定期(每3天)更换妆造开播,也可以结合节日或主题定制妆造模型。另一种直播玩法,是通过用户打赏或达成换装任务,解锁YUMI直播换装。从实现和效果角度,后台切换妆造模型后,语音回复状态和互动唱歌可无缝衔接,做到丝滑换装的效果。
· 直播氛围装修
YUMI直播间装修设计,可提升观看效果和氛围感。在日常直播中,根据YUMI的姿态和妆造,对直播间进行装饰。特殊节日或活动时,比如圣诞节、万圣节和春节,可以通过装修设计图层,营造很好的视觉观感和趣味性。方案目前还在优化中,敬请期待。
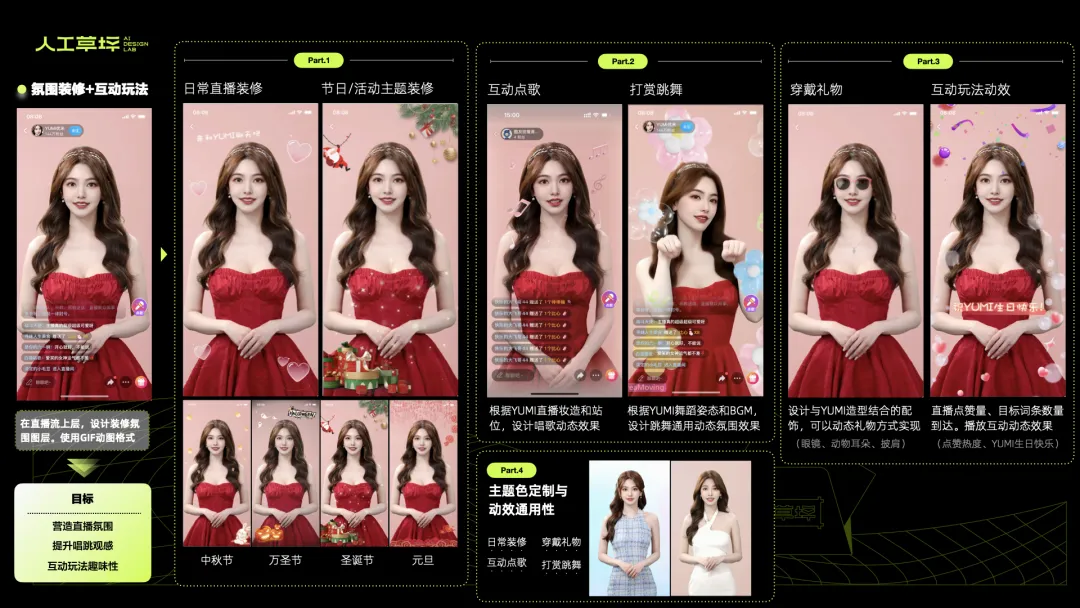
· AI定制礼物
AI直播定制礼物,将传统穿戴礼物和YUMI的形象做结合,提升用户互动和打赏。以AI墨镜礼物为例,送给YUMI后,可穿戴10秒并跟随YUMI头部一起运动。这里要用到人脸面部追踪技术,同时AI礼物的与YUMI的搭配和动态效果,也是设计实现的关键。

· 央视栏目虚拟嘉宾
2023年央视《华语音乐打歌中心》的第一期节目开始,YUMI以虚拟打歌嘉宾的身份首次公开亮相。节目直播中,主持人祝嘉伟和YUMI通过在线连麦的方式进行互动。提问了本期嘉宾陆翊的3个问题,YUMI都给出了满意的回复,口型表情和姿态也比较自然。YUMI成为央视栏目常驻的虚拟嘉宾,同时也为日后出镜优酷的综艺节目提供的宝贵经验。YUMI直播唱歌的能力在3月份上线,今后出镜嘉宾可以在线连麦演唱了。期待YUMI在央视栏目的歌曲首秀。
· 短视频内容策划与拍摄
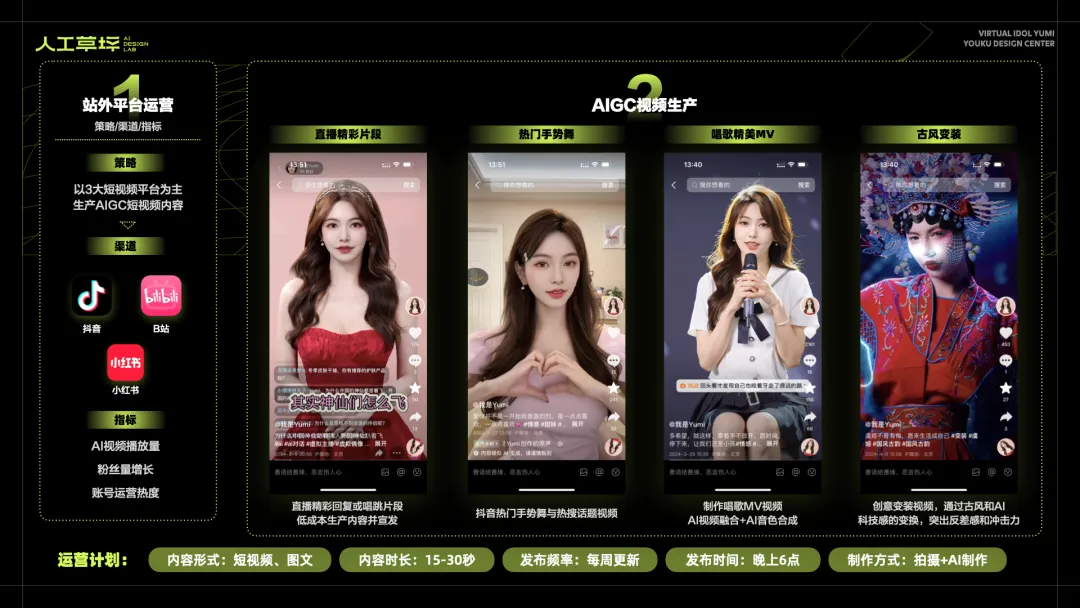
YUMI的站外内容运营,以抖音、B站和小红书三家短视频平台为主。站外运营的目标,主要为提升AI视频播放量、帮助YUMI涨粉和提高账号热度。通过短视频内容的创作,让YUMI的偶像人设更加深入人心,也能有好的宣发作用。YUMI视频制作,采用演员拍摄+AI视频制作的方式。内容形式有日常旅拍、热门手势舞、原创MV和最近较火的AI变装视频,时长在15-30秒之间,持续每周更新。
截止5月初,"我是Yumi"的抖音账号,拥有6.0万粉丝量,总获赞30万+,单条最高播放27万。分享2个YUMI视频创作的经验。一是视频内容最好紧扣平台热点,上热搜后播放量大幅提升;二是视频拍摄时,尽量避免有面部的遮挡,否则会对视频制作和后期调整带来困难。
当账号的粉丝和播放足够高时,YUMI会尝试接抖音的商单。今年5月,YUMI将会在抖音直播间与大家见面,功能还在开发中。

· YUMI设计的复用性
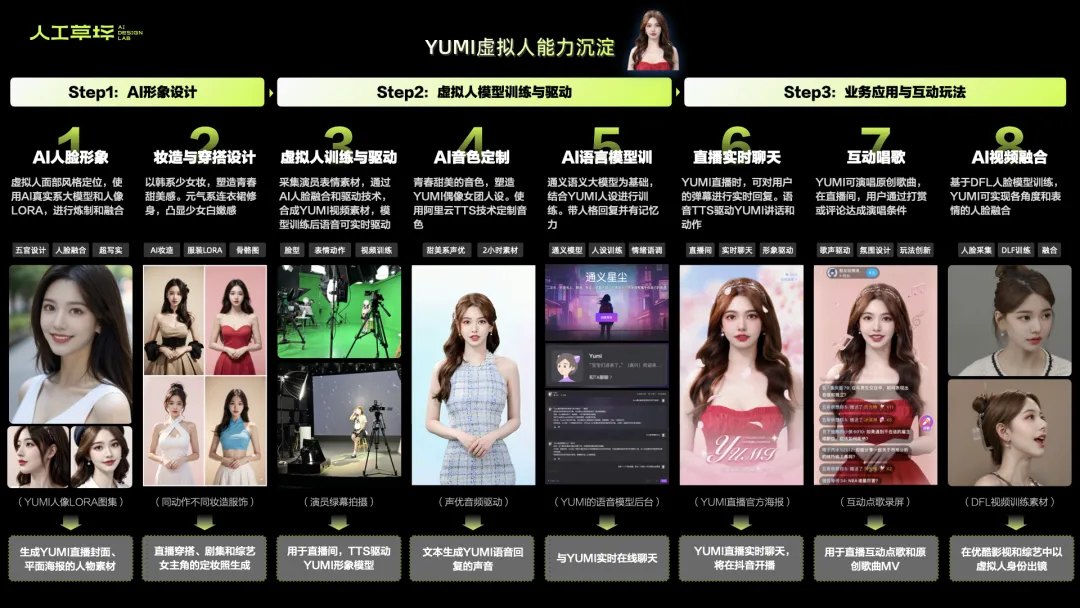
在文章的最后,我们来总结下YUMI虚拟人在直播、短视频和影剧综业务中,可以沉淀的AI设计和技术能力。小编归纳了8个方面:
①AI人脸设计:通过真实系大模型和人像LORA的提炼融合,可生成稳定的人脸形象IP,也可根据选角的需要,定制人脸形象库。
②妆造与穿搭:根据YUMI的人设和出境场景,AI生成定妆照。结合服装LORA可以生成YUMI多角度同款服饰的照片。
③模型训练与驱动:虚拟人直播和视频的形象模型,采用演员视频拍摄+AI融合驱动的方式制作。使用文本或语音都可实时驱动模型。
④AI音色定制:选取符合人设的声优,采集2小时陈述、高兴等情绪的中英文念稿音频,使用TTS技术进行训练。
⑤AI语言模型:这里以通义语言大模型为基础,给到AI人设信息和文本资料(如优酷的剧集库信息),完成小语言模型的训练。
⑥直播实时聊天:YUMI直播聊天,打通了用户发送弹幕到AI口型动作驱动的全链路,时长控制在8-12秒。实时回复能力可复用给任何AI虚拟主播。
⑦互动点歌:YUMI具备歌声驱动的能力,并与直播打赏任务结合,打造AI互动新玩法。虚拟人的唱歌能力,可复用给任何AI主播使用。
⑧AI视频融合:YUMI的DFL模型,正在为影视级人脸融合进行训练。当跑通一套效果满意的视频制作流程后,可复用给任何AI人脸形象,并为优酷影剧综建立AI选角形象库。
· 虚拟人的业务拓展

虚拟人在文娱业务的拓展上有3个较明确的方向,需要在AI驱动、人像模型技术成熟后,随业务场景逐步落地。
首先,作为偶像女团的YUMI,在形象设计和模型驱动,已有较稳定的流程。可以按YUMI的方式,设计其他虚拟女团成员。虚拟偶像团体,可以产生更多的AI内容和创新玩法。
YUMI在直播业务中有很多可结合的场景。比如预售直播间,YUMI可以介绍演出详情并带货演出门票;在点映礼直播,YUMI可参与讨论剧情和互动;在综艺中,出席飞行嘉宾;在元旦春节晚会上,客串虚拟主持人等。
最后,在优酷的影视剧中出演女主角,算是YUMI的终级理想了。AI虚拟人与影视生产的结合,YUMI正在慢慢尝试。每种业务场景的结合,既是虚拟偶像互动玩法的创新,也是对技术和体验的新挑战。
4
举报
声明
7
分享
相关推荐

















评论你的想法~
表情
喜欢TA的作品吗?喜欢就快来夸夸TA吧!
推荐素材
























你可能喜欢














相关收藏夹

























登录注册
4登录即可同步推荐记录哦
7登录即可加入我的收藏
评论登录即可评论想法
分享分享