小白必看的Stale Diffusion原理及云端部署

北京/设计爱好者/2年前/239浏览
版权
小白必看的Stale Diffusion原理及云端部署

前言
什么是Stale Diffusion?
Stale Diffusion 是唯一能实现精准控制生成图像的本地化部署成熟的AI绘画工具
它是一个文本到图像的生成模型
,
是
由 StabilityAl, CompVis 和 Runway 合作开发,并由 Eleuther AI 和 LAION 提供支持,训练数据是 LAION 的开源数据。
你可能听过 Stable Diffusion, Latent Diffusion Model 等,对于不熟悉的朋友可能比较混乱,先来说一下他们的关系。
首先是 Diffusion Model,中文叫做扩散模型,目前的Midjourney,Stable Diffusion 图片生成的核心都是扩散模型,Latent Diffusion Model,中文叫潜在扩散模型,是扩散模型的一种变体,最大的区别是他是先把图片压缩,降低维度,压缩后的空间叫做潜在空间,也就是 latent space,这么做的好处是可以大幅度减少计算量,而Stale Diffusion就是基于Latent Diffusion Model开发出来的,这也是他可以在普通GPU上运行的原因。而
Stale Diffusion WEB UI则是在Stale Diffusion基础上开发的应用,他把原本繁琐的安装配置做成了容易操作的网页界面,并且后续加入了很多插件
,是的他成为了最受欢迎的基于Stale Diffusion最受欢迎的应用。
Stable Diffusion原理
Stale Diffusion大致由三个模型组成,首先是一个CLIP模型,在这里用它的文本编码器,把文字转換成向量作为输入。然后就是扩散模型,用来生成图片,因为他是在图,片压缩后降维后的潜在空间进行的,所以扩散模型的输入和输出,都是潜在空间的图像特征,而不是图片本身的像素。最后一个是VAE模型,用他的解码器把潜在空间的图像特征转换成图片。
Diffusion 模型(U-Net + Scheduler)的原理,首先给一张图片,在这张图片上,我们随机的添加一些噪声,一步一步加上去,直到只剩下噪声,然后我们再训练一个网络,把它从噪声一步一步还原到原来的图片。为什么要这么麻烦一步一步添加噪声,而不训练一个网络,直接一步到位呢,因为直接移除像素会导致信息丢失,添加噪声可以让模型学习到图片的特征,而且随机噪声还增加了模型生成的多样性,而一步一步来可以控制这一步的过程,同时提高了去噪过程的稳定性。那么每一步要增加多少噪声呢,这个根据计划来决定,不同的工作计划有不同的方法,可以是每次相同的量,也可以一开始加的少后来加的多,先少后多比较好,这样图片特征损失比较慢,因为高斯噪声可以直接加在一起,并不真的需要一步一步加上去,所以训练的时候直接把随机数量的噪声添加去图片进去,让训练的网络还原图片。我们看看还原图片的过程,首先我们从训练数据里拿一张图片,在里面添加一定量的噪声,假设添加步数等干50的时候的噪声,然后我们有一个U-Net 神经网络,通过输入图片和步数50,可以预测出图片中的噪声,输入步数50是因为这个网络是每一步都共用的,所以要让它知道目前前预测的噪声数量大概是多少,选用U-Net结构的网络来预测是因为它的效果比较好,现在我们只需要把有输入的图片减去噪声就能得到原图,但是当噪声很多的时候网络并无法顸测精准的图片细节,只能预测一个很模糊的大概的轮廓,这时候我们把它当作原图,然后再添加此之前少一点的噪声进去,然后在预测他的噪声,这样不断重复直到得到原图。
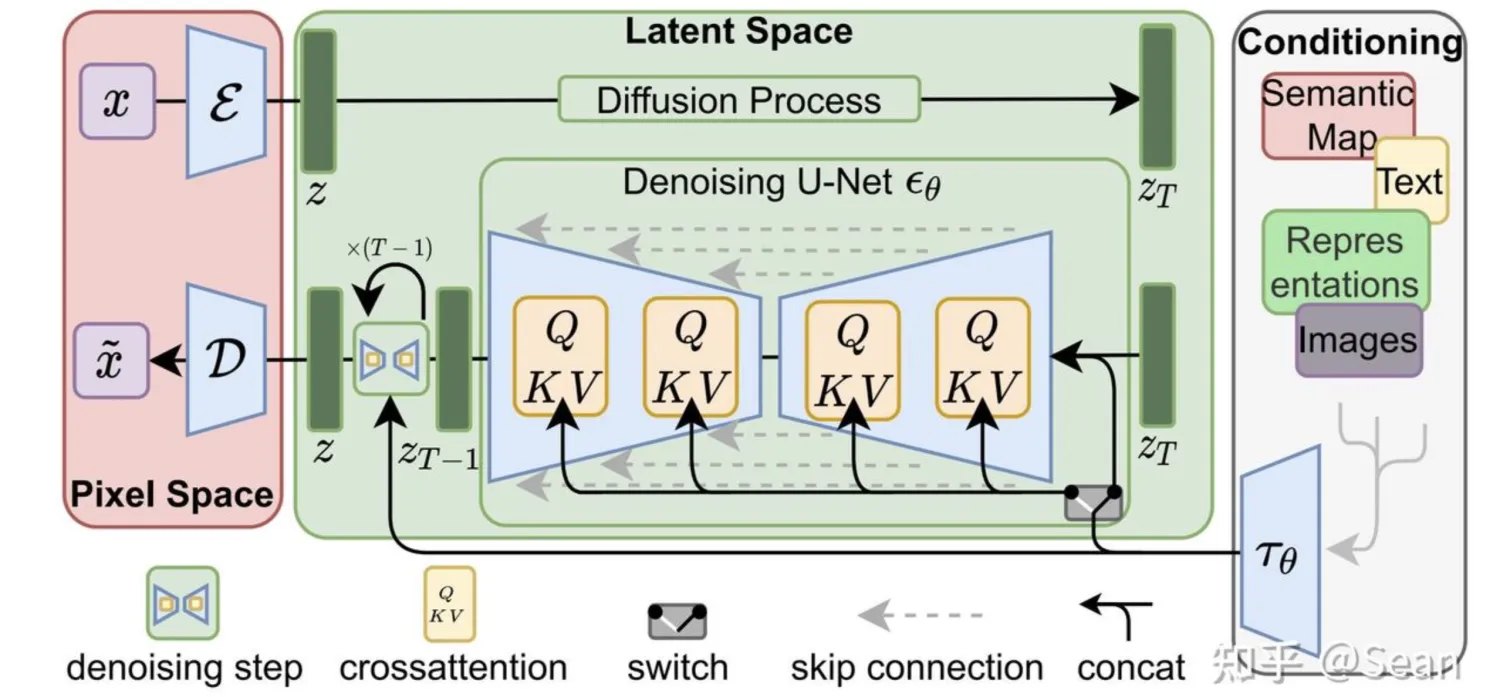
所以Stale Diffusion里训练的时候是先用
VAE的编码器
把图片压缩到潜在空间,然后在潜在空间里训练扩散模型,扩散模型的输入输出都是潜在空间里的特征,而不是图片本身的像素,在推理的时候,也就是在生成图片的时候,他一开始的随机噪声也是在潜在空间里生成的。用VAE的好处是可以大大减少训练和推理的时间和硬件要求。因为本来训练的图片是 512x512,压缩后是64x64,減少了很多。有好处当然也有坏处,因为是压缩过再还原,不多不少都会损失掉一些细节,顺带一提VAE 是预先训练好的,扩散模型训练的时候直接拿来用。
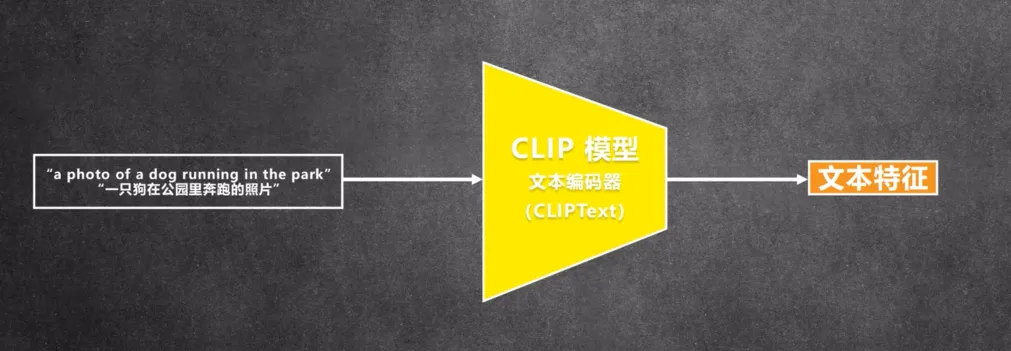
CLIP
是用文字和图像做对比的预训练模型,它的作用就是把文本和图像联系起来,clip 是由一个文本编码器和一个图像编码器组成,它的训练集也是文字图片组,训练的时候用一组组文字图片对作对比,经过编码器分别得到文本特征和图像特征,然后计算两个特征的相似度,训练好以后对应的文字图片相似度会很高,不对应得则很低,这样就可以把文字和图片联系起来,Stable Diffusion 里是直按用 OpenAI 训练好的 clip 模型,cip 模型虽然是 openAI开源的模型,但是它的训练集沒有公开,所以 Stable Diffusion 2 版本換成7另一个 clip 模型,LAION 的 OpenCLIP 模型,训练集用的LAION 的开源数据,Stable Diffusion 里只用了cip 里的文本编码器,沒有用到图像编码器。
整个Stable Diffusion 的结构总结,首先是把训练的模型经过VAE解码器压缩降维到潜在空间,然后根据 scheduler 来添加噪声,之后就从噪声开始推理,把噪声和t都输入到U-Net里,同时把文本引导经过 clip 编码器也输入到U-Net里,U-Net 预测噪声后经过计算得到前一步的噪声图,这样一直重复t步直到得到沒有噪声的图像特征,最后经过 VAE 解码器还原成图片,Stable Diffusion 最不同的是把图像从像素空间压缩到潜在空间处理,训练好以后生成图片只需要下半部分的反向扩散过程就行,随机生成噪声再推理。条件引导不一定是文本,其他的都可以转成特征去引导,以上就是Stable Diffusion的原理啦。
Stable Diffusion的使用
要用上 Stable Diffusion ,有本地部署和云端部署两种方式使用。
按目前的经验来看经验看本地部署的一键整合包要比云端部署的整合包错误更少,自由度更高,win系统操作也比云端的Liunx系统更方便,能本地部署的尽量本地部署。
但本地部署对于电脑硬件有较高的要求,MAC电脑全系列体验不佳,Win 电脑也需要 NVIDIA 卡且显存大于等于8G才会有不错的体验,所以云端部署对于没有高配Win的同学来说仍然是一个不错的选择。
本地部署
本地电脑部署对于配置的要求上文已经提过,对于 SD1.5 版本模型来说,6G 显存起步,8G 体验还行,12G 以上畅玩。对于 SDXL 新版模型来说,8G 显存起步,16G 体验还行,24G 以上畅玩
显卡以N卡为佳,符合配置需求的同学按教程下载安装整合包就可以,顺利的话不会遇到报错。
如何云端部署
关于云端部署有几个平台,AutoDL、青椒云、以及MegaeaseAutoDL、
https://www.autodl.com/home适合不怕麻烦,不想花太多钱的人,显卡选择多样,但显卡抢购较为困难,使用完毕后及时关机以避免不必要的费用,30天不使用实例会被释放,请及时保存重要图片。青椒云
http://account.qingjiaocloud.com/signin?inviteCode=3OF611IT线上部署,方便省心,需要支付费用,注意畅抒己见不使用会释放桌面,请及时保存重要信息Megaease相对来说这个较为稳定,且较为易用的平台。
要用上 Stable Diffusion ,有本地部署和云端部署两种方式使用
按目前的经验来看经验看本地部署的一键整合包要比云端部署的整合包错误更少,自由度更高,win系统操作也比云端的Liunx系统更方便,能本地部署的尽量本地部署。
但本地部署对于电脑硬件有较高的要求,MAC电脑全系列体验不佳,Win 电脑也需要 NVIDIA 卡且显存大于等于8G才会有不错的体验,所以云端部署对于没有高配Win的同学来说仍然是一个不错的选择
本地部署
本地电脑部署对于配置的要求上文已经提过,对于 SD1.5 版本模型来说,6G 显存起步,8G 体验还行,12G 以上畅玩。对于 SDXL 新版模型来说,8G 显存起步,16G 体验还行,24G 以上畅玩
显卡以N卡为佳,符合配置需求的同学按教程下载安装整合包就可以,顺利的话不会遇到报错
Megaease云端部署
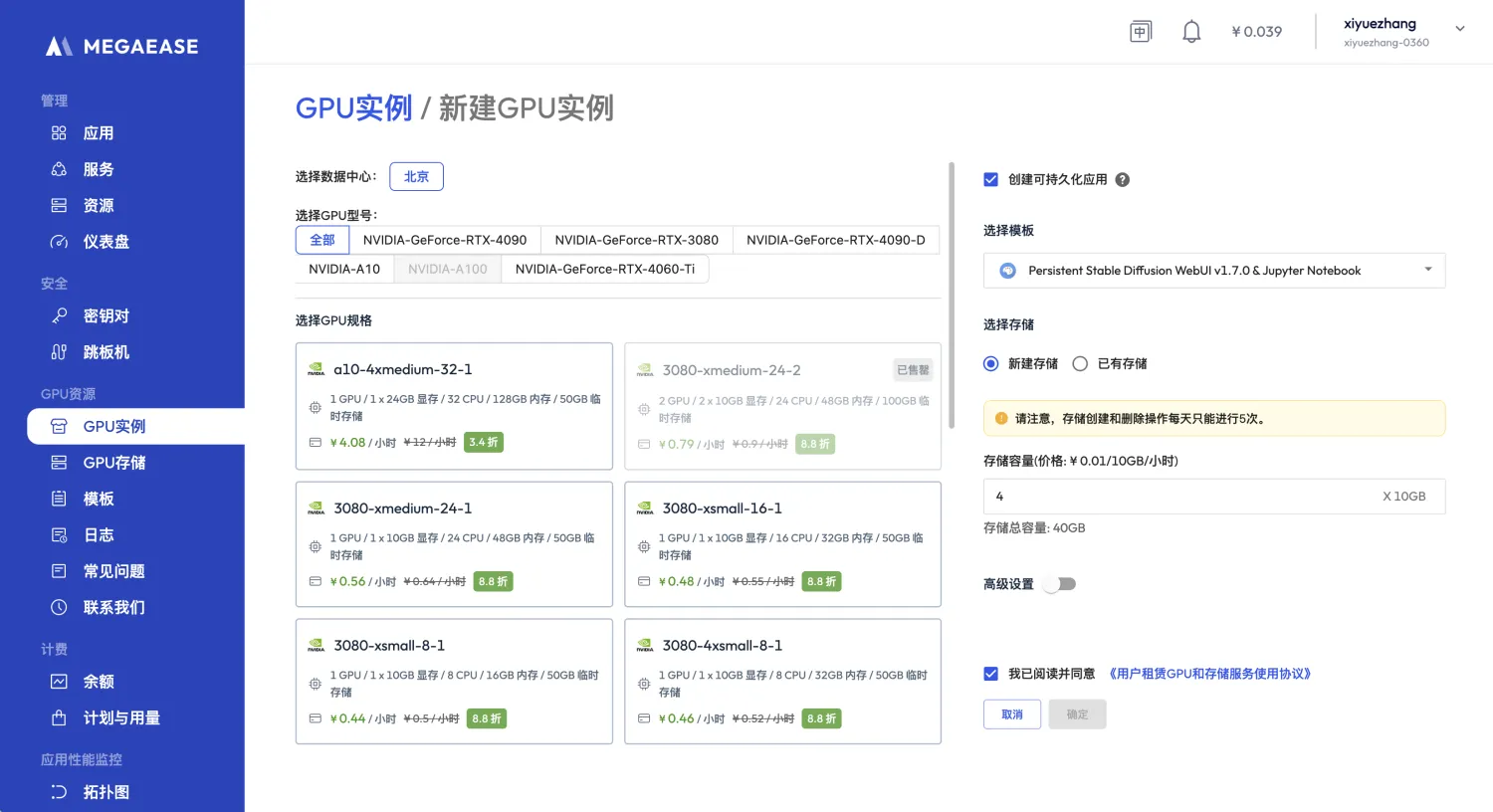
步骤一
选择显卡
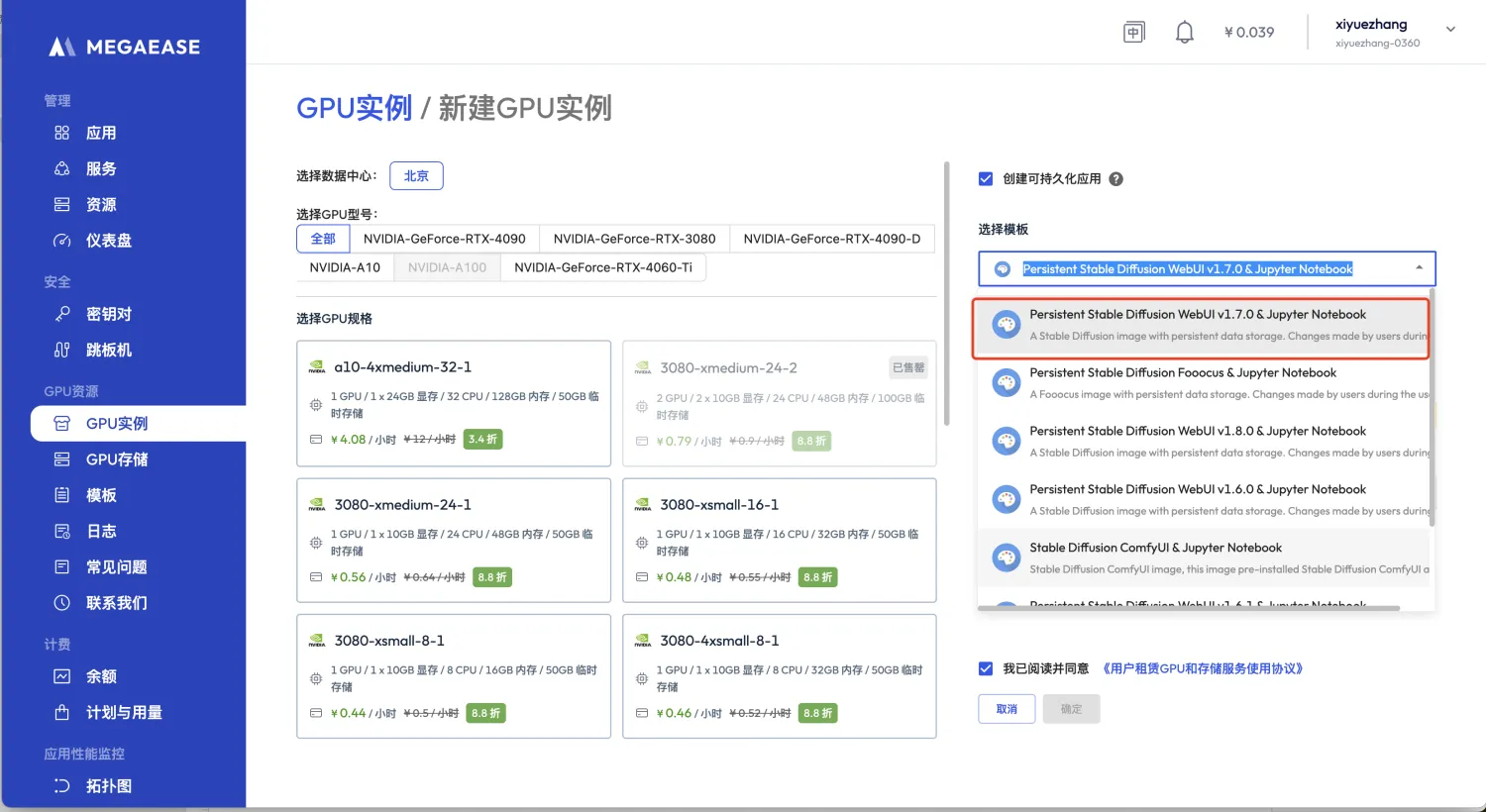
步骤二
选择【模板】,勾选创建可持久化应用
步骤三
点击【操作】【详情】,这一步要等的时间久一点
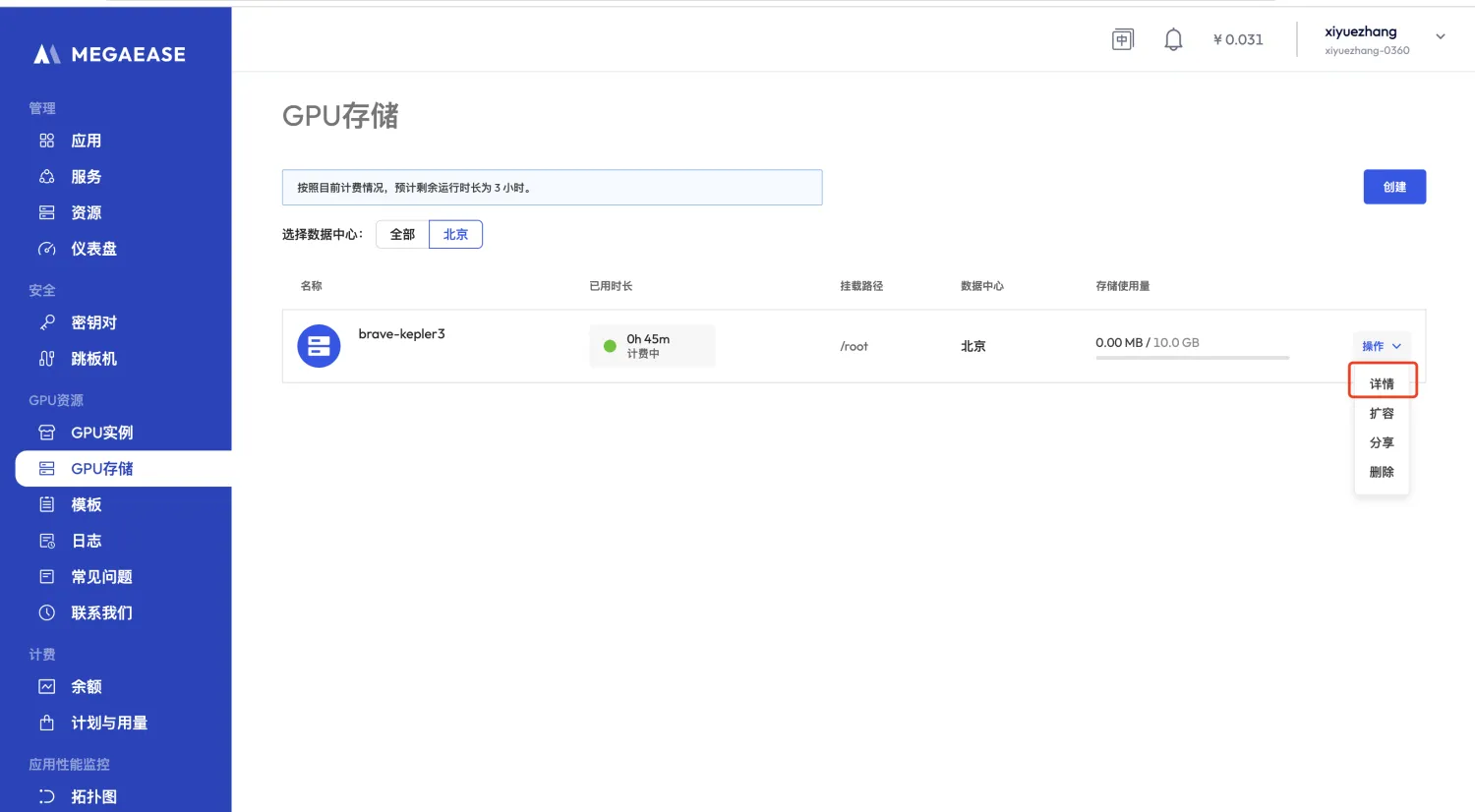
步骤四
点击启动
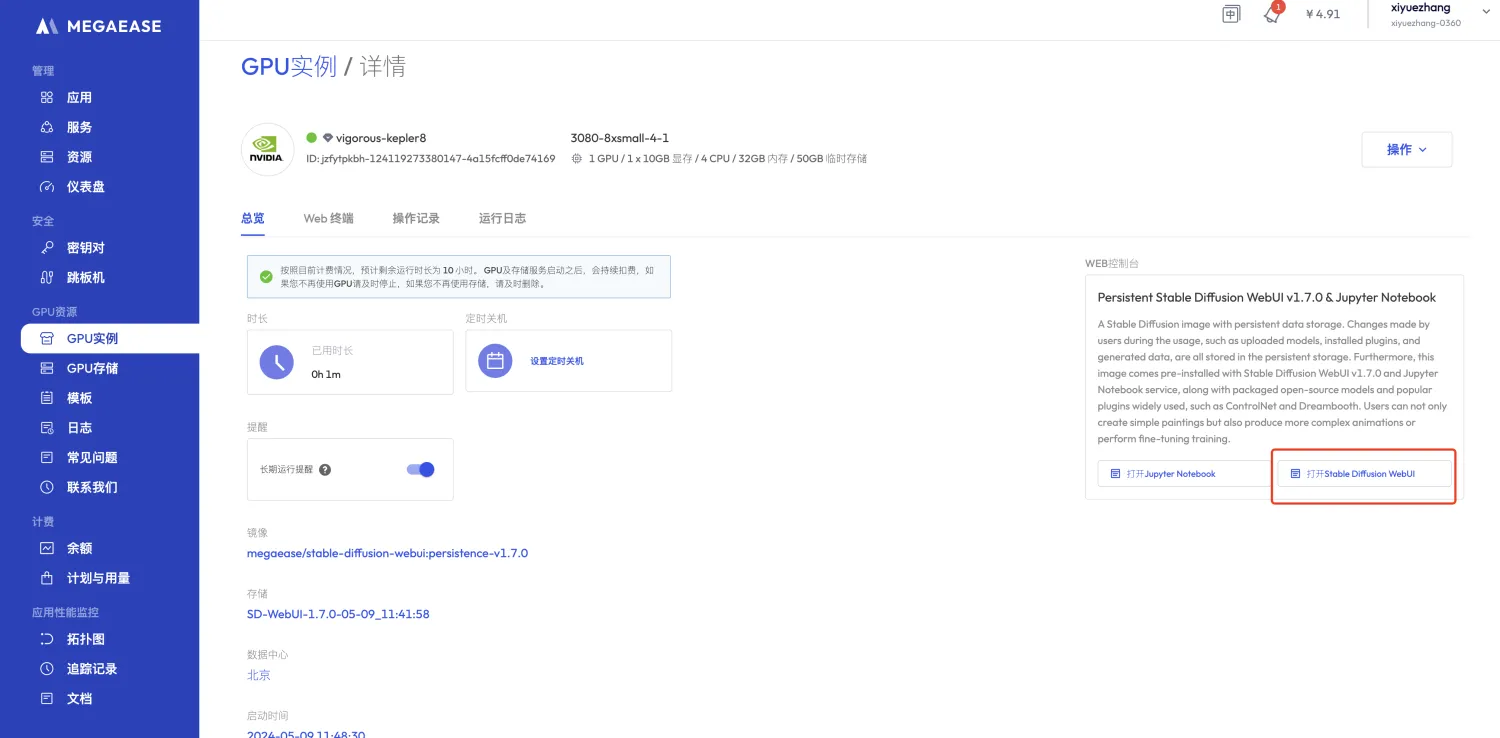
步骤五
开始使用吧
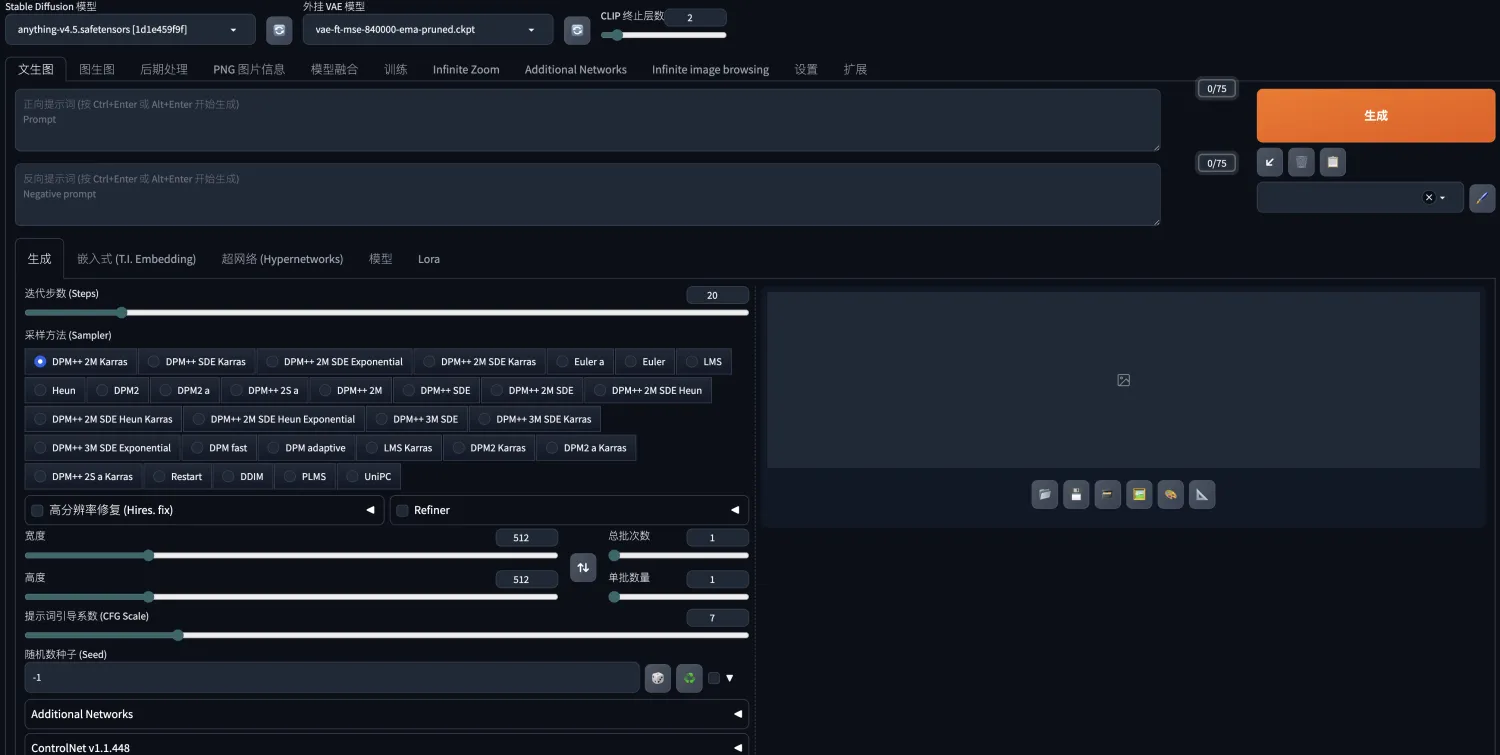
如何使用SD生成想要的图像
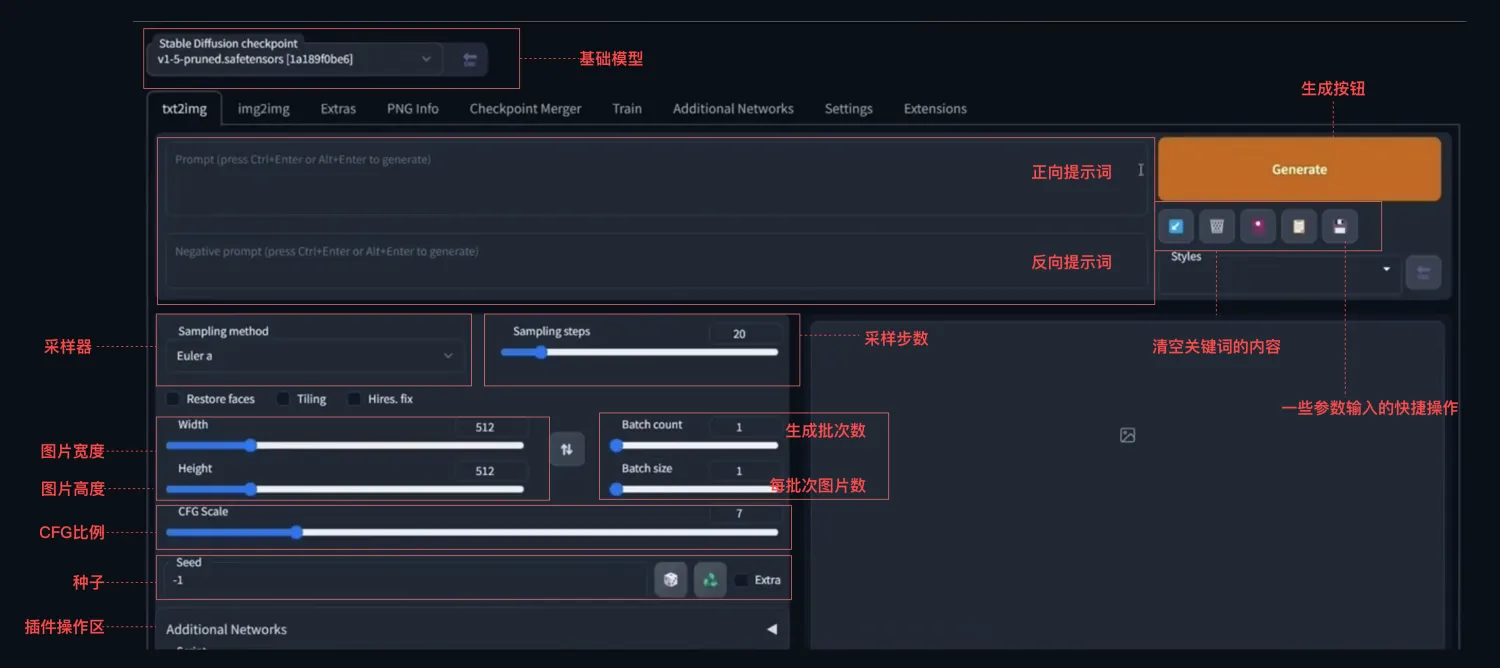
文生图(
text2img)
提示词输入:提示词分为
正向提示词
和反
向提示词。
正面提示词
:
将想要的图像进行描述,描述的越详细,越能达到你想要的效果;描述的越少,越由AI随意发挥,更加有创意性。
反面提示词是输入不想SD生成的内容。
一些关于人像的负面提示词:deformed, ugly, mutilated, disfigured, text, extra limbs, face cut, head
cut, extra fingers, extra arms, poorly drawn face, mutation, bad proportions, cropped head,
malformed limbs, mutated hands, fused fingers, long neck(畸形、丑陋、残缺、毁容、文字、多肢、割
脸、割头、多手指、多手臂、画不好脸、变异、比例不对、剪头、畸形肢、变异手、融合手指,长长的脖子)
图生图
在SD里面有几个比较核心的内容:CLIP反向推理(Interrogate CLIP)、图生图(im2img)、涂鸦绘制(sketch)、局部重绘(inpaint);涂鸦蒙版(inpaint sketch)、上传重绘蒙版(inpaint upload)以及批量处理(batch)等
图生图(im2img)
:根据你上传的图片生成一张在原图基础上创作的新图片可以通过prompt去定义自己想要的结果
涂鸦绘制(sketch)
:进行二次创作,也可以进行线稿的上色,选择合适的模型
局部重绘(inpaint)
:需要将需要重绘的地方圈出来,然后加上 Prompt提示词
涂鸦蒙版(inpaint sketch)
:相比于局部重绘,多了一个蒙版透明度的配置,但这个蒙版是可以自定义颜色的,在局部绘制中画笔只有黑色,而在涂鸦蒙版中蒙版的颜色会影响到原图,选择什么颜色最终重绘都会往这个颜色上靠,蒙版透明度按照需要颜色的程度调节,最好不要超过40。
上传重绘蒙版(inpaint upload)
:白色代表重绘,黑色代表不处理
批量处理(batch)
:批量处理功能用的不多,只要输入图片所在目录路径、图
片处理后保存的路径以及蒙版路径即可批量处理。
关于局部重绘(inpaint)
在生图过程中,不管使用了多么好的模型或者是提示语,都很难一次性就生成完美的图像,因此修复瑕疵是必要的操作,那下面简单说下基础设置
一、模型的选择
大多数人都不知道有一个专门用于修复图像的SD模型,你可以使用这个大型模型来获得最佳修复效果。不过通常情况下,只需使用生成原始图像时所使用的模型进行修复就可以获得不错的效果,如果你要使用这个特定的修复模型,可以点击此处下载下载好后,将模型放到对应的路径下面:
stable-diffusion-webui/models/Stable-diffusion
点击webUl左上角模型切换下拉菜单右侧的刷新图标。然后选择sd-v1-5-inpainting.ckpt 以启用模型。

二、创建重绘蒙版
切换到img2img选项,然后选择Inpaint子选项,然后将图像上传到修复画布中,我们使用画笔工具同时对需要修改的地方进行涂抹,以创建蒙版。而蒙版区域就是我们希望SD重新生成图像的区域。

Mask mode(蒙版模式)決定我们重绘的区域,选择Inpaint masked是对蒙版区域进行重绘,选择Impaint not masked是对蒙版外的区域进行重绘,此处我们选择Inpaint masked,而蒙版区域也就是我们希望SD重绘的区域。
三、Inpainting设置
你可以继续使用原始的提示词(也就是生成原始图像时使用的提示词)来修复瑕疵。这类似于你之前使用文生图一次性生成多个图像,只是这种情况下仅在你蒙版控制特定区域生成图像。
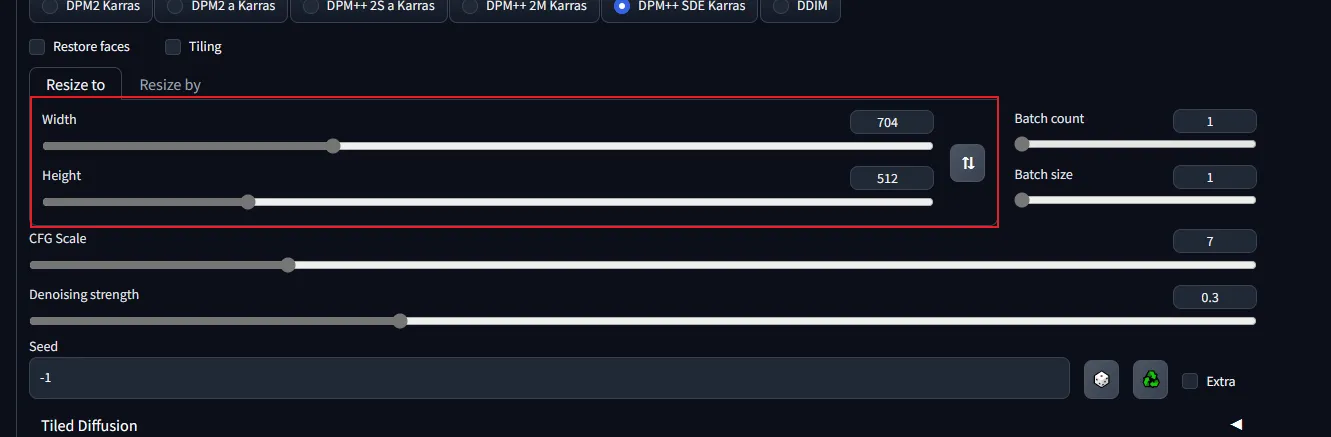
四、Image size(图片尺寸)
需要调整imagine size以使其与你上传图像的尺寸相同
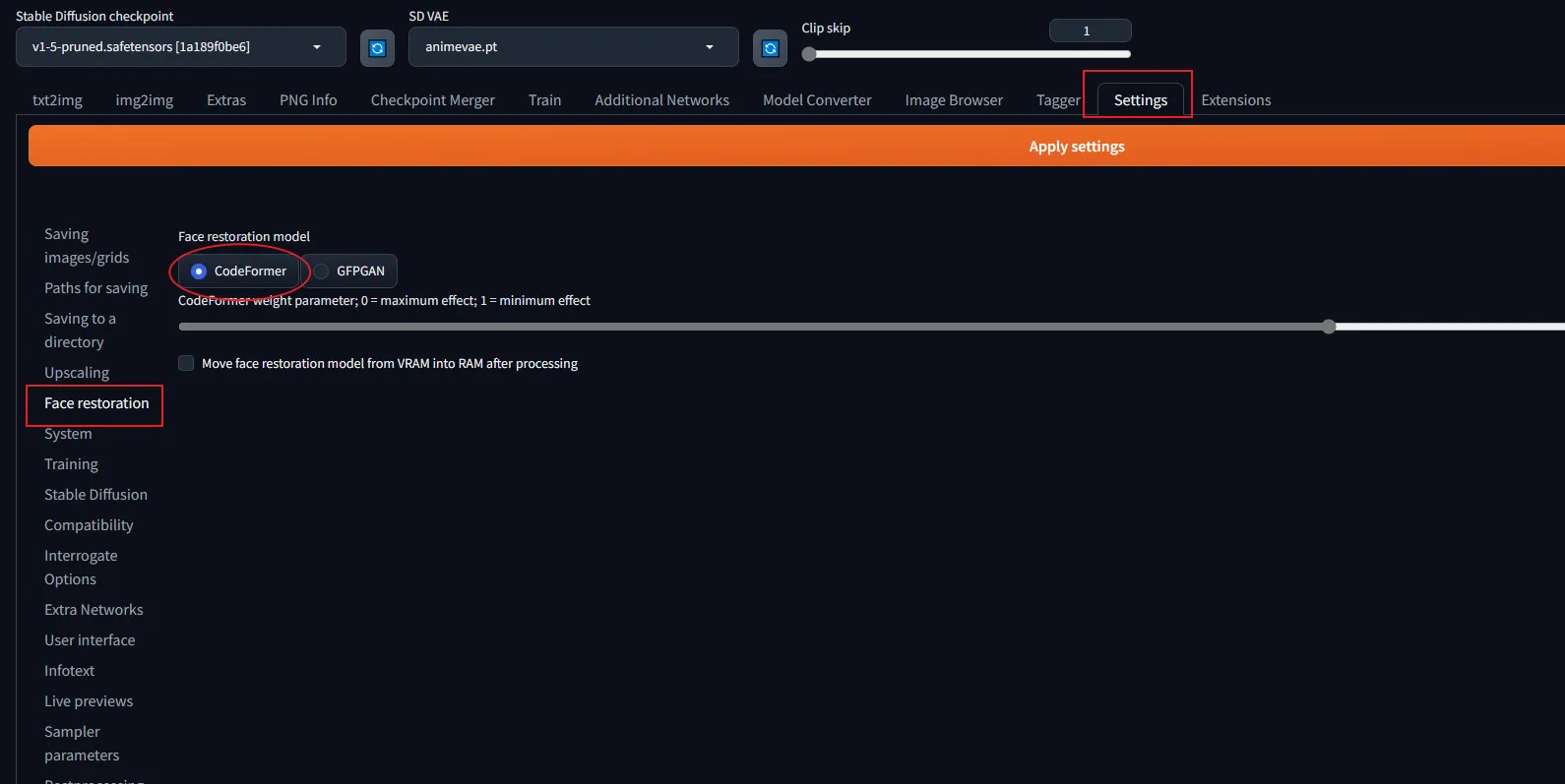
五、Face restoration(面部修复)

如果你想要修复人脸,可以打开面部修复。需要在setting(设置)选项卡中选择并应用面部修复模型(推荐使用CodeFormer 模型)。
需要注意的是开启面部修复也可能使得面部看起来不自然,甚至生成与模型样式不一致的内容,所以请对比效果,酌情使用。
附加功能
在这里我们可以对图片进行单张处理,也可以进行多张处理,把图片放大,让你的图片变得更大更清晰等等
PNG图片信息
在PNG图片信息界面拖入自己原始的SD图片可以读取到相关的参数信息,包括关键词,采样步数,采样器,模型名称等
结语
以上就是SD的原理以及基础界面的介绍,希望对大家有所帮助。随着技术的不断进步和应用场景的不断拓展,SD绘画软件的商业应用前景将更加广阔掌握学习sd技巧不仅能提升技能丰富自己 更是在工作效率中大大提升了,还在犹豫的小伙伴几句抓紧学习起来吧!
4
举报
声明
收藏
分享
相关推荐



























评论你的想法~
表情
喜欢TA的作品吗?喜欢就快来夸夸TA吧!
推荐素材
























你可能喜欢












相关收藏夹
























登录注册
4登录即可同步推荐记录哦
收藏登录即可加入我的收藏
评论登录即可评论想法
分享分享
1