大家好,我是黄彬,一个AI新技术的探索者。
感谢大家的支持与关注。我将持续与大家分享AI各领域的知识与心得!文章涉及到的模型与工作流,请关注后在私信“wan”获取。
ComfyUI 官方宣布原生支持了Wan2.2 首尾帧视频生成,那今天我就来给大家介绍一下Wan2.2。
Wan 2.2是阿里云团队在7月28日发布的最新一代AI多模态视频生成模型,该模型遵循Apache 2.0协议下完全开源,支持
商业使用
。我们先看下我模仿藏师傅爆火的壁纸做的
“大展宏图”
视频。
Play Video Play replay 10 seconds forward 10 seconds Non-Fullscreen Wan2.1在ComfyUI等开源社区的努力下,不仅成为了最强开源视频模型,还开发出很多新玩法,如:视频转绘、数字人、制作单帧图片等等。这次发布的Wan2.2比起2.1又有了大幅提升,等相关生态完善后,完全可以媲美商业模型。
•
MOE 专家模型架构
:模型由2个高低噪声专家模型构成,
高噪声专家
处理整体布局,
低噪声专家
细化细节。
•
电影美学控制
:支持使用专业摄像语言,对画面进行精细化控制。同时在wan2.1基础上大量增加了训练数据,图像数据增加了65.6%、视频数据增加83.2%,支持对光照、色彩和构图等多维视觉控制。
•
大规模复杂运动
:可以流畅地再现各种复杂运动,对人物肢体、面部情绪和大范围动态都能稳定生成,提升动作的可控性和自然度。
•
提示词精准遵循
:可以理解更复杂场景,同时生成多个物体,在互动和复杂空间有了更佳的准确性,可以更好地恢复创作意图。
•
高效压缩技术
:新推出5B版的TI2V(文字&图像生成视频)模型,采用高压缩率 VAE 并优化 VRAM 使用,能在
低显存显卡
上运行(目前8G显存就能运行)。
推荐环境:ComfyUI升级到最新版,到文末网盘下载对应模型和我修改过的工作流使用。
因为模型架构的改变,所以本次Wan2.2模型种类有点多,“黄老师”顺便给大家普及一下整个Wan的模型生态:
名词小课堂:
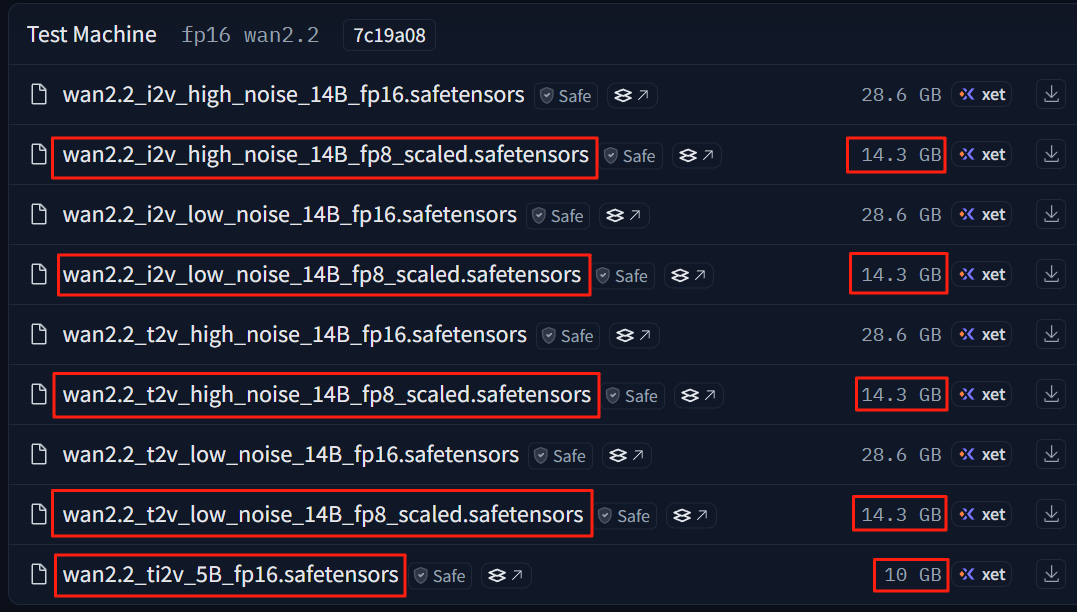
1.t2v和i2v是文字生成视频(text to video)和图片生成视频(image to video)的简称。2.B是模型参数量,1B代表十亿(billion),所以14B就代表140亿参数。3.fp16和fp8指的是模型精度,fp16是全精度模型,效果最好,容量也最大。fp8是半精度模型,在确保效果损失不大的前提下,容量减少到一半。4.模型容量≈显存需求,单个28.6G模型大概需要30G显存,所以fp16模型消费级显卡是无法运行的。
和生图模型一样,一个模型就能实现文生视频与图生视频功能,是目前速度最快的720P@24fps模型之一,并且进行了高效压缩,本地12G左右显存就可以很好运行。
wan2.2_ti2v_5B_fp16 这个就是ti2v_5B模型,容量10G,12G显存可以运行(8G显卡怎么跑?后续会讲)。当然,因为模型使用了高度压缩,所以质量一般。
5B文图生视频结构
文本编码器可以用wan2.1一样的,VAE要用wan2.2专用的
│ │ └── wan2.2_ti2v_5B_fp16.safetensors
│ │ └── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ │ └── wan2.2_vae.safetensors
文生视频-A14B 模型支持生成时长为5秒、分辨率为480P和720P的视频。因为采用了混合专家架构,所以必须下载2个模型:高噪声专家模型 — wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors低噪声专家模型 —wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors但哪怕是fp8精度,1个模型14.3G,2个模型一起运行也需要30G左右的显存,所以本地也是没办法跑的。(下面会讲解本地如何运行)
14B文生视频结构
文本编码器和VAE都可以用wan2.1的,不用另外下
│ │ ├── wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors
│ │ └── wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors
│ │ └── umt5_xxl_fp8_e4m3fn_scaled.safetensors
│ │ └── wan2.1_vae.safetensors
Play Video Play replay 10 seconds forward 10 seconds Non-Fullscreen 文生视频-A14B 模型支持480P和720P两种分辨率视频。实现了更合理稳定的视频生成。同样采用混合专家架构,必须下载2个模型:高噪声专家模型 — wan2.2_i2v_high_noise_14B_fp8_scaled低噪声专家模型 —wan2.2_i2v_low_noise_14B_fp8_scaled
14B图生视频结构
文本编码器和VAE都可以用wan2.1的,不用另外下
│ │ ├── wan2.2_i2v_high_noise_14B_fp8_scaled.safetensors
│ │ └── wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors
│ │ └── umt5_xxl_fp8_e4m3fn_scaled.safetensors
└── wan2.1_vae.safetensors
Play Video Play replay 10 seconds forward 10 seconds Non-Fullscreen 同样,消费级显卡也很难运行14B_fp8的wan2.2模型。因此,可以选择用云端来运行。
推荐大家使用RH在线体验,注册绑定我账号
免费赠送1000积分
(当然我也能得1000积分),每天还送100积分,够体验一段时间了:https://www.runninghub.cn/?inviteCode=116b720f 邀请码:116b720f
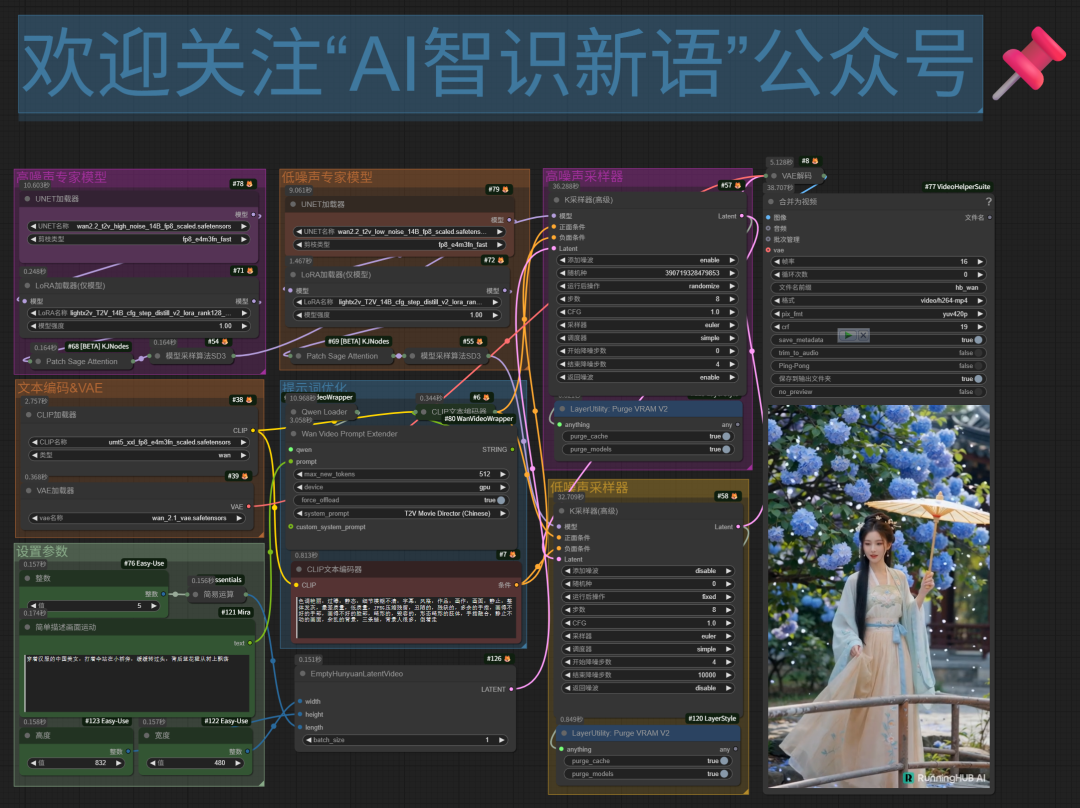
当然,如果你就是想本地运行,我们也可以通过使用GGUF量化模型+KJ工作流来尝试。
1.GGUF是一种高效的模型存储格式,通过量化方式,把原来的模型权重压缩到更低,从而降低显存需求。2.KJ:ComfyUI社区的大神级开发者,也是许多高质量自定义节点和模型的作者(如:SUPIR、KJNodes)。他开发的WanVideoWrapper节点,比官方节点能支持更多模型与功能,能在降低显存的同时,加快视频生成速度。
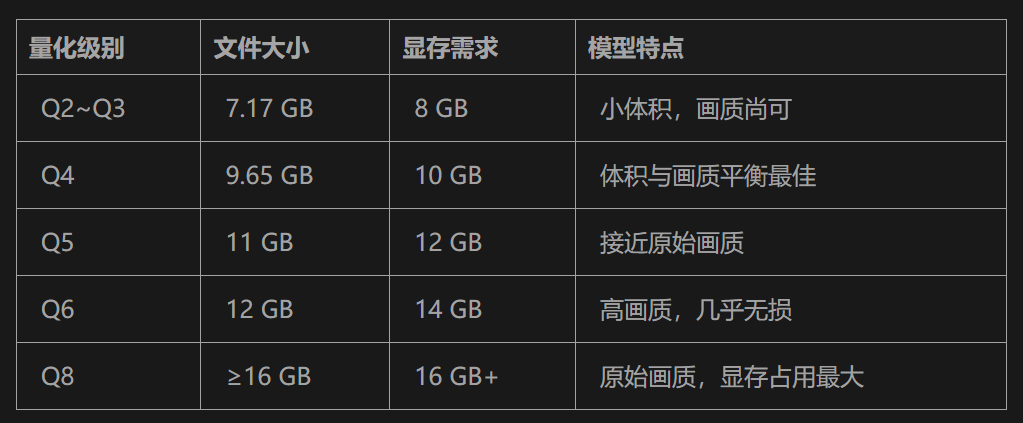
不同量化程度对应不同模型大小,越小质量越差,对显存要求也越低。ti2v_5B是压缩模型,只需要1个模型,所以理论上8G显存就能运行量化版。
Wan2.2是MOE架构,需要2个专家模型,所以理论上显存要求≈单模型显存需求*1.5。
在Wan2.1时代,开源社区涌现出了很多非常好用的Lora,在Wan2.2上也能继续使用,可以通过它们来提升视频生成速度与效果。
LightX2V 加速Lora
:这是一个加速Lora,类似SD的trubo Lora,能使用4~6步就生成视频。同样也有t2v和i2v以及量化版本。量化主要看文件名中rank后面的数值(影响显存和运行速度),最大128,最小8,一般建议选择rank64(线上)或者rank32(本地)。
文生视频:
Lightx2v_T2V_14B_480p_cfg_step_distill_rank64_bf16.safetensors
图生视频:
Lightx2v_I2V_14B_480p_cfg_step_distill_rank64_bf16.safetensors
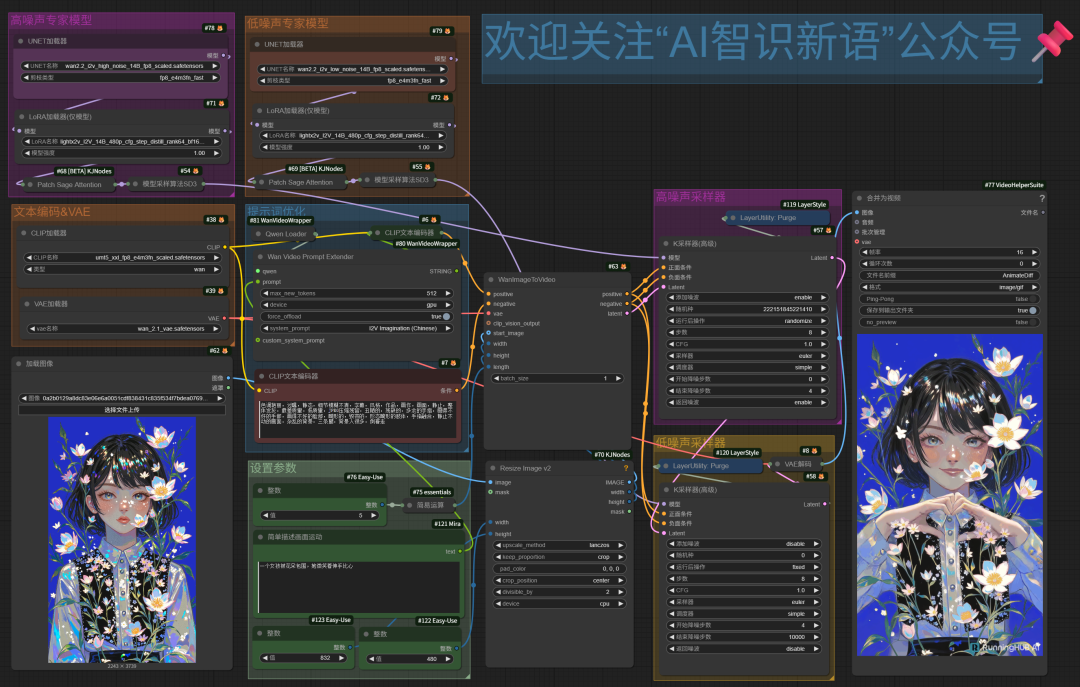
是不是看到上面这一堆不同功能不同型号的模型都晕了?本地我实测下来,16G显卡,使用KJ工作流和14B GGUF Q4量化模型,生成6秒视频(上面的大展宏图)用了5分钟左右。而线上用RH的话,14B_fp8模型2分钟左右,优势还是很明显的。 如果硬件达不到,或者懒得自己折腾的,可以直接使用下面工作流在线使用:
工作流:Wan2.2_14B_文生视频 (8步加速) + 提示词扩写 体验地址:https://www.runninghub.cn/post/1952277100332003330/?inviteCode=116b720f
工作流:Wan2.2_14B_图生视频 (8步加速) + 提示词扩写体验地址:https://www.runninghub.cn/post/1952277132212948994/?inviteCode=116b720f
Wan2.2不论从美学、动态、复杂的运动和运镜比起2.1都更加优秀,甚至有了和闭源模型掰一掰手腕的能力,后续在开源社区的支持下,一定会涌现出更多好用、实用的功能!我也会继续和大家分享更多的知识与技巧。
这就是今天教程的全部内容了,如果觉得内容有帮助的话,快去试试吧,希望评论区能看到你的作品,
别忘了点赞支持!
我是黄彬,一个陪你玩转AI新工具的探索者。我们下期再见!