AIGC—Stable Diffusion WebUI 苹果电脑云端基础教程

上海/动画师/1年前/198浏览
版权
AIGC—Stable Diffusion WebUI 苹果电脑云端基础教程
最近开始学习Stable Diffusion WebUI,但是无奈自己用的是苹果电脑,本地部署SD太麻烦,而且苹果电脑不带N卡,出图会非常慢。于是我就在网上搜索苹果云端部署的方法,试了Google drive,但是发现一直报错,最后使用了AutoDL,并且找到了一位大神的云端整合包,一键使用,预置所有 ControlNet 模型和预处理器、带有大量常用插件,用起来很顺畅。
#1 苹果电脑云端部署Stable Diffusion WebUI
使用AutoDL部署SD
- 打开https://www.autodl.com/home,注册成功后进入控制台,在容器实例里选择-租用新实例:
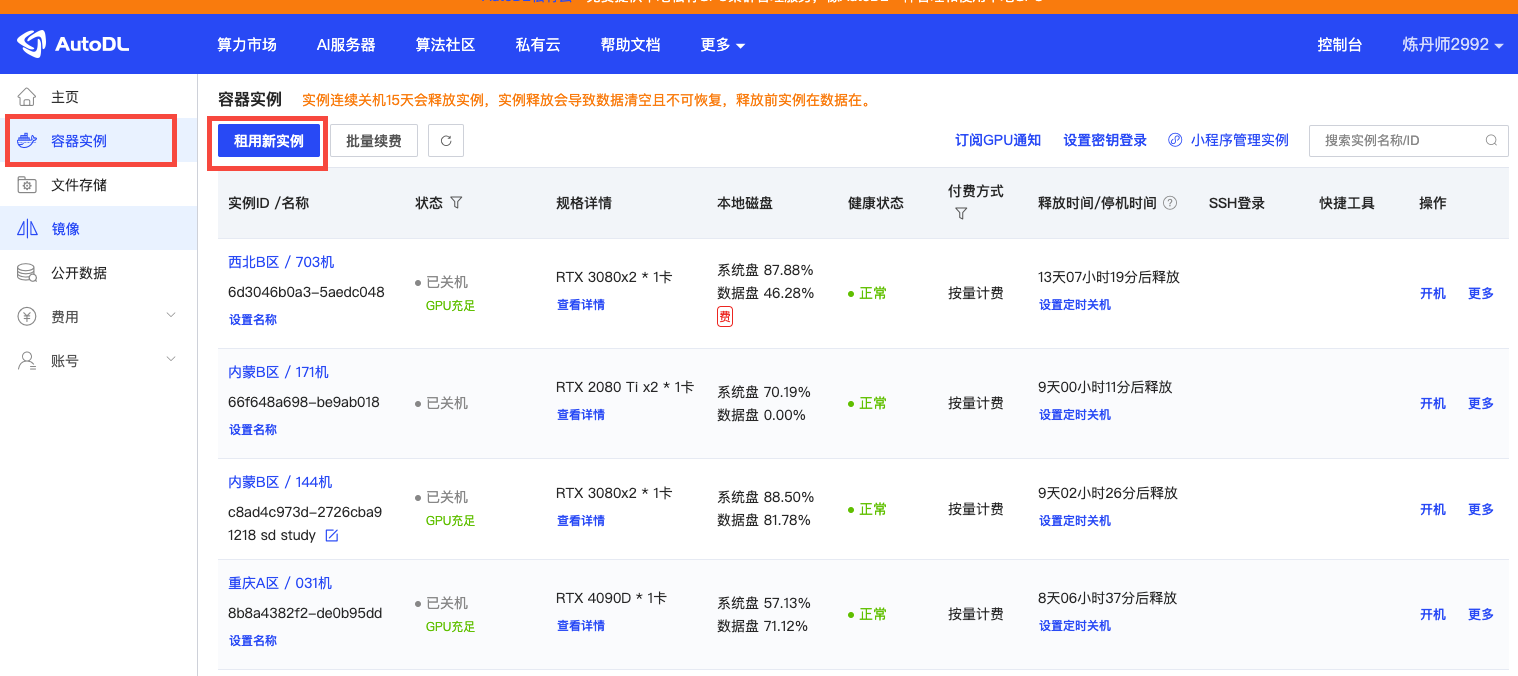
2.租用GPU型号是3090,4090,A5000都可以,不同型号每小时费用不一样
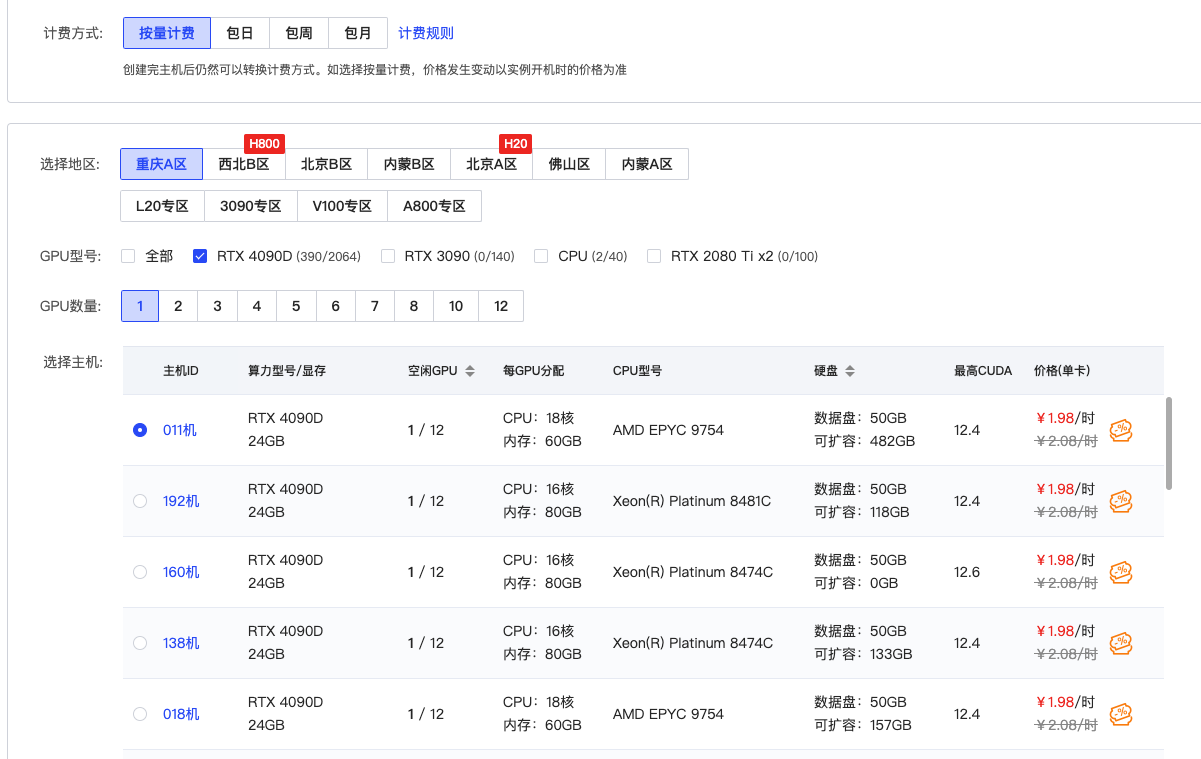
3.社区镜像搜索
tzwm
,选择 A1111(适合绘图的新手小白) 结尾的最新版本:
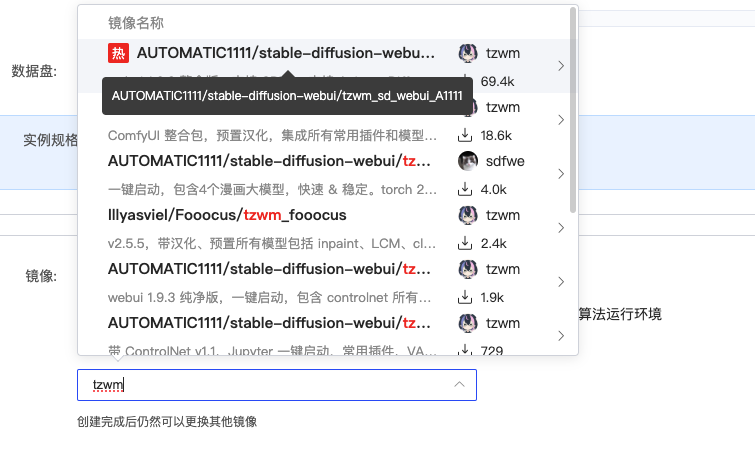
4.运行镜像:点击开机:

状态在“运行中”代表机器已经启动好了,再点击“JupyterLab”:

进入jupyterlab里面后,点击启动按钮,等待启动:
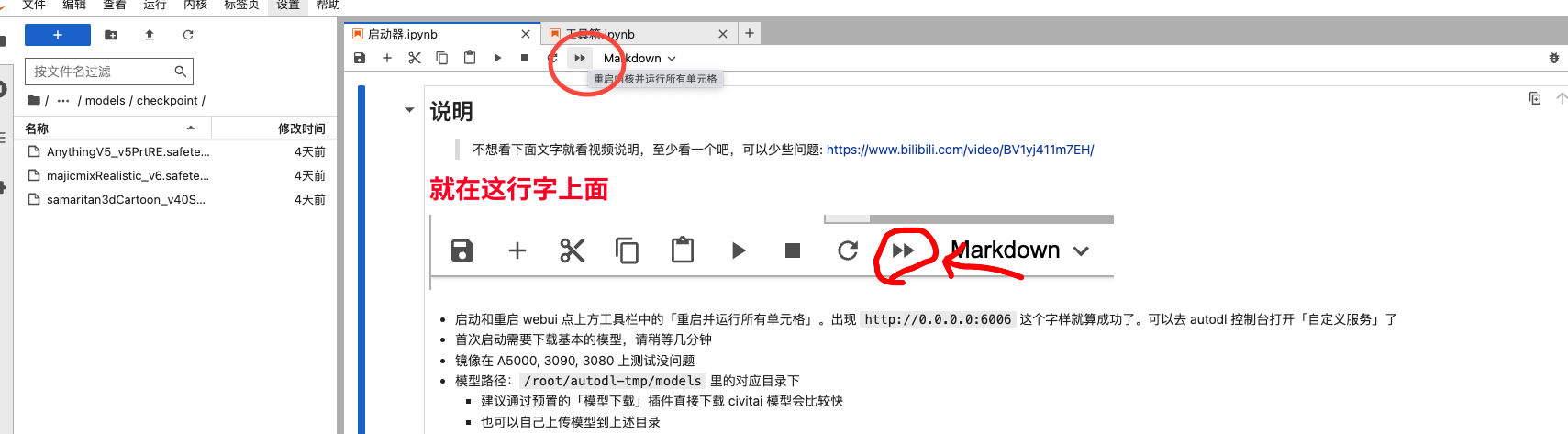
当页面最后出现“:6006”时就代表已经启动成功了:
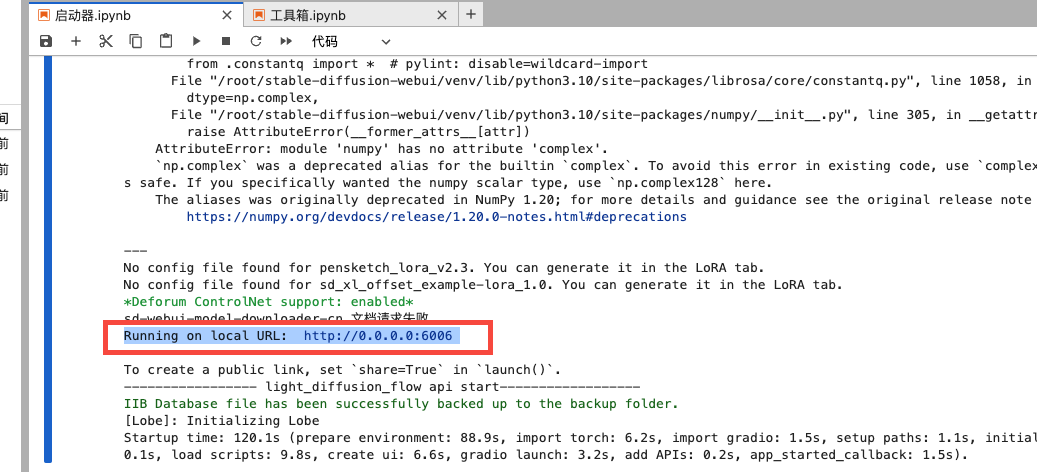
5.来到容器实例,点击“自定义服务”,苹果电脑需要复制命令和密码到终端进行运行,终端输入好后,点击提示里面的链接访问SD WebUI
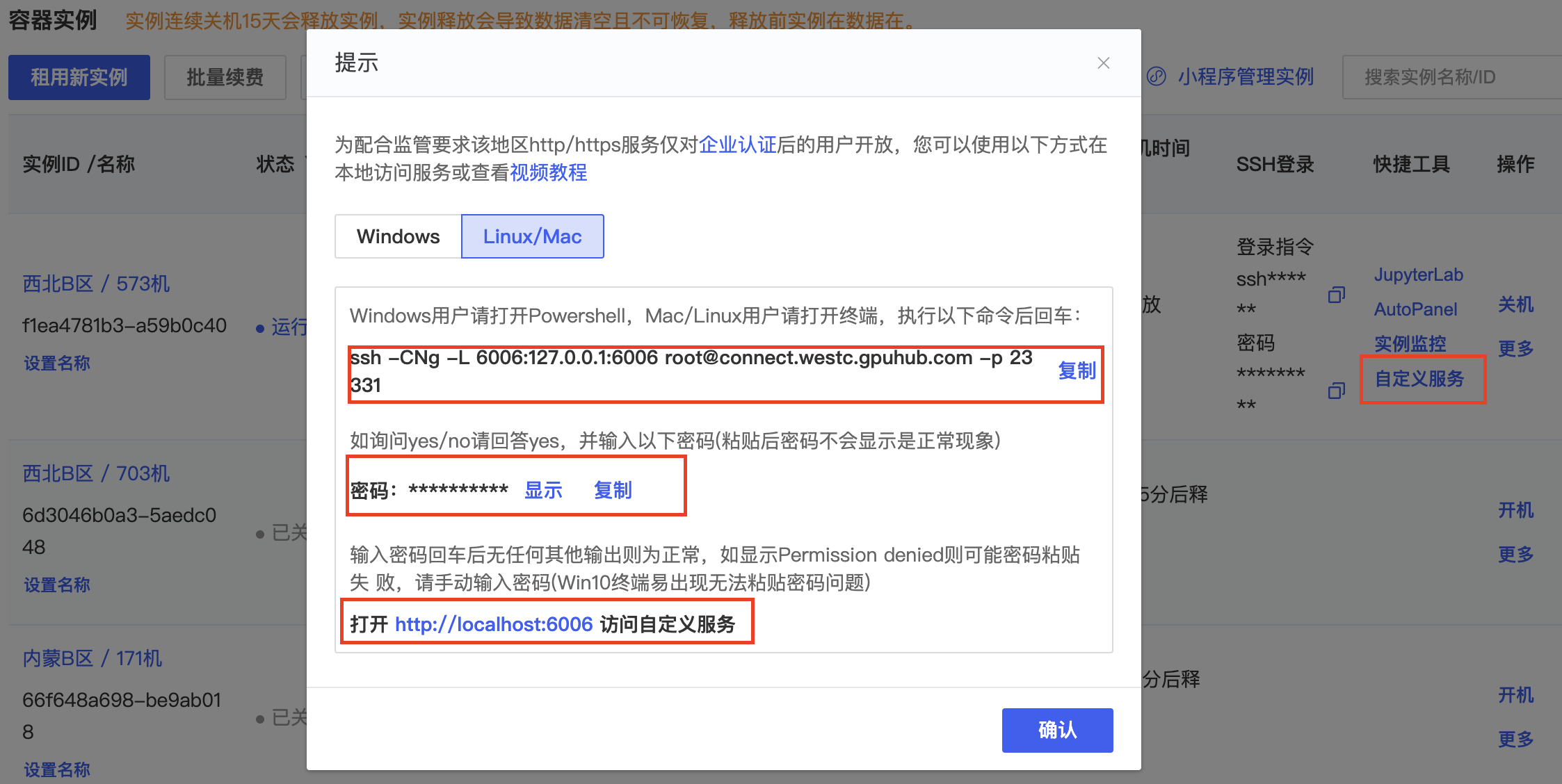
不用时,记得关机,要不然会一直计费。
6.插件安装文件夹,ckpt是放大模型的文件夹:
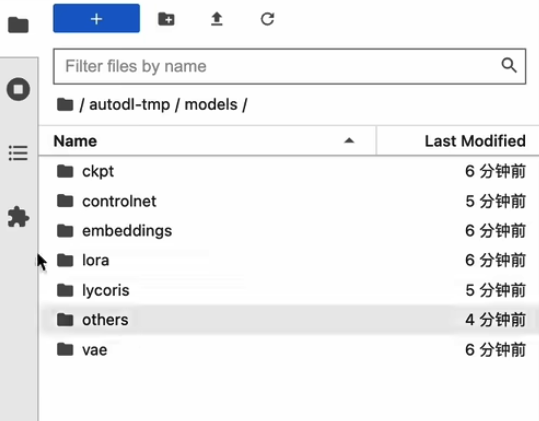
生成图片所在文件夹:
#2 Stable Diffusion 文生图操作界面介绍
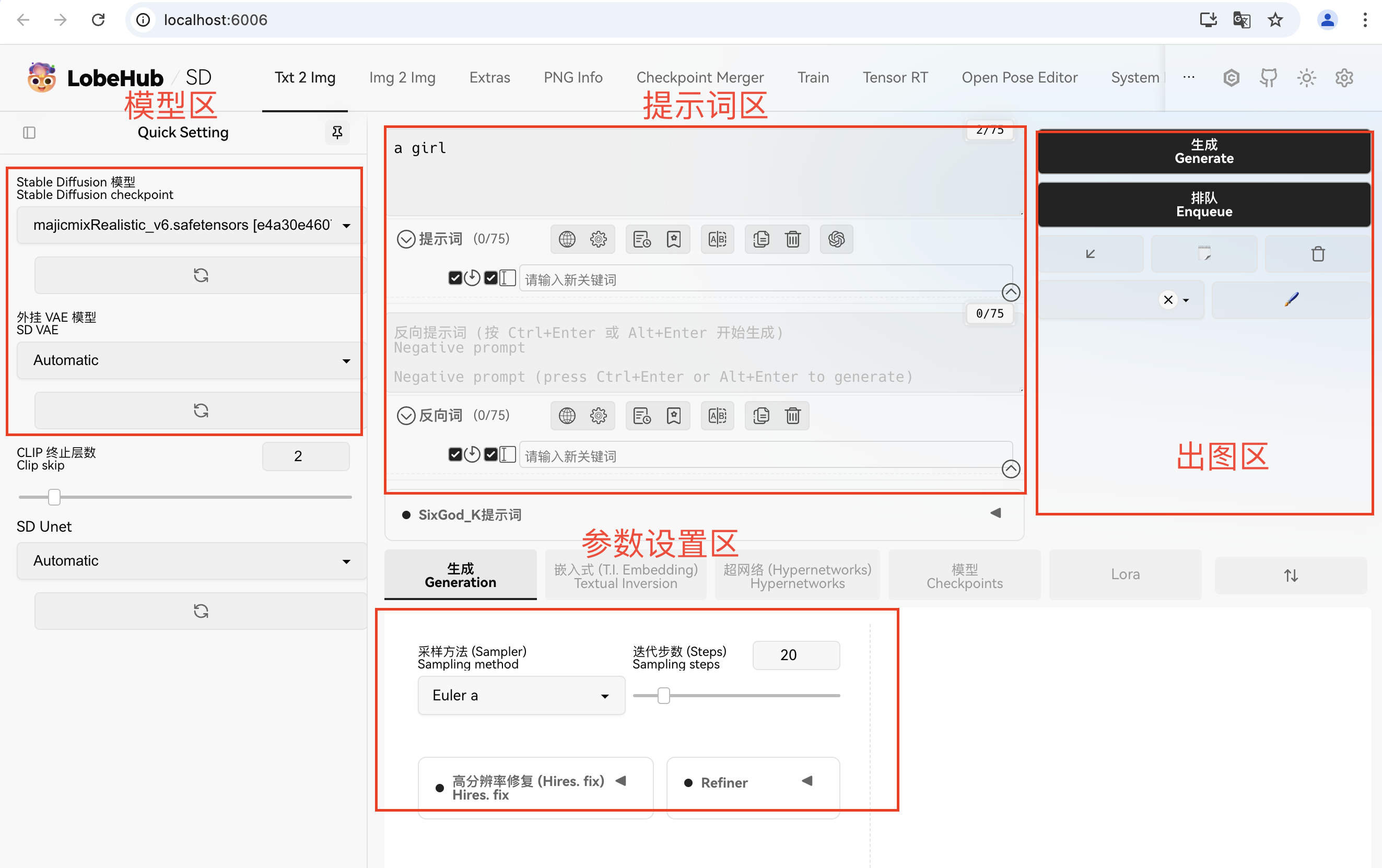
1.文生图生成区基本功能分区和参数
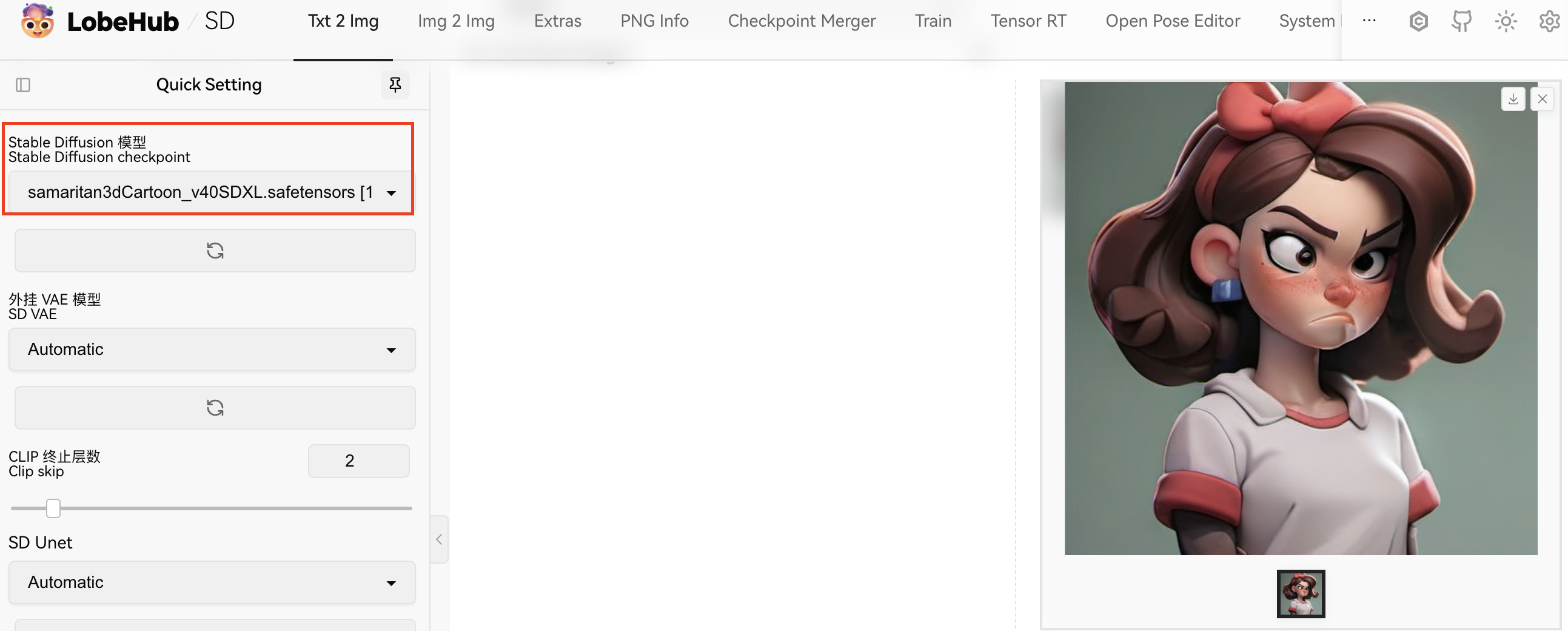
SD的操作界面可以分为模型区、提示词区、参数设置、出图区、插件区,如图所示:
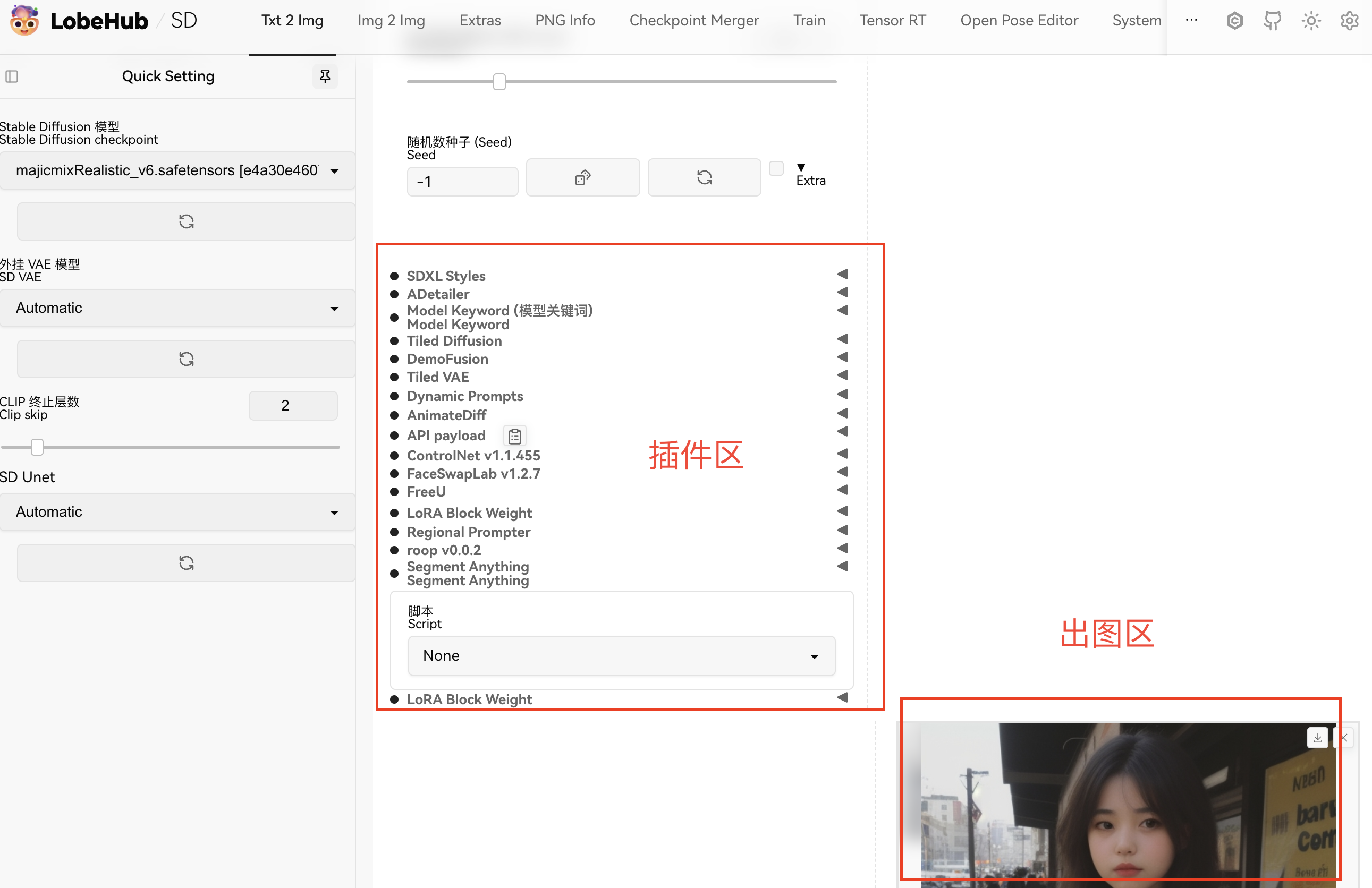
2.模型区:
SD的模型区,目前使用比较多的有大模型,lora模型,vae,embedding。
2.1 模型下载方法
https://www.liblib.art/
模型下载好了后,放在文件夹里,上传好了以后需要重启一下页面才会显示。我使用的镜像放置模型的文件夹是/dutodl-tmp/models
2.2 大模型
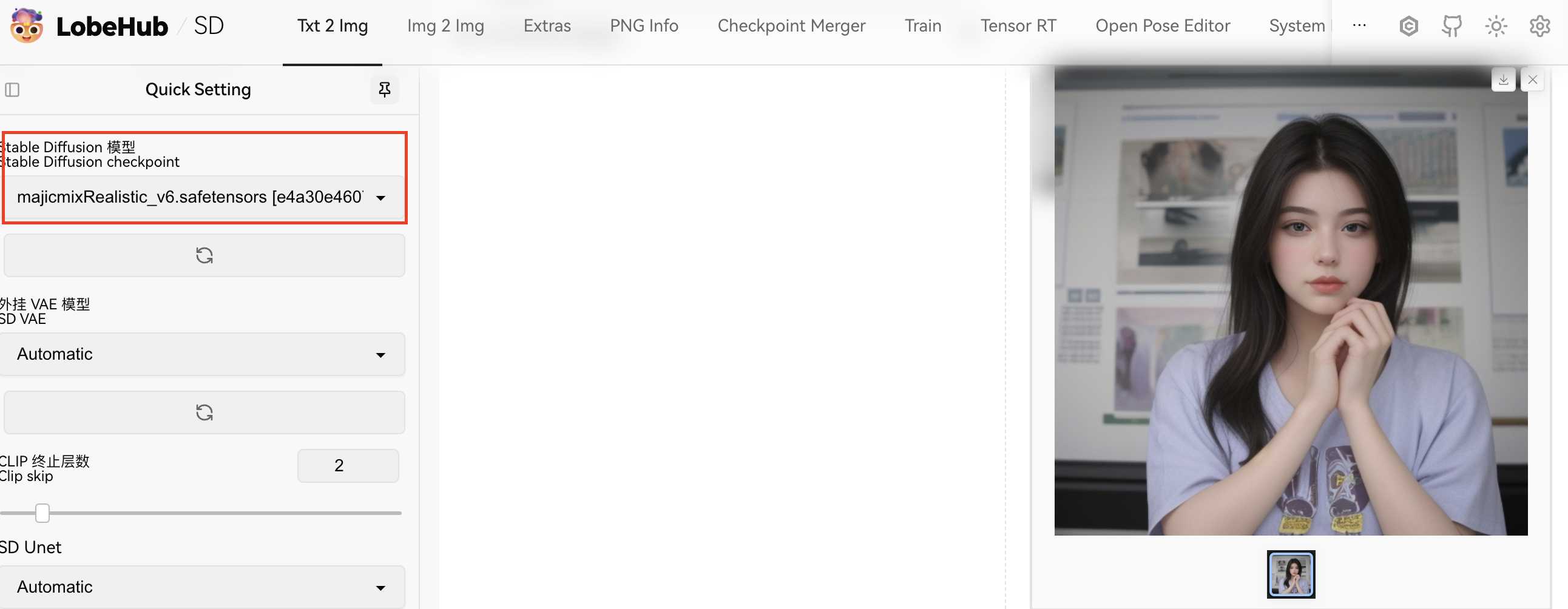
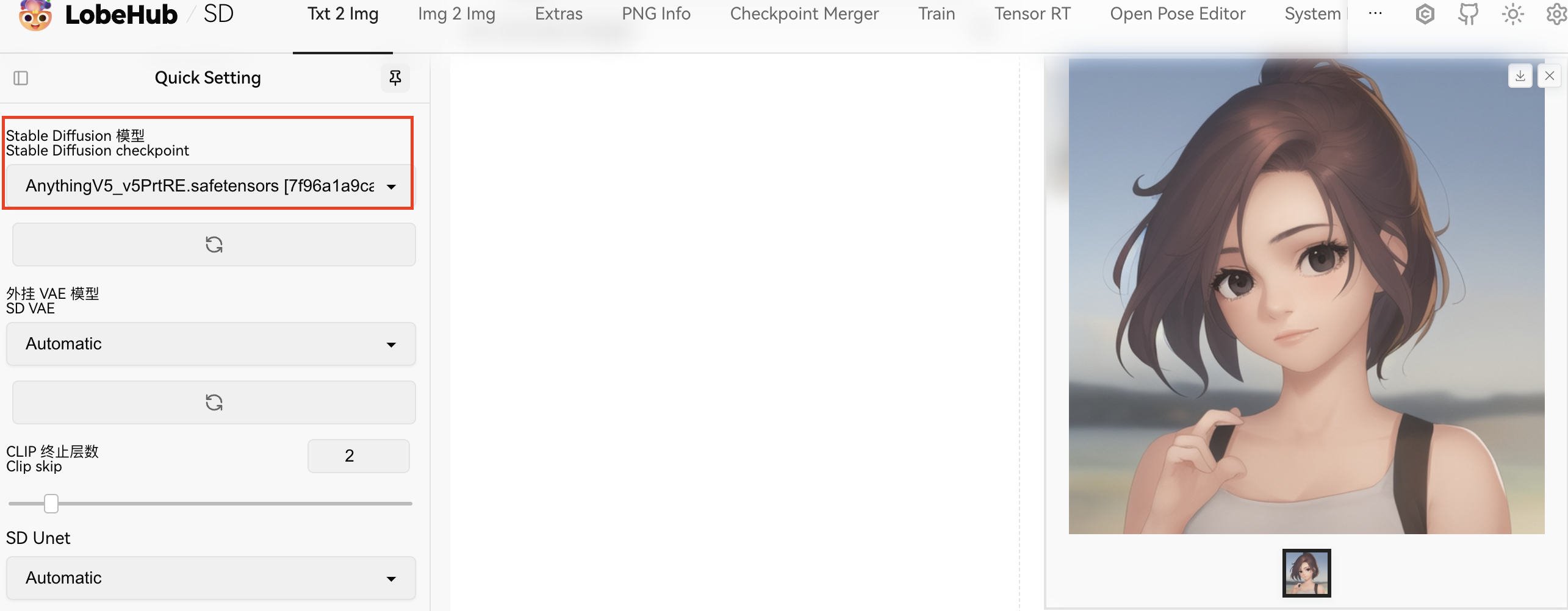
大模型是控制大整个画面的风格走势的,具有某种特定的画风,大模型的后缀一般为ckpt或者safetensors,大小在1G或者更高。
我使用相同的关键词“1girl”,使用三种不同的大模型,可以看到生成的风格完全不同,大模型就像是一个画师一样,每个不同的大模型都有自己的绘画风格:
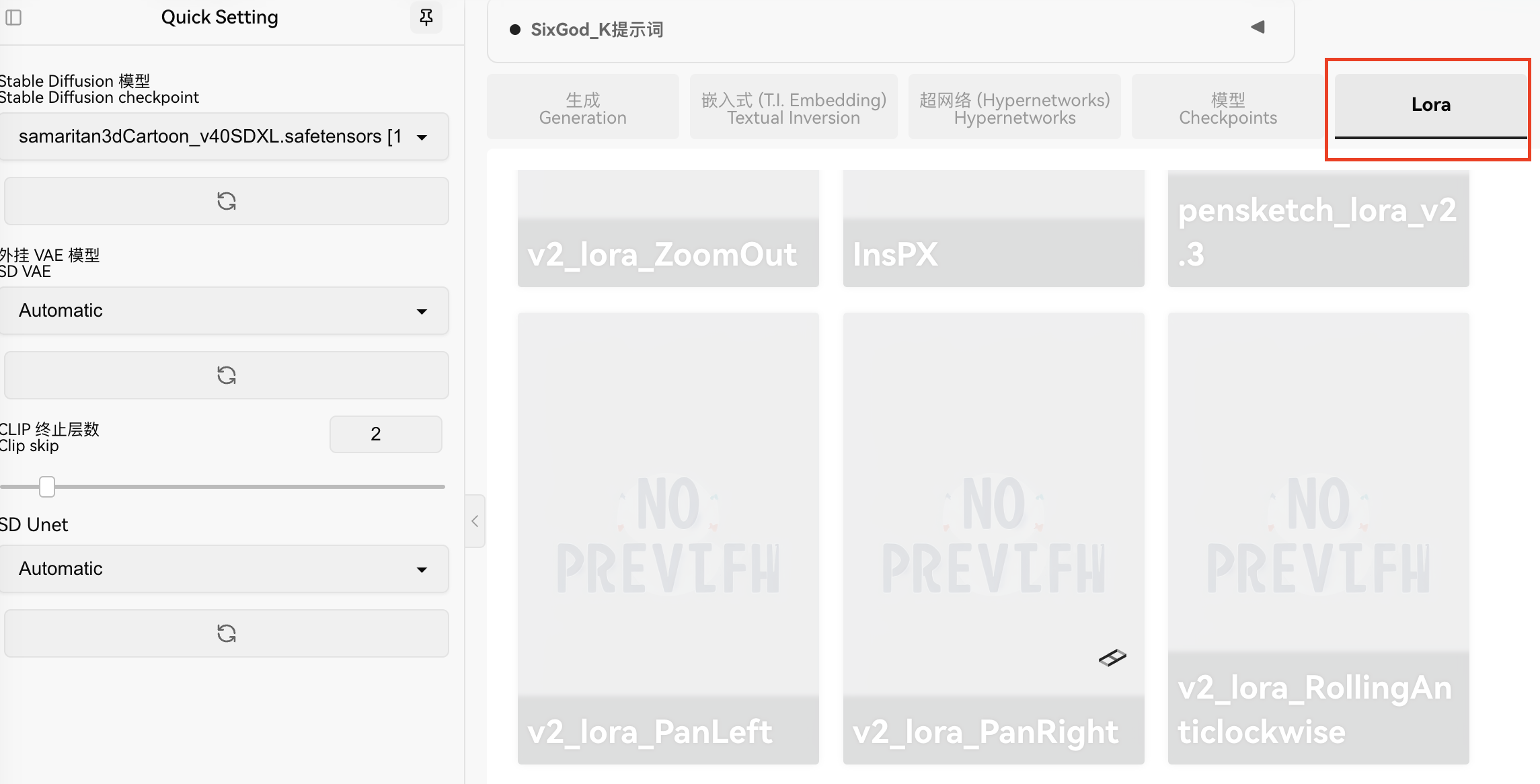
2.3 Lora模型
Lora模型也是控制画面风格的,一般用于固定画风,人物长相,服装,动作。模型较小,比较适合性能不足的电脑使用。可以用少量的图像训练,切渲染时间较短。后缀一般为safetensors。
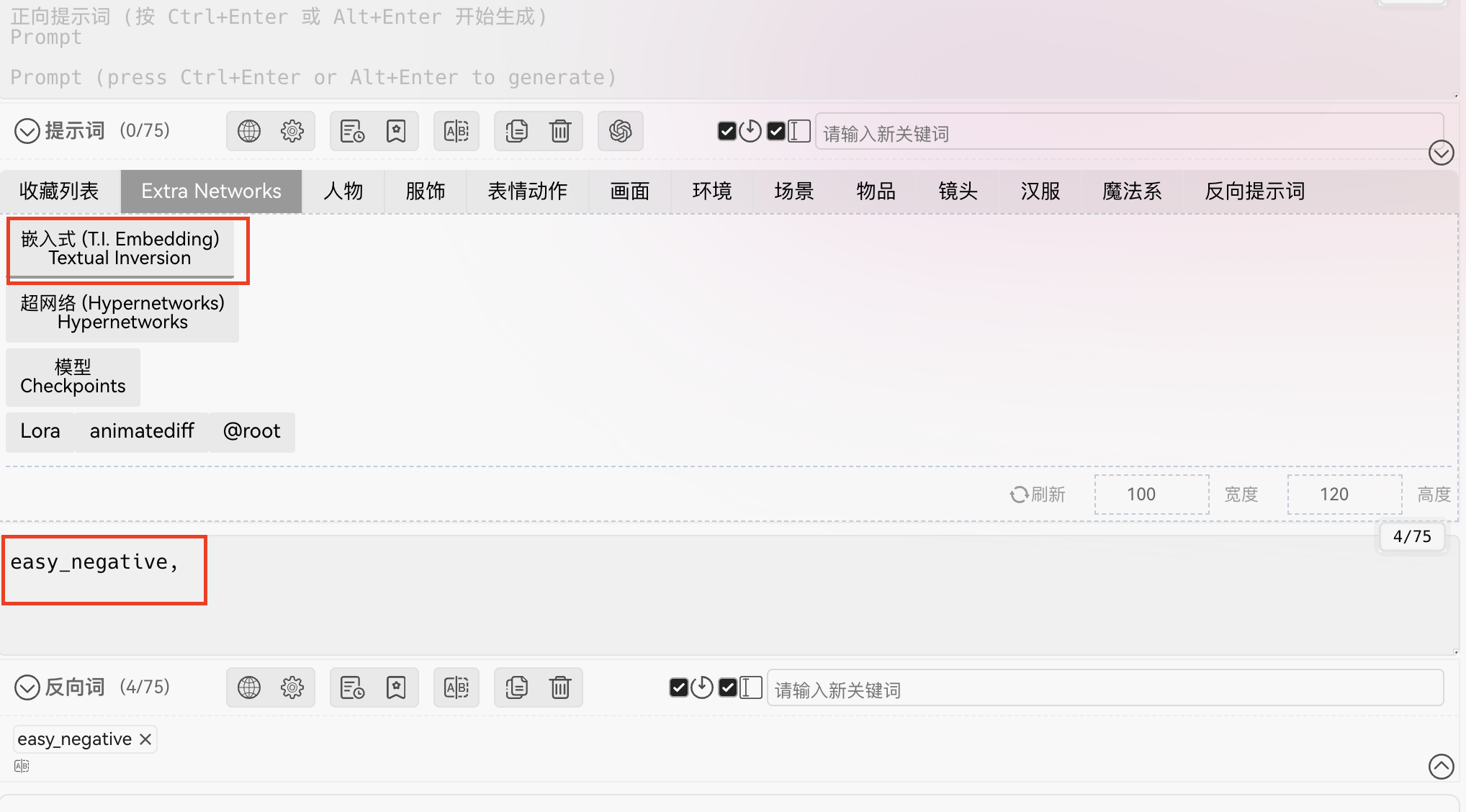
2.4 embedding
embedding/Textual Inversion 相当于提示词打包,用来整合一长串的提示词:
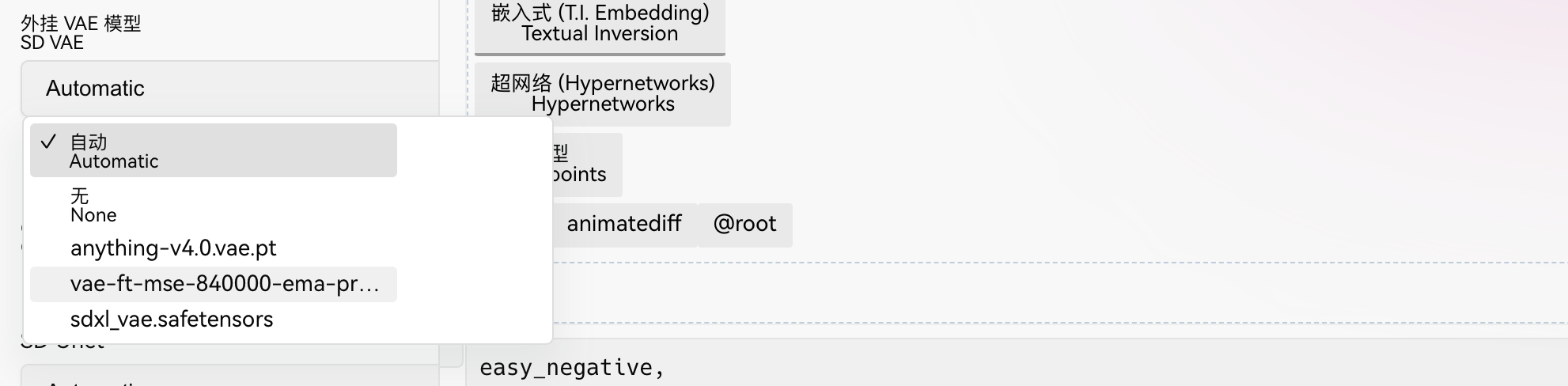
2.5 vae
vae相当于滤镜,可以让图像更加鲜艳,可以在图像的基础上细化,也可以控制一些图像的风格。后缀一般为ckpt或者pt。
3.生成图片参数:
3.1 正向提示

正向提示词就是你希望出现什么。
内容性提示词:
人物特征:
服饰穿搭,发型发色,五官特点,面部表情等。
场景特征:
室内,窗帘,床,浴室等,大海,山丘,草地等。
场景和环境:
春天,夏天,秋天,冬天,黄昏,夜晚,早晨;轮廓光,体积光,霓虹灯,透镜光晕,金属光泽,氛围光照,丁达尔效应,漏光光效,背景光,自然光,太阳,落日,月亮,满月,星星,天空,多云,雨天,冰雪,雪花,闪电,彩虹,流星雨,宇宙等。
画面视角与构图:
3/4角度,动态角度,前视图,正面拍摄,居中,俯视视角,仰视视角,侧面视角,背面视角,全身像,半身像,七分身镜头,广角镜头,特写等。
艺术风格:
迪士尼电影,皮克斯动画,宝丽来艺术,万花筒摄影,欧泊渲染,吉卜力风格,签绘风格,柴油朋克,专辑封面,拼贴艺术,彩色玻璃工艺,像素画,瓷画,水墨画,剪影,插画,水彩画,浮世绘,中国风,油画等。
提示词模版:
正人物质量:
高细节,超高清,准确,超级细节,获奖,高质量,最佳质量,高细节,纹理皮肤,解剖正确。
正场景质量:
超高清,精确,超级细节,获奖,高质量,最佳质量,高细节,纹理皮肤,解剖正确,赤壁,细节,纹理皮肤,精确,
3.2 负向提示
正向提示词就是你不希望出现什么,不要忽略负面描述,它对生成图的效果同样很重要。
提示词模版:
负人物质量:
低质量,正常质量,低分辨率,正常质量,灰度,皮肤斑点,痤疮,皮肤瑕疵,老年斑,(丑陋:1.331),重复,病态,残缺,变形,变异的手,画得不好的手,模糊,糟糕的解剖结构,糟糕的比例,多余的四肢,缺失的手臂,多余的腿,太多的手指:1.61051,毁容,不清晰的眼睛,低,糟糕的手,缺失的手指,多余的手指,糟糕的手,缺失的手指,多余的手臂和腿,融合的手指:1.61051,低分辨率,糟糕的解剖结构,糟糕的手,缺失的手指,多余的手臂和腿,融合的手指,低分辨率,糟糕的解剖结构,糟糕的手,文字,错误,缺失的手指,多余的手指,更少的手指,裁剪,最差的质量,低质量,正常质量,伪影,签名,水印,用户名,模糊,缺失的手臂,长脖子,驼背,坏脚。
负场景质量:
低质量,正常质量,低分辨率,正常质量,灰度,(丑:1.331),重复,病理,不完整,恍惚,模糊,解剖结构不好,比例不好,1.61051,低分辨率,文本,错误,裁剪,最差质量,伪影,签名,水印,用户名,模糊。
3.3 提示词权重语法
(提示词+权重数值)数值从0.1-100,默认是1,低于1为减弱,高于1为增强。
(flower):(提示词) 是1.1倍,
((提示词)) 是1.1x1.1=1.21倍,
(提示词1.2) 则是关键词权重1.2倍,
(Flowers:1.5)意思是权重为1.5倍 加强,(Flowers:0.5)意思是权重为0.5倍 减弱。
3.4 提示词混合语法
渐变:[提示词:提示词]
混合:用竖杠 | 分割多个关键词,可以
混合
多个元素。例如Red hair | Blue hair :

用竖杠 AND分割关键词,可以
融合
多个元素。AND更像是将不同的东西融合到一块,比如长得又猫又狗的动物,a cat AND A dog:

3.5 采样迭代步数(Steps)
增加生成的画面细节,迭代步数越高,生成的细节就越高,但是如果迭代步数太高可能就不起作用了,建议数值控制在20-50区间。



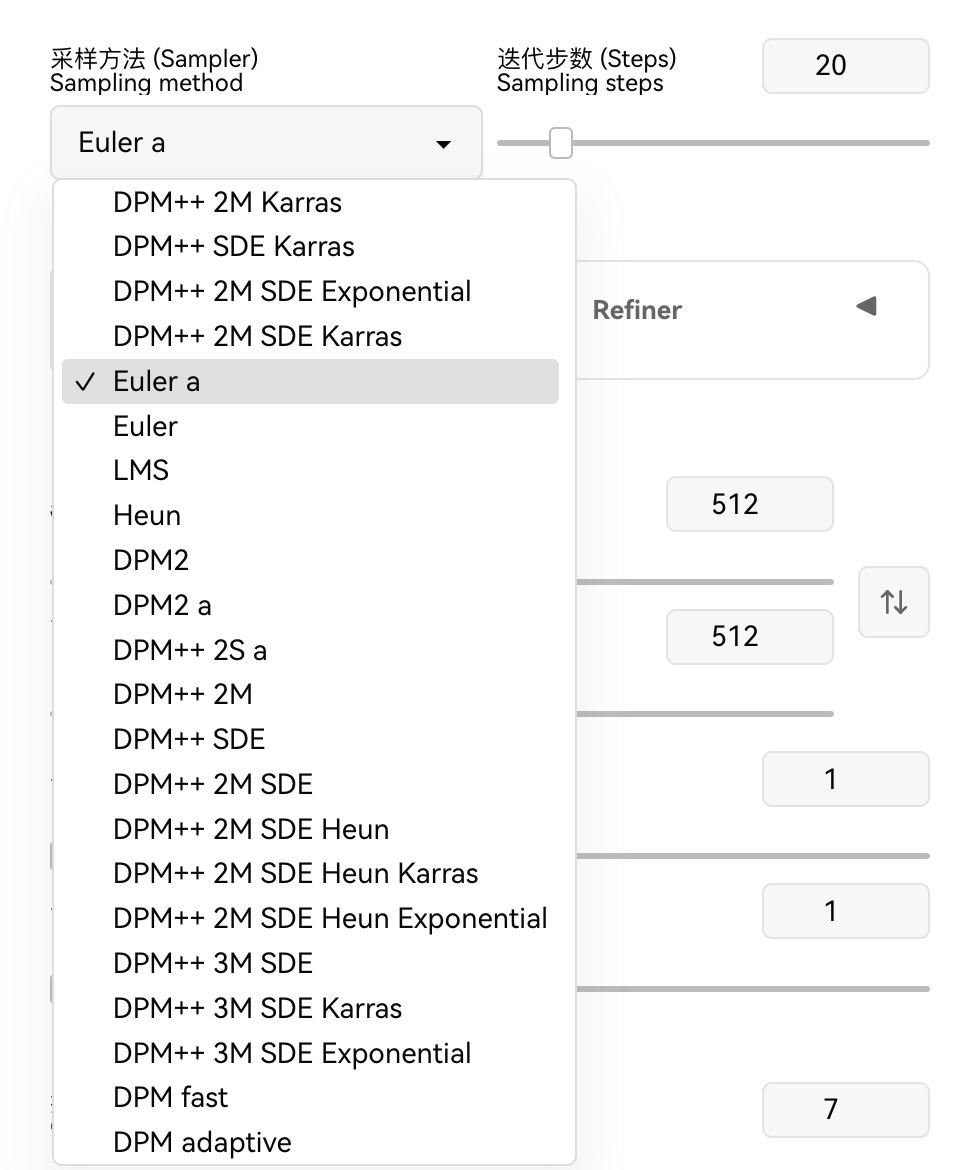
3.6 采样方法(Sampler)
Euler a :二次元图像 小场景。
DPM++25 a karrsa :适合写实人像 复杂场景刻画。
DDIM++2S a Karras:写实人像 复杂场景刻画。
快速且质量不错:DPM++25 a karrsa,unipc。
高质量且会自由发挥:DPM++2M SDE Karras,DDLM。
速度快适合简单的图像:Euler,heun。
稳定可复现的采样器:Euler a,DPM2 a,DPM++ 2s a,DPM2 a Karras,DPM++2S a Karras。
3.7 图像尺寸
一般都使用低分辨率先算,在用高清修复 修复这张图的画质,因为一开始画面分辨率太高的话AI算出来基本会有多人或者多头的情况。最终出图的分辨率尺寸:

3.8 引导词系数
就是提示词相关性,还原执行提示词的程度(安全范围:7~12)

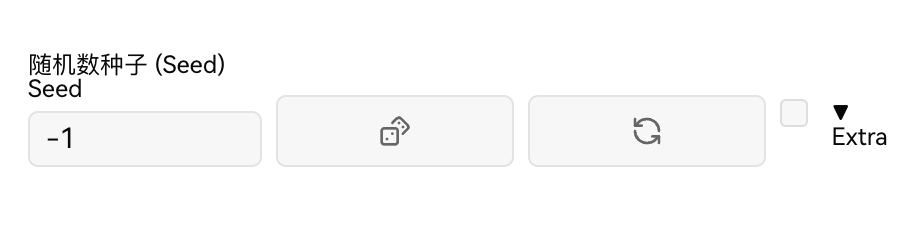
3.9 图像生成种子
将随机种子改成-1 则每次都会是不一样的结果。使用上一次的随机种子数,用于重现上一次的结果。
3.10 生成批次数量
总批次数:按照批次数连续进行作图,依次生成,对显卡要求低,但是生成时间长。
单批数量:一次生成多张图片,对显卡要求比较高。

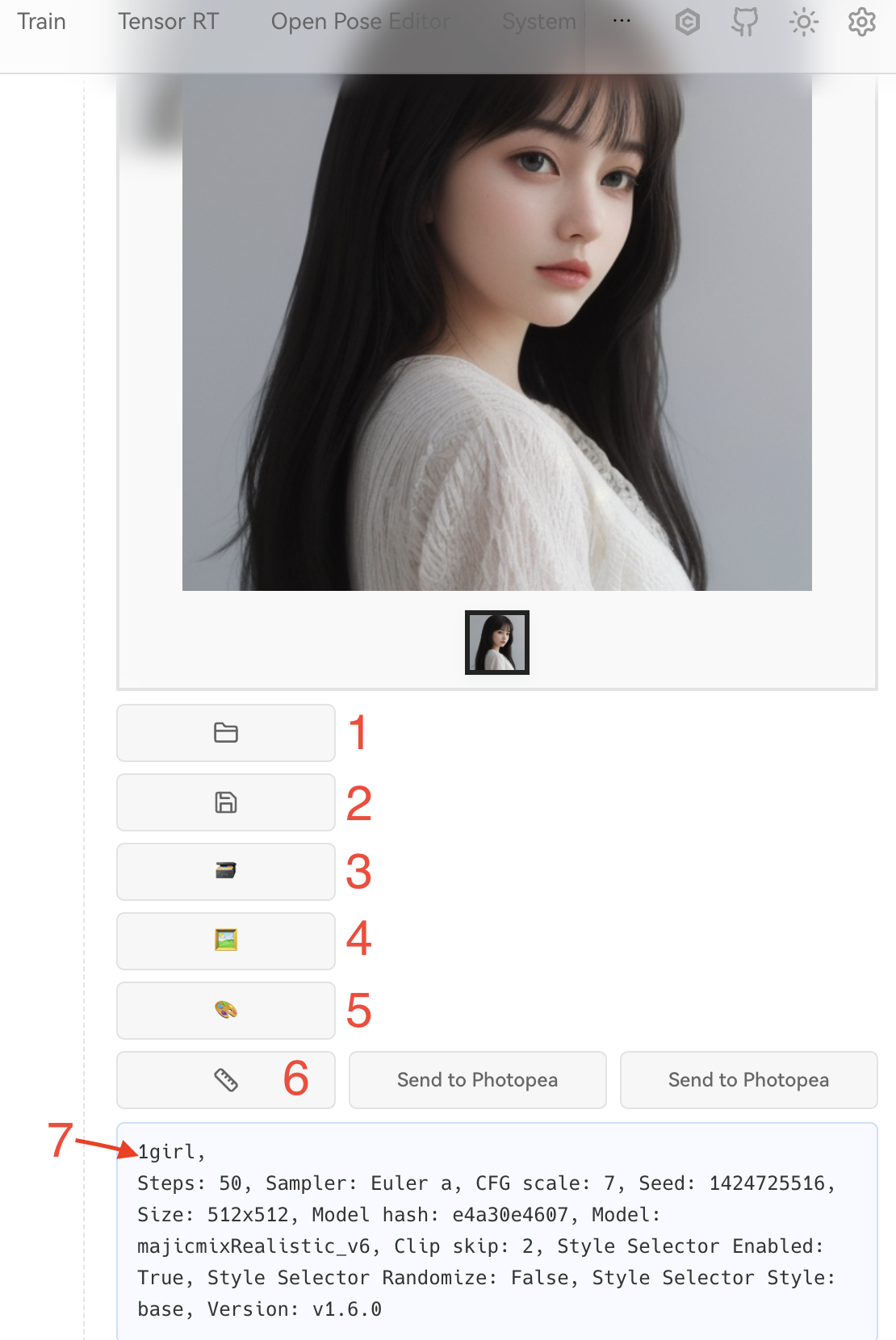
3.11 生成按钮下的功能按钮
1️⃣单击可以自动获取在生成区的图片的提示词和采样方法
2️⃣选择预设提示词里的任意一项后点击此按钮,原来预设好的提示词将自动填入正向提示词和反向提示词
3️⃣单击清空正向提示词和负向提示词
4️⃣点击添加预设样式
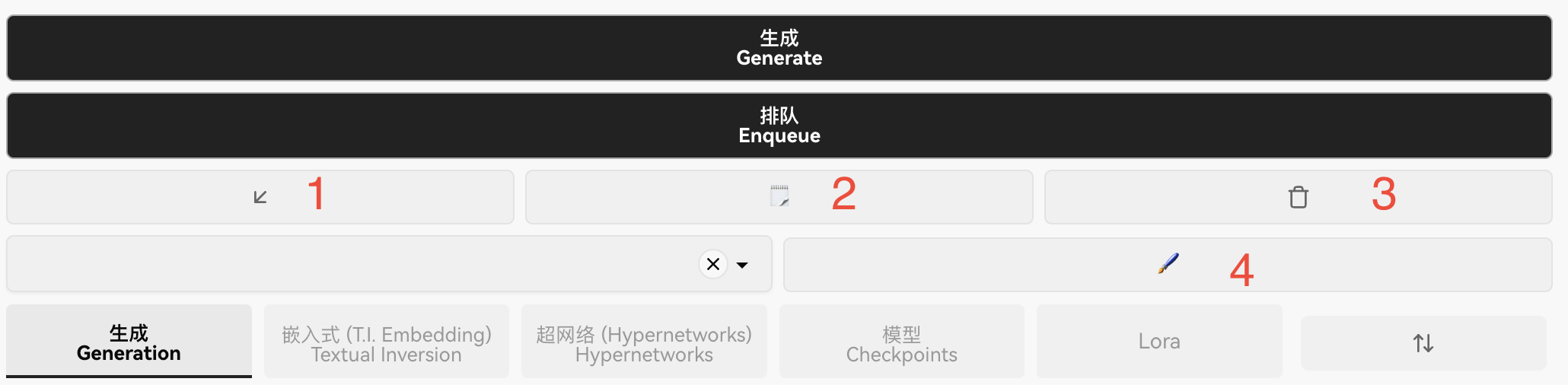
3.12 图片展示区的功能按钮
1️⃣打开存储该图片的文件夹
2️⃣保存图片
3️⃣打包下载
4️⃣发送到图生图
5️⃣发送到局部重绘
6️⃣发送到后期处理
7️⃣生成图的一些基本信息,如尺寸,迭代步数,种子值等
#3 Stable Diffusion 图生图操作界面介绍
图生图界面和文生图界面相差不多,下面主要介绍一些和文生图界面不一样的地方。
1.缩放模式Resize mode
仅调整大小:拉伸原图去适应最后出图的尺寸,经常使用
裁剪后缩放:将原图剪裁去适应最后出图的尺寸,不经常使用
缩放后填充空白:自动填充原图空白部分去适应最后出图的尺寸,经常使用
调整大小(浅空间放大):原图和最后出图尺寸不同,可能会出不了图,不经常使用

2.重绘尺寸Resize to
自己设定生成图的尺寸

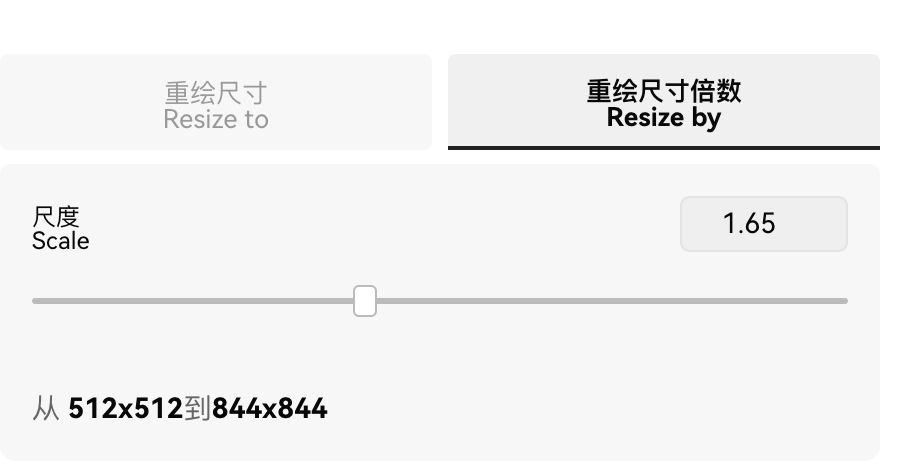
3.重绘尺寸倍数Resize by
在原图基础上,放大图像到指定的倍数。
4.重绘幅度Denoising strength
数值在0-1,越靠近0,生成的图片和原图片越像。0.1-0.4重绘幅度很小,0.4-0.7重绘修改原图,0.7-1重新创作。

5.改细节:重绘内容的几种方式
1️⃣局部重绘:
在原图上绘制一个蒙版,重绘蒙版部分或非蒙版部分,更改画面的局部细节。比如进入局部重绘,把笔划在不喜欢的画面细节处,然后点击生成,SD就会把选中的画面细节修改掉:


先用画笔将主体物周围的区域选中:

蒙版边缘模糊度Mask mode:
数值越大,蒙版的边缘被模糊度就越大,一般数值不超过4,否则画面边缘信息被模糊掉太多。


蒙版模式Masked mode:
重绘蒙版内容:重绘你涂抹的地方,其他的地方不变。重绘非模版内容:重绘没涂抹的地方,其他地方不变。
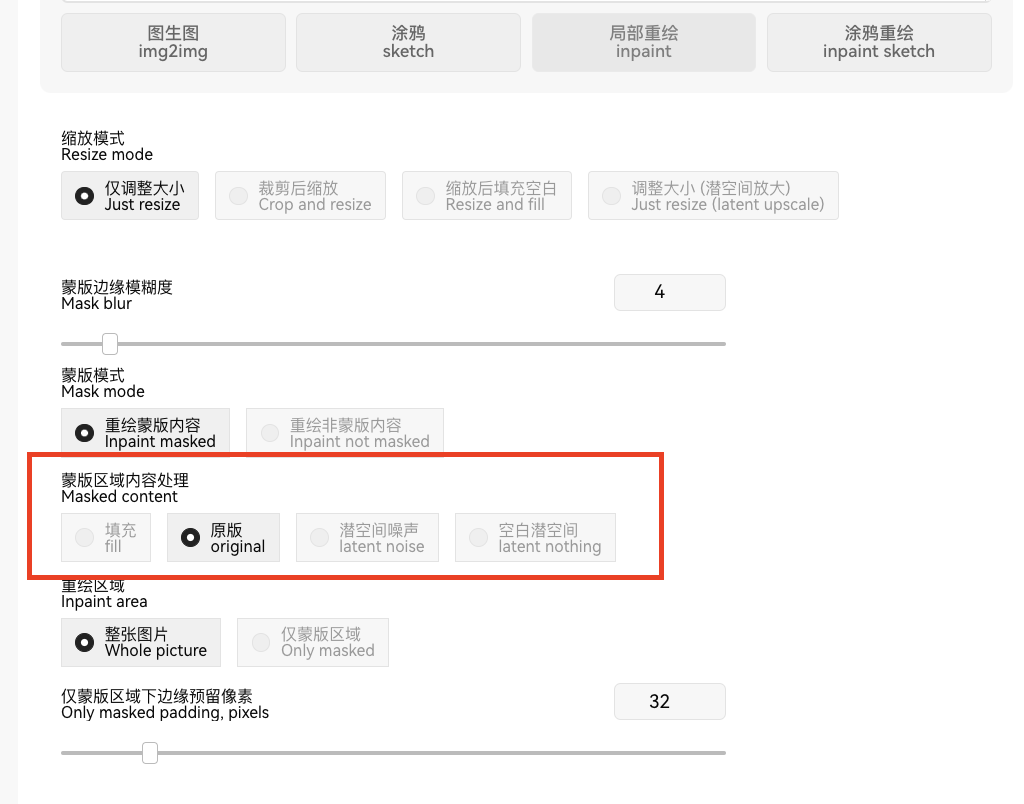
蒙版区域内容处理Masked content:
有四种模式:
填充fill,原版original,浅空间噪声latent noise,空白浅空间latent nothing
填充:不考虑原图元素,直接按照提示词生成图片,:

原版:根据原图元素生成图片,根据蒙版内容高强度模糊后的颜色重绘:

浅空间噪声:将蒙版内容压缩并去特殊化,可以理解为对蒙版内容打上一层马赛克,还加了一些乱七八糟的色块。不考虑原图的任何元素,但是比原图模式的填充会有更多的细节:

空白浅空间:彻底重绘,抹去原图信息,根据蒙版内容在潜空间的低维表示重绘,不添加噪声

重绘区域Inpaint area
整张图片:会算法到整张图片的区域,SD会把整张图片都重新画一遍,与仅蒙版模式相比,整张图片模式对重绘部分和原图的融合更好。
仅蒙版区域:只通过蒙版区域去生成最终图,SD不会变动没有蒙版区域的内容。将蒙版部分放大至原图比例进行重绘,之后缩小回去。与整张图片模式相比,仅蒙版模式重绘细节更丰富,但融合较差。
仅蒙版区域下边缘预留像素Only masked padding, pixels
数值越低,参考蒙版附近的元素就越少,数值越高,参考蒙版附近的元素就越高,画面会相对更美观一些:

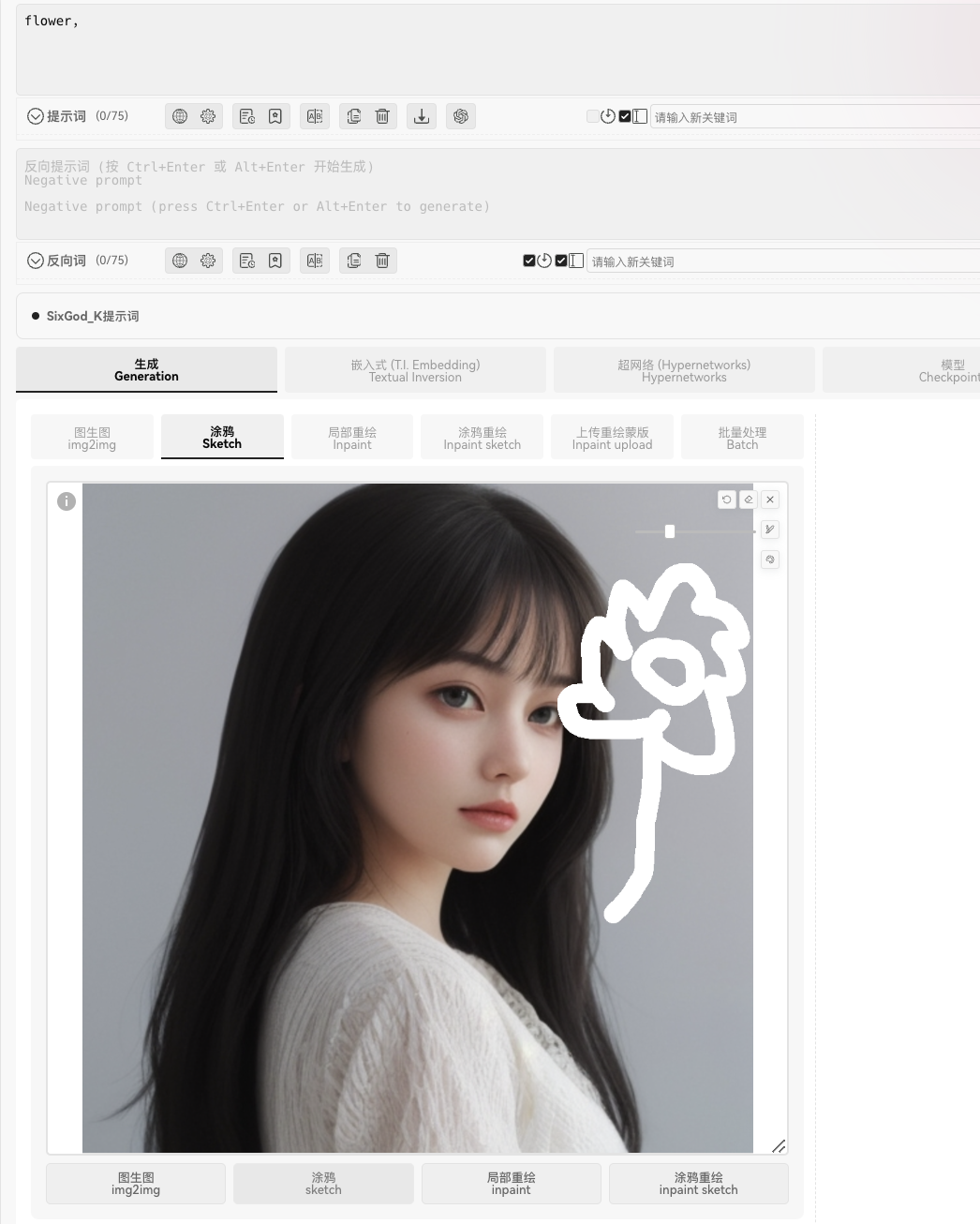
2️⃣涂鸦:
在原图的基础上涂鸦,将根据原图和涂鸦生成图片。这个感觉还是很考验手绘能力的:

3️⃣涂鸦重绘:
涂鸦+局部重绘,在原图上绘制一个有颜色的蒙版,根据颜色重绘。
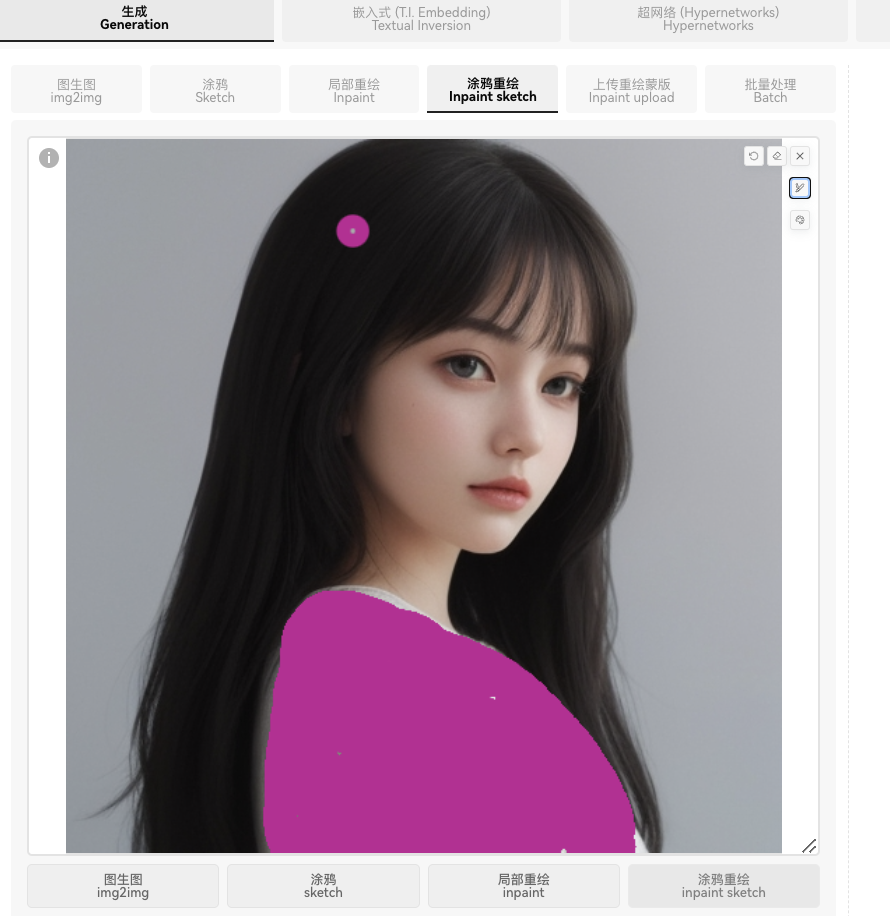

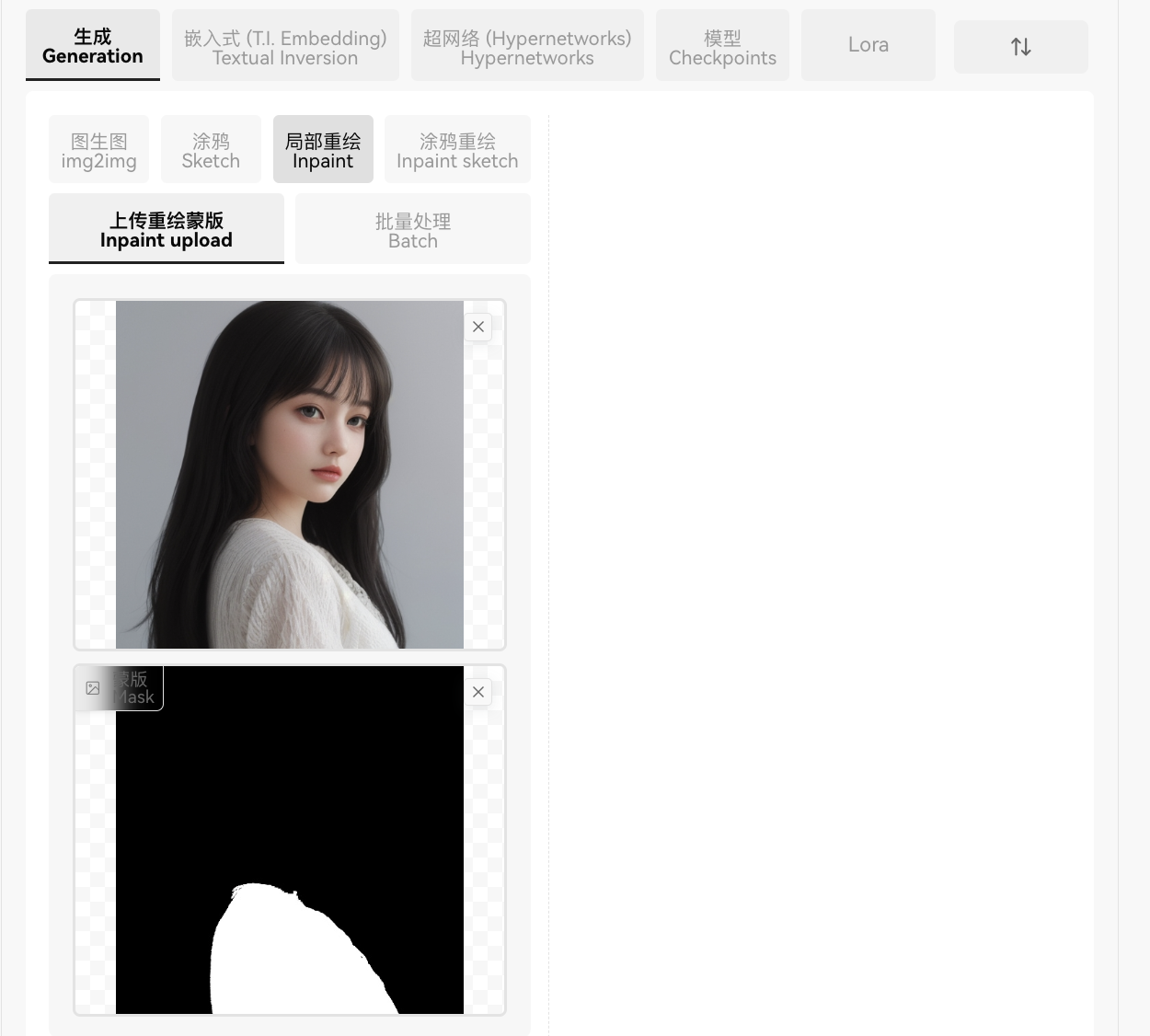
4️⃣上传重绘蒙版:
在局部重绘中,蒙版需要自己绘制,如果不想出现多画或少画的情况,就可以使用PS或者语义分割插件Segment Anything抠图抠出一个蒙版,方便精准重绘。
上传的蒙版
黑色为非蒙版区,白色为蒙版区(一般为重绘区域)
,上图放原图,下图放蒙版图。原图和蒙版图大小一致。
注意:蒙版这里需要上传jpg格式的图片,png可能会无效。

6.预览区:
保存,发送到图生图/局部重绘/高清化,图片信息。基本和文生图的预览区一样。
1
举报
声明
收藏
分享
相关推荐
























评论你的想法~
表情
喜欢TA的作品吗?喜欢就快来夸夸TA吧!
推荐素材

























你可能喜欢












相关收藏夹
























登录注册
1登录即可同步推荐记录哦
收藏登录即可加入我的收藏
评论登录即可评论想法
分享分享