通用设计法则-选择性偏差

“选择性偏差”设计法则的详细介绍。

一、什么是选择性偏差?
选择性偏差也叫做幸存者偏差,因采集数据的方式存在偏差而导致分析过程和得出的结论失真。
1、选择性偏差由样本选择的非随机性引起,因此,过分强调这些典型类别的重要性,而不顾其他潜在可能性的数据,从而造成分析和结论的偏差。
2、为了避免选择性偏差,可以考虑在研究人数不算太多的情况下,尽量让每一个人都参与数据采集。人数多时则可以采取随机抽样的方法。
二、选择性偏差的来源
“选择性偏差” 来源于二战中一个著名的故事:1941 年,第二次世界大战中,空军是最重要的兵种之一,盟军的战机在多次空战中损失严重,无数次被纳粹炮火击落;盟军总部秘密邀请了一些物理学家、数学家以及统计学家组成了一个小组,专门研究 “如何减少空军被击落概率” 的问题;当时军方的高层统计了所有返回的飞机的中弹情况——发现飞机的机翼部分中弹较为密集,而机身和机尾部分则中弹较为稀疏;于是当时的盟军高层的建议是:加强机翼部分的防护。
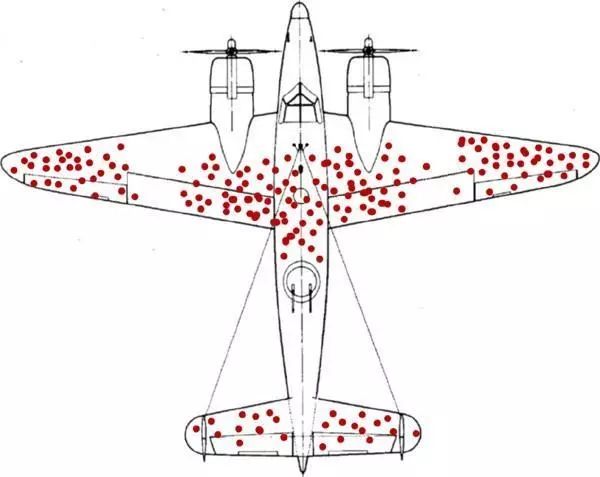
但这一建议被小组中的一位来自哥伦比亚大学的统计学教授——沃德(Abraham Wald)驳回了,沃德教授提出了完全相反的观点——加强机身和机尾部分的防护。
这位统计学家得出这一看似不够符合常识的结论主要是基于三个事实为出发点:
1、统计的样本只是平安返回的战机。
2、被多次击中机翼的飞机,似乎还是能够安全返航。
3、而在机身机尾的位置,很少发现弹孔的原因并非真的不会中弹,而是一旦中弹,其安全返航的机率极小,即返回的飞机是幸存者,仅仅依靠幸存者做出判断是不科学的,那些被忽视了的非幸存者才是关键,他们根本没有回来!
军方采用了教授的建议,加强了机尾和机身的防护,并且后来证实该决策是无比正确的,盟军战机的击落率大大降低,这就是 “选择性偏差” 故事的来源。
统计学上对选择性偏差的定义是:即我们在进行统计的时候忽略了样本的随机性和全面性,用局部样本代替了总体随机样本,从而对总体的描述出现偏差。
简单来说就是:“你只考察了幸存者所满足的特征,这并不能得出一个有说服力的结论来”,归根到底,选择性偏差就是一个由于获取信息不全导致的认知错误。
三、选择性偏差的本质
广义的选择性偏差是在进行统计的时候忽略了样本的随机性和全面性,用局部样本代替了总体随机样本,从而对总体的描述出现偏差。
统计学的简单描述是这样的:
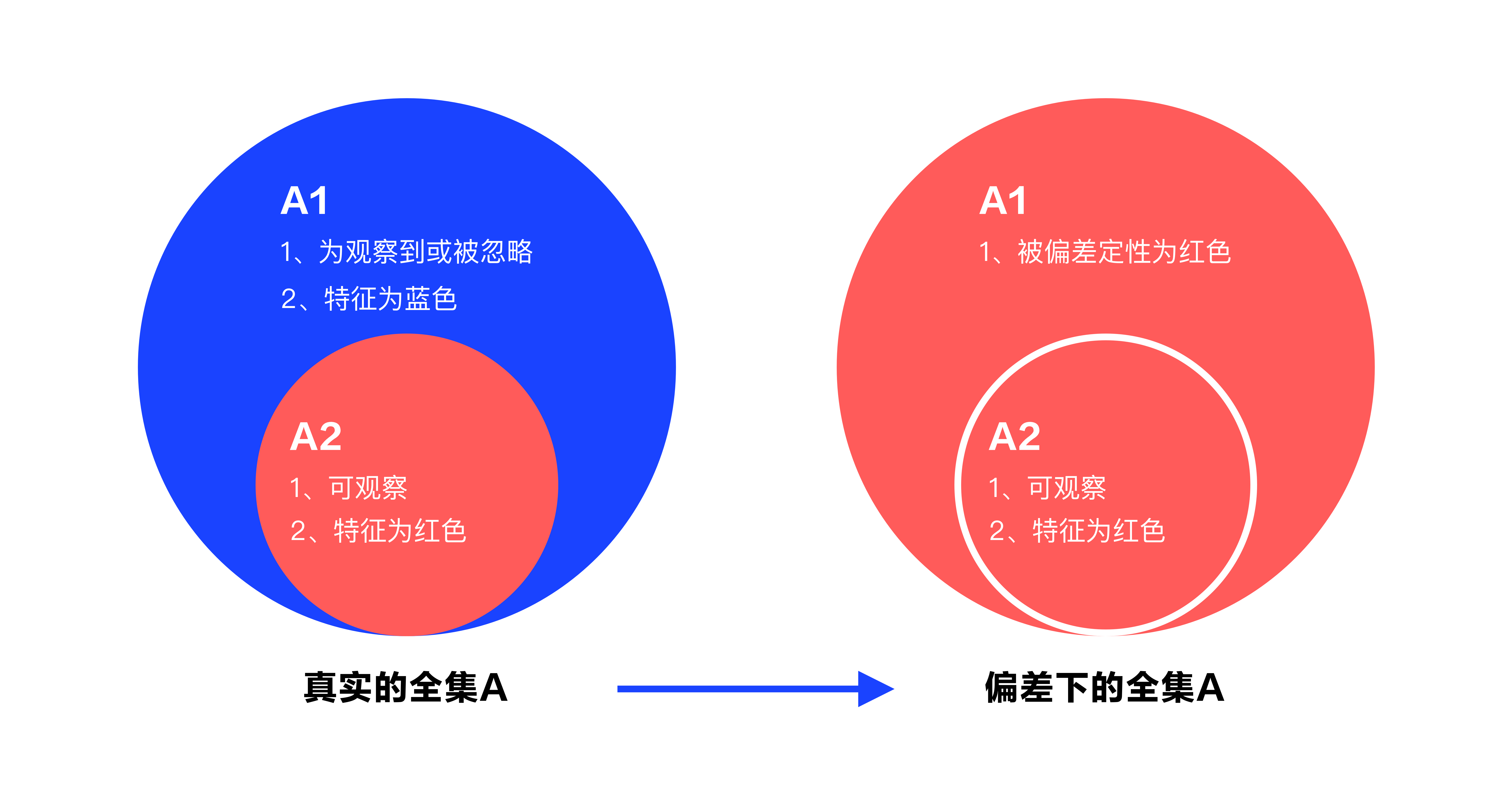
比如统计全集为 A,观察到 A 的子集 A2 有特征红色,A2 为幸存者,而 A 另外的子集 A1 并没有观察到或者被人为忽略,于是判断全集 A 都有特征红色,事实上 A1 的特征为蓝色。
用一个记者调查买火车票的案例来代入解释为:
一个记者在火车上问大家都买到车票没,大家的回答都是买到了,所以皆大欢喜,结论是大家都买到了回家的车票,但这结论是有错误的,因为没买到车票的人根本就没上车,没有机会回答调查问题。
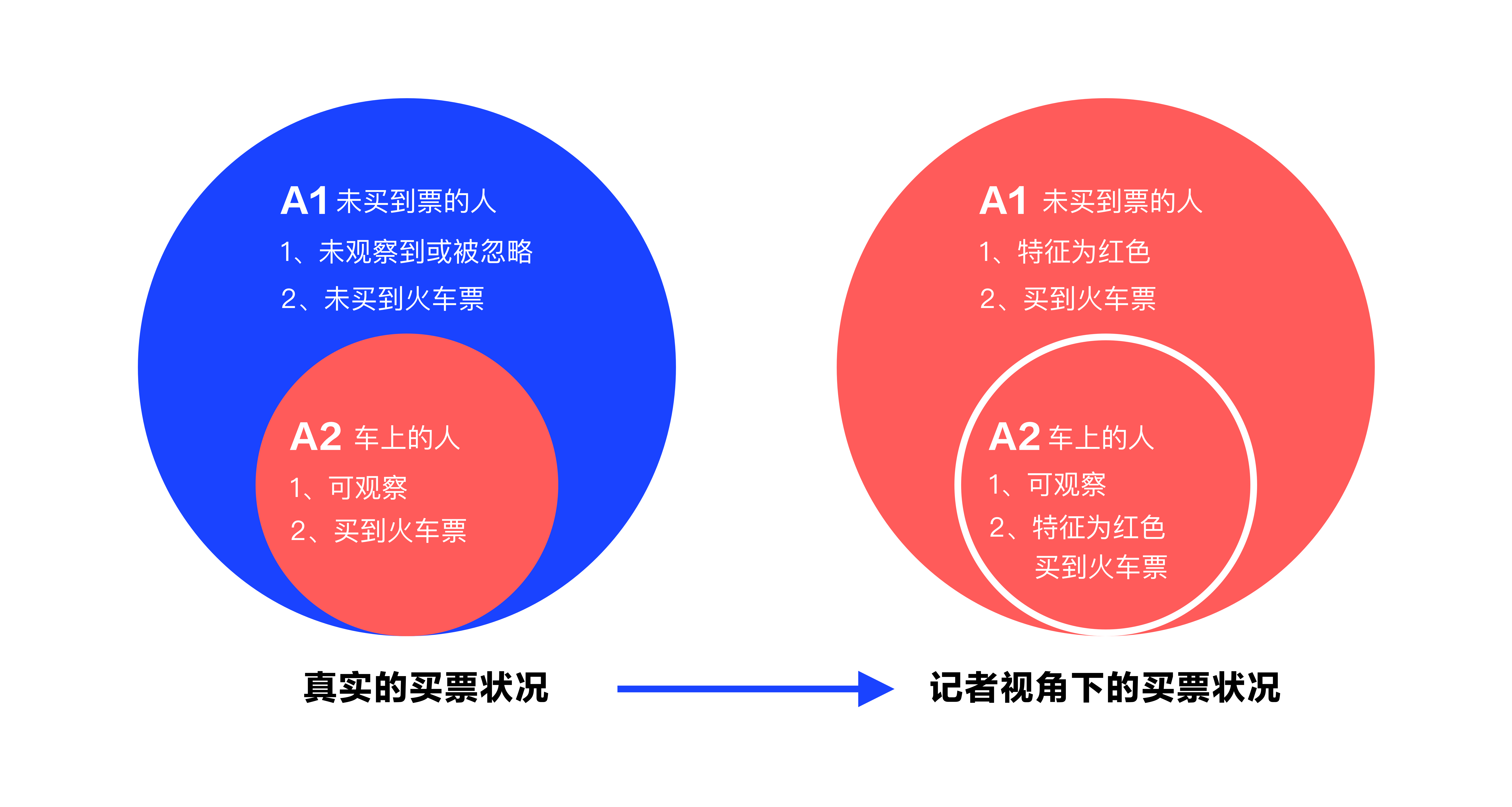
在这里 A 为全体想买火车票的人,A2 为已经在火车上的人,A1 为想买但没买到的人,特征“红色”为买到票,特征“蓝色”为未买到票,即选择性偏差将一小部分显性样本代替了随机样本,从而导致了统计的偏差。
有了这个框架,我们就能从理论的角度理解这些 “选择性偏差” 的具体案例了:
日常生活中的选择性偏差;
1、淘宝上卖极限运动设备的商家,尤其卖降落伞、滑翔伞的卖家好评都是满的,从来没有差评。
解释:因为能发好评的都是用了,活下来的,想发差评的冤魂表示没有机会,也就是根本没有被统计到。
2、在家里买菜做饭的老妈,整天和她朝夕相处,会发现她从不挑食。
解释:老妈做饭之前买菜时买的都是她爱吃的菜,从原材料起,食物样本的随机性就已经被筛选过了,所以做饭的老妈从不挑食。
3、家里的老物件可好使了,现在的产品真不行,买来几天就坏了,所以结论是现在的厂家没以前的有良心,产品质量差!
解释:不好用的都丢了,剩下来的都是质量相对好的。
4、章鱼保罗案例
2010 年世界杯最大的明星不是来自某个球员,而是来自德国奥博豪森海洋馆的章鱼” 保罗 “,它神奇地连续 7 次百发百中地预测了世界杯德国队的比赛结果,章鱼保罗成为那个夏天世界媒体热情追逐的对象。
解释:然而事实上它就是一次典型的” 幸存者偏差 “,那年夏天其实有很多动物都参与了世界杯的预测:菲律宾的猴子、墨西哥的羊驼、非洲的大象、保加利亚的奶牛甚至还有中国的熊猫,只是因为这些动物预测失败了于是并没有媒体报道,而章鱼保罗成为那个幸运儿。

四、产品设计中的选择性偏差
“选择性偏差” 是在产品的数据分析中常见的逻辑错误,
怎么在在分析数据、决策判断时避免 “选择性偏差”, 这里有了三个步骤:
1、判断样本的随机性,就是必须知道样本是否是随机的。
2、判断样本和剩余样本中会不会存在显著差异。
3、分析剩余样本数据,验证结论。
那我们可以用几个案例来分析验证:
案例一:视频网站案例
某视频网站在 VIP 中新上线了一部新剧,该剧每一集的观看人数之前一直稳定,但当它播到第七集的时候,观看人数有一个相对明显的流失,运营人员开始分析认为是该部剧从第七集开始剧情急转直下主角忽然挂掉引起的,
然而当他们仔细分析流失用户的时候,发现流失的都是因为三个月前某次大规模赠送的免费会员到期引起的,只是时间正好和第七集重合而已,普通会员根本没有流失。

在这个案例中三步分别为:
1. 判断样本随机性,就是分析流失用户是不是所有会员的随机样本。答案是否定的——流失的都是免费会员。
2. 判断样本和剩余样本会不会存在显著差异?即正常会员和免费会员有没有差异?当然有差异。
3. 分析剩余样本数据,验证结论,即看正常会员是否流失。
所以结论是普通会员没有流失。
案例二:Facebook 视频广告案例

2016 年 9 月年 Facebook 关于视频广告数据偏差的问题变成了该公司广告历史上不大不小的负面新闻,Facebook 在其官方博客中承认:其提交给广告主的数据报告中,视频广告平均播放时长的数字只统计了那些播放时长超过 3 秒的播放行为,也就是说,如果视频播放没超过 3 秒,Facebook 居然就把它舍去了,
很显然,广告主的平均播放时长被拉长了,因为播放时间短的压根不统计,而这一偏差居然存在了长达两年之久。
这个案例中,分析依然分为三步:
1. 判断样本随机性——3 秒以下的都舍去了!当然没有随机性!
2. 判断样本和剩余样本是否存在显著差异?3 秒以下和 3 秒以上肯定有差异!
3. 分析剩余样本数据、验证结论。 验证数据是否准确
所以结论是广告数据报告不准确。
五、如何避免 “选择性偏差”?
那我们该如何避免选择性偏差呢?首先,要了解选择性偏差产生的原因。
选择性偏差的根本原因是逻辑学和统计学的谬误,本质是统计时忽略了样本的随机性和全面性,用局部样本代替了总体随机样本,从而对总体的描述出现偏差。
一般而言,选择性偏差的产生有以下3个条件:
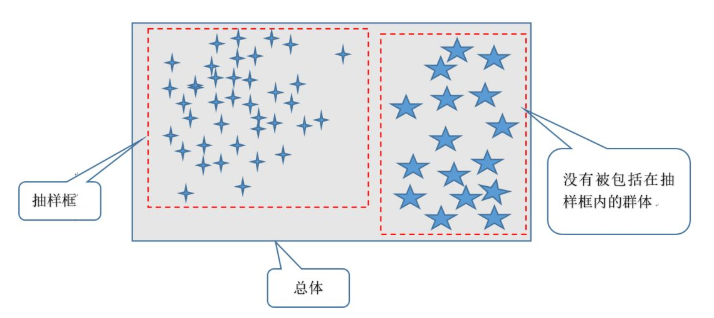
抽样统计。如果能全部检查,了解到完整的事实,得出的结论自然不会有偏差。
被调查的总体分布不均匀。如果总体分布均匀,抽样统计通常是不会有选择性偏差的。
抽样时总体中的一个或一个以上的具有不同分布的群体没有被包括在抽样框内,如图:
此外,选择性偏差也会体现人性的弱点。
一般来说,我们只会关注到结果本身,但对于结果产生的过程却很少注意到。
在这个过程中,我们分析问题所依赖的信息全部或者大部分来自于“显著信息”,较少考虑“不显著信息”,甚至是忽略“沉默的信息”。
而被筛选掉的信息,要么是我们不会关注,要么就是被“隐藏”了。
由此,根据有问题的信息,我们就得出有问题的结论,最终会导致选择性偏差。
很多选择性偏差问题,是非常隐蔽,危害性也相当大的,这是人性中的弱点所致,宗教则是有效的击中了这些弱点而大行其道。
所以,“选择性偏差”几乎是不能完全消除或克服的,但我们应该努力去降低其对我们造成的损失,
所以这里有3点建议可以避免选择性偏差:
1、关注“沉默”的数据
首先要意识到了“沉默证据”的存在,你才有机会获得更全面的认知。
看惯了朋友圈、抖音的朋友总是容易产生一种想法:买名牌包、吃豪餐、国外旅游已经是中国常态。
但拼多多的崛起让“沉默证据”发力:原来购买廉价产品,为了几毛钱动员砍价的人,才是中国人口最广的群体。
耳听不一定是真,眼见也不一定为实。需要打破惯性思维,躲开显性证据,看到背后的隐形证据。
2、学好数学和统计学。
举个例子,基金行业会对外宣布,过去10年,基金行业的整体收益率超100%,然后就会觉得自己马上要赚翻了,
实际上,基金行业统计的,全是现在市场上活着的基金,那些不赚钱死掉的,都没算进去。
如果把死掉的那些也考虑进去,那基金的整体收益率其实很一般。
3、提升认知水平
有的时候“选择性偏差”心理的存在,很大程度上是因为自身认知水平确实有限,也就是自己只知道某些表面的信息,根本不知道那些关键信息的存在,最后导致判断失误。
所以,在平时我们也要多注意学习提升,开阔自己的视野,扩大自己的认知范围。
换个角度讲,就是当你想要做某件事或者做出某种决定之前,一定要尽量全面的了解相关的信息,从正反两个角度去思考事情的发展。