时间长、样本小,可用性测试如何数据分析?

可用性测试因为耗费时间较长,能够参与测试的用户资源稀缺,回收样本量小能够收集到的样本量一般会比较小。
可用性测试
因为耗费时间较长,能够参与测试的用户资源稀缺,回收样本量小能够收集到的样本量一般会比较小。样本量小的情况下这个样本量所能概括的整体是范围比较大的,会存在较大误差,那么在较为严谨的报告中,可能需要对所得分数和除测试样本外的分值预期进行描述,这时候会涉及到统计学中常用的描述方式,即通过置信度及置信区间来描述,根据置信区间的下边界看软件是否低于行业标准。
置信区间
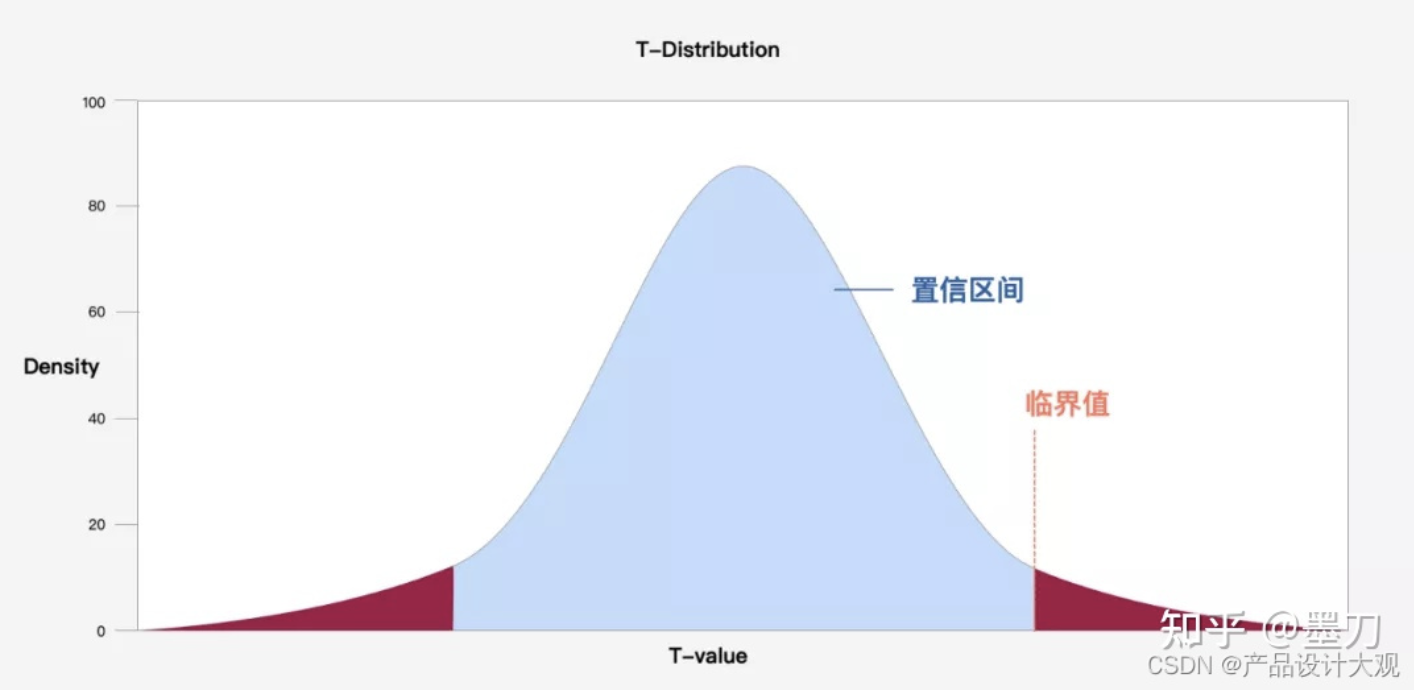
是指在一定概率下包含样本位置总体参数的这部分数值区间,通过计算置信区间来描述测试结果的概率。置信区间宽度和样本量之间是一个逆平方根的关系, 样本量越小,误差越大,未知样本数据可能所在的区间更大。
置信度就是说,你测得的均值,和总体真实情况的差距小于这个给定的值的概率,应该是1-α;换句话描述,即我们有1-α的信心认为,你测得的这个均值和总体的实际期望很接近了(测得的均值就是总体期望是很草率的,但是说,我有95%的把握认为我测得的均值,非常接近总体的期望了)。研究员可以选择0%-100%之间的任意数值的置信度,通常设为90%或95%(最常用)。
临界值是在原假设下,检验统计量在分布图上的点,这些点定义一组要求否定原假设的值。
置信区间计算
置信区间= (样本平均值-误差幅度)~(样本平均值+误差幅度)=(x -(x- μ))~(x +(x- μ))
x = 样本平均值 误差幅度=临界值*(样本标准差/样本量的平方根),即:(x - μ) = α* (s / sqrt(n)) α=临界值(Excel函数=TINV(1-置信度,样本量-1))
μ=被检验的基准值(行业标准)
s=样本的标准差(Excel函数=STDEVP(N1,N2,…))
n=样本量
tips:临界值可以通过所设置信度和样本量在t分布表中查找相应的值

可用性测试策划应用
在做可用性测试前,需要进行很多准备,过程中也需要记录很多相关的信息,初步尝试的设计师可以参照以下步骤完成可用性测试的整个流程:
Step1: 确定调研目标(目的、用户、时间、环境)
Step2: 确定测试任务(任务内容、测试方案、SUS问卷地址),任务内容可以通过抽取用户体验地图(User Journey Map)流程中的触点设计,保证流程的完整性和任务的关联性
Step3: 引导测试用户完成可用性测试,过程中记录测试时间、用户遇到的问题、发生的频率等等,记录类型可以根据测试测中点进行记录
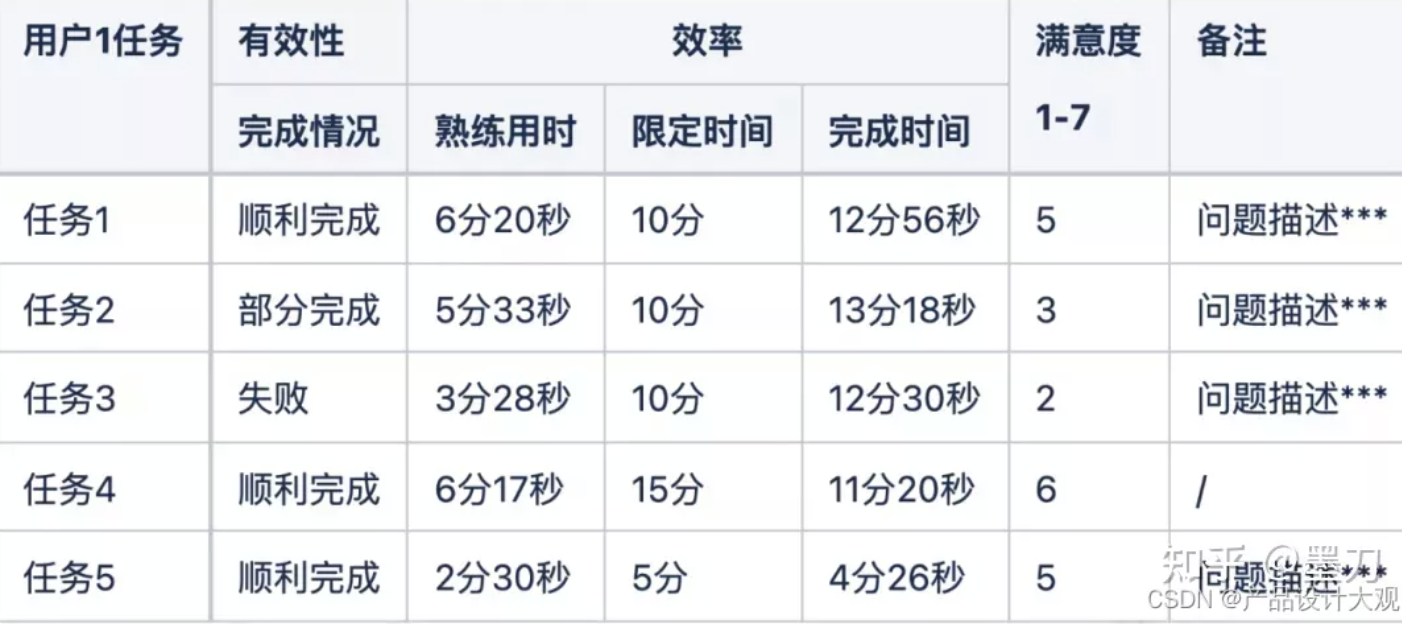
Step4: 用户填写SUS问卷,回收问卷分数进行计算,得出SUS分数、可用性分数、易用性分数的均值作为本次测试的结论
Step5: 作为补充,可以计算SUS样本分数的置信区间,预期未被测到的目标用户对产品的评分可能落在的区间,区间下限可横向对比,看是否低于行业标准。可以描述为“样本分数标准误差约=5.34,置信区间为63.78~69.12;有95%的把握认为测得的均值接近总体期望,未测样本分值将落在63.78~69.12之间,符合行业标准预期”。
Step6: 通过测试过程中观察用户行为,探讨用户提出或下意识忽略的问题,并进行问题的记录和分类
Step7: 用户访谈记录问题进行解析,对问题的严重程度进行评级,选出问题较多的部分并提供可能的解决办法进行优化
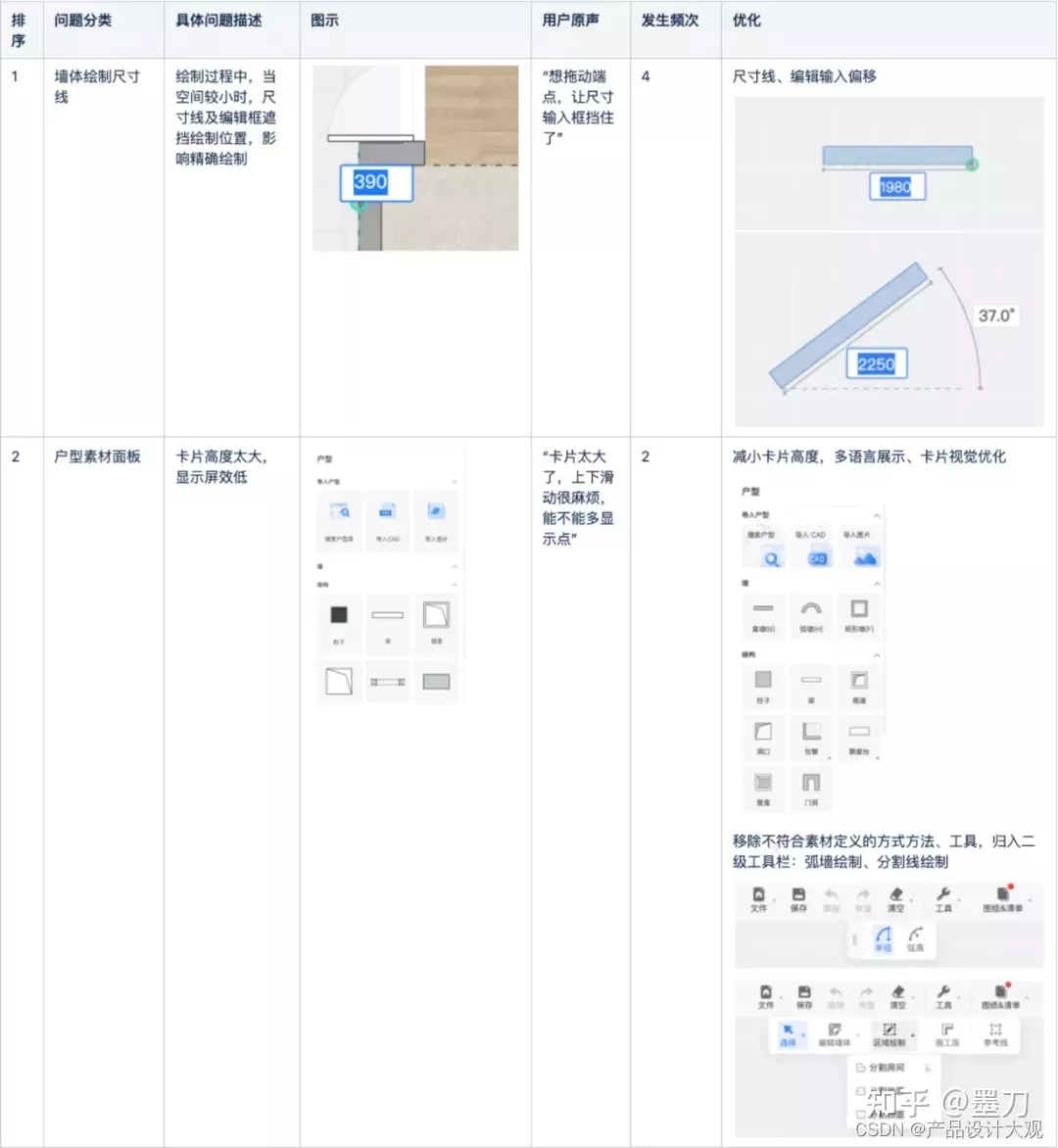
Step8: 根据以上结论对测试进行总结性分析