Web 3D避坑指南


我们用“QQ阅读会员装扮”项目,从场景还原、场景交互及性能优化三个方面分享3D项目开发的流程、以及一些典型问题及解决方案。
“随着越来越多web 3D项目的出现,h5的表现性和交互性日益丰富,如果说设计和创意决定了产品上限,我们能做的就是不让技术成为缺失的短板,开启Web3D的实践之路刻不容缓。
今年团队在3D方向上做了一系列的研究和项目实战,我们用“QQ阅读会员装扮”项目,从场景还原、场景交互及性能优化三个方面来展开,分享3D项目开发的整体流程、以及过程中遇到的一些典型问题及解决方案,本文大量干货请耐心食用。
可使用微信 扫描文末二维码体验线上项目(由于其他因素,最终上线版本在细节上有些改动)。”

———
Part 1. 3D世界之初
要实现3D场景的渲染,我们首先要构建场景内的“物体”,实际项目中要展示的物体通常都比较复杂,由设计同学来完成这部分建模工作;我们在项目里先后尝试过 C4D 和 Blender 两种建模软件,后者在便捷性、和前端对接的兼容程度等各方面都不错,更适合 Web 端的开发合作。
然后就要选择合适的模型文件格式,目前对于web 3D来说,gltf 格式 已经是不二选择,相对于其他格式,gltf 在模型导出的过程中遇到的问题是最少的,文件大小、解析速度等综合方面都比较优秀,也能很好的保留模型的骨骼动画,大大减少动画开发成本;在模型导出时有一些需要和设计同学对接的细节,后文会提到。

有了物体模型,为了让用户看到的更贴近设计,前端侧进要更多细节的还原,比如动态变化的物体阴影、真实的光影氛围以及复杂的后处理,这些因素都会影响模型最终的渲染效果,接下来我们看看两个主要的优化点。
优点一 增加更丰富的光源
在现实世界里,我们的眼睛之所以能够看到世界万物,是因为光的存在,3D世界也是如此;而光的色彩、强度、光的折射与反射都会影响整个场景的视觉效果,对物体的质感也起着决定性的作用,因此,为场景建立真实细腻的光影空间就尤为重要。
导入模型后,首先添加基本的环境光(AmbientLight)、平行光(DirectionalLight),这时候的光源都比较单一,场景看起来不够生动,模型表面的材质看起来有点“干”;
为了突出箱子模型的材质细节,设计同学想要更明显的金属反光效果,于是我们增加了 “环境光”,首先选一张合适的 HDR 格式的图片,作为整体的 环境贴图 ,大致原理是把环境贴图通过算法映射到材质上,就好像“模型真实的放置在场景中”,来模拟真实场景中更细腻的光影,可以看到处理的前后对比👇


BEFORE AFTER
光线明亮一点的场景效果会更明显
现在场景已经准备就绪了,在最终渲染到屏幕之前,我们还可以在GPU中添加更丰富的视觉处理,就需要用到“后处理(PostProcessing)”。
优点二 后处理:局部的辉光效果
后处理是图形渲染的一种处理技术,相当于给场景再做一次“ps”,常见的操作比如抗锯齿、体积光、描边、故障效果等等,我们把每种功能集合到一个 通道(pass)中,依次进行处理,并在最后一个通道里渲染到屏幕,就组成了后处理的通道流水线。
在这个项目里,我们想增加道具们的质感,让局部的区域向外散发微弱光芒,也叫 “泛光” 或 “辉光” 效果;在three.js中的具体实现方案不过多赘述,主要就是用效果组合器(EffectComposer)替代原有的 Renderer 进行渲染,但由于通道的处理是针对整个渲染结果,那么遇到的一个难点就是如何针对“局部物体”做自发光,目前找到了两种可以实现的思路:
方案 1 叠加两次通道
可以参考官方的 局部泛光[1] 例子,简单来说就是一次pass做整体的泛光,再加一次pass削弱暗部的泛光,可以看到整个箱子应用之后的效果 ⬇️

虽然发光的区域有了效果,但是箱子的其他暗部区域光线过暗,模型的纹理细节也消失了,因此这个方法对模型的贴图会有要求,不仅要求泛光与非泛光区域有足够的对比度,而且还会很大程度影响材质的细节表现,所以不适合我们的项目;不过这个思路感觉有很大的发挥空间,也许有更合适的着色器,可以做进一步的研究。
方案 2 分层加单帧两次渲染
这个方案就非常的巧妙,先利用分层(layers)区分场景中的自发光物体:
/* 这里要使用enable 而不是set,不然第二次渲染时自发光物体就会丢失 */
bloomMesh1.layers.enable(1)
bloomMesh2.layers.enable(1)
在每一帧的渲染中,先执行一次泛光处理的渲染
/* 关闭渲染器的自动清除,每一帧的开始手动进行一次clear */
_Renderer.autoClear = false
_Renderer.clear()
_Camera.layers.set(1)
_Composer.render()
然后 layers 重置为0,再做一次整体的正常渲染
_Renderer.clearDepth()
_Camera.layers.set(0)
_Renderer.render(_Scene, _Camera)
这样两次渲染叠加后,就可以保物体的光晕效果,下图的挂件利用这种方式实现了局部泛光的渲染;

不过这种方法的局限性于在于,泛光物体的后面不能有非泛光物体,只能是空背景,否则光晕就会被其他物体覆盖掉,所以也要根据项目实际情况使用。
———
Part 2. 让场景可交互
到了这里,场景基本的渲染就完成了,既然是3D项目,用户的可交互性才是区别于2D项目的关键所在,那么要实现对3D场景中的物体进行交互,对于点击、mouseover这种操作,首先需要判断用户点击的是哪个物体,我们来看一下如何实现。
一 raycast 射线拾取
最常用的方式就是 光线投射(Raycaster),大致原理是先把鼠标在屏幕上的点击位置转化成一个3D空间中的“二维向量”,想像成向空间内发射一条射线,再对这个向量和物体做相交性计算,判断向量是否命中目标物体,这样就可以把二维屏幕中的交互映射到三维世界中。
普通的几何体检测比较简单,然而实际项目使用模型的通常会带有骨骼,要知道three.js中是无法对 Bone 、Group去进行检测的 ,这时需要找到物体对应的 SkinnedMesh(蒙皮网格) ,模型层级不复杂的话,可以考虑检测时直接开启后代的递归;
为什么只能用 SkinnedMesh 去做检测呢?从three.js代码层面去看,一个类型能不能被检测到,关键是取决于这个类有没有重写基类中的 .raycast() 方法,实际运行检测时,也是去调用每个物体自身的方法,了解具体的代码可以看看 源码 [2] ;
规避了这个问题之后,如果我们发现点击物体时还是无法正确选中,那要看看是不是包围盒出了问题;
找到 “包围盒”
简单的说,我们使用的模型通常都是一个不规则的几何体,用一个“尽可能小”的立方体盒子把它包起来,这个小盒子就是它的包围盒(bounding box),在three.js里用 box3 来表示,根据不同的计算方式有轴对齐包围盒(AABB)、有向包围盒(OBB)等等;可以用辅助工具看到它,比如下图中的黄色线框盒子,就是宝箱的包围盒。
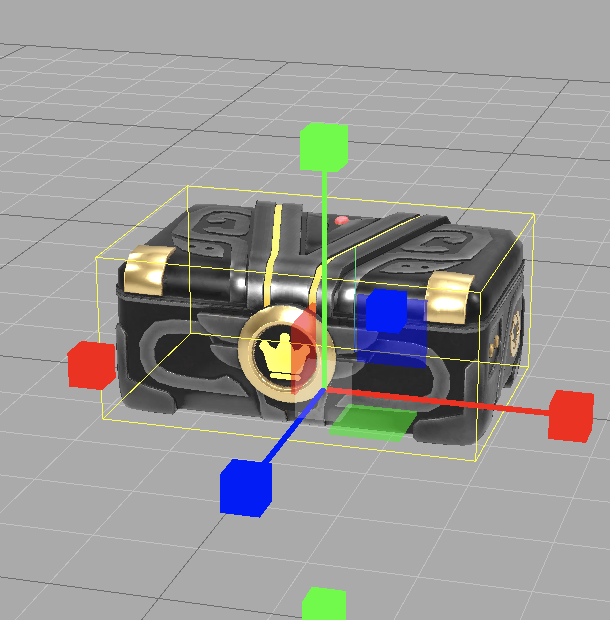
它可以用来做很多事情,比如光线投射、碰撞检测时,用包围盒来代替不规则的物体先进行过滤,当包围盒命中时再进行精确检测,进而提高检测算法的效率;
于是在这种策略下,实际会被命中的区域,并不是我们直接看到的模型区域,而是“包围盒区域”与“模型区域”的交集,如果包围盒出现偏差,那么检测结果自然会出现问题,我们来看两个常见的错误情况;
01 物体坐标系导致的包围盒偏移
设计同学在建模时,包含骨骼的物体需要 “模型原点” 与 “世界坐标系的原点”保持重合,也就是说 position 的值要设置为(0, 0, 0), 需要做旋转位移的物体,不能在模型里设置,由前端导入模型后再设置就好,否则导出模型后就会发生包围盒与物体偏移:

02 带有骨骼动画的物体包围盒无法动态更新
物体坐标点归零之后,点击可以被正确检测到了,但是当模型播放 骨骼动画 时,就会发现点击又出现了偏差。
因为骨骼动画的渲染更新是在GPU中完成的,而射线检测在CPU中计算,它只根据模型静态时的位置和形状做相交判断,无法获取动画时动态的模型数据,所以就出现了问题;这个问题在官方issues也一直有 讨论 [3] ,比较普遍的解决方案是放弃射线检测,采用另一种 GPU拾取 的方式,大致思路是给每个模型对应一个颜色,离屏绘制渲染之后,再根据鼠标的位置读取像素颜色,然后反推对应的命中物体;这种方式虽然会增加渲染复杂度,但是对于比较复杂的场景可以降低cpu的计算开销,是一种可考虑的方案。
不过在项目中和设计同学反复尝试时,发现可以在建模时改变模型的 包围盒 ,使包围盒能够包含模型所有动画过程中的轨迹,这样不管在模型静态,还是执行动画的过程中,都能被正确检测到,也可以比较巧妙的解决这个问题。

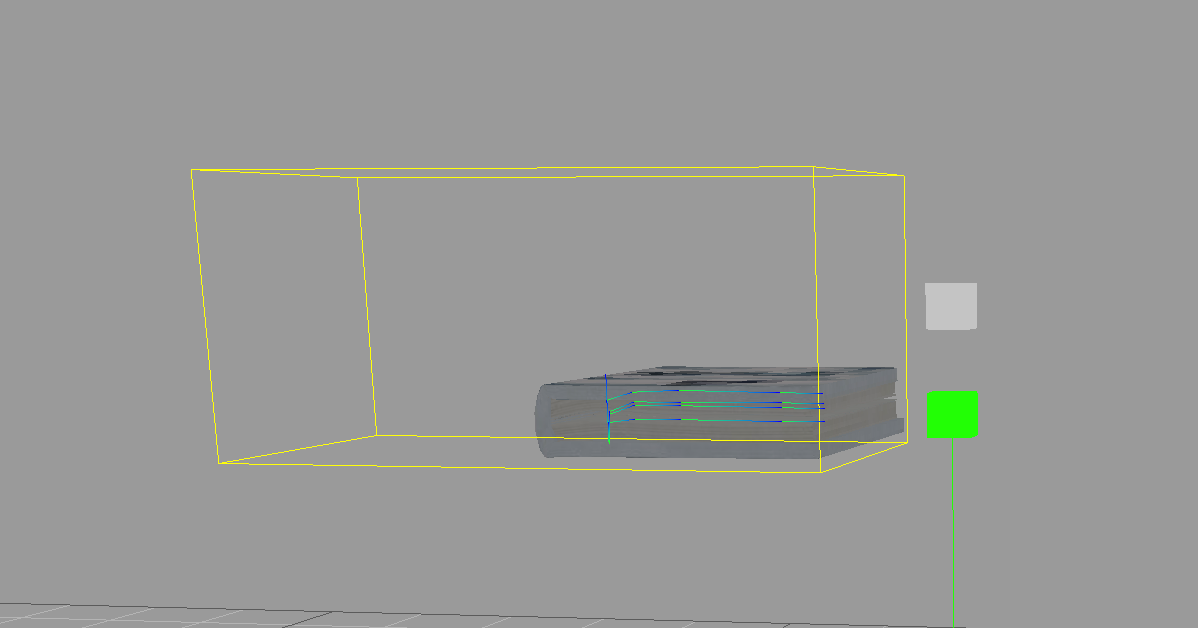
此时的包围盒包含了书本动画中的所有的顶点位置
二 物体的三维变换与镜头移动
用户有了交互行为后,我们希望给出相对真实的反馈,实现更沉浸的3D体验,在项目中使用到了很多物体的移动、缩放、旋转操作,以及“镜头移动”的视觉效果;

这些看似简单的基础的操作,实现过程中也会遇到一些细节问题。
01 转的实现 —— 欧拉角的原理
物体的旋转是最常见的,而我们使用 rotation 设置旋转角度时,可能会发现最终显示效果和想象不一样;
举一个例子,我们先把一只企鹅依次按照 X旋转90度 -> Y旋转90度 -> Z旋转90度 进行旋转:


由此可见动态欧拉角的一个重要属性:旋转顺序 ,它使用局部坐标系来旋转,也就是说,旋转过程中,坐标系会随着旋转和发生变化,那么不同的旋转顺序就会得到不同的旋转结果;
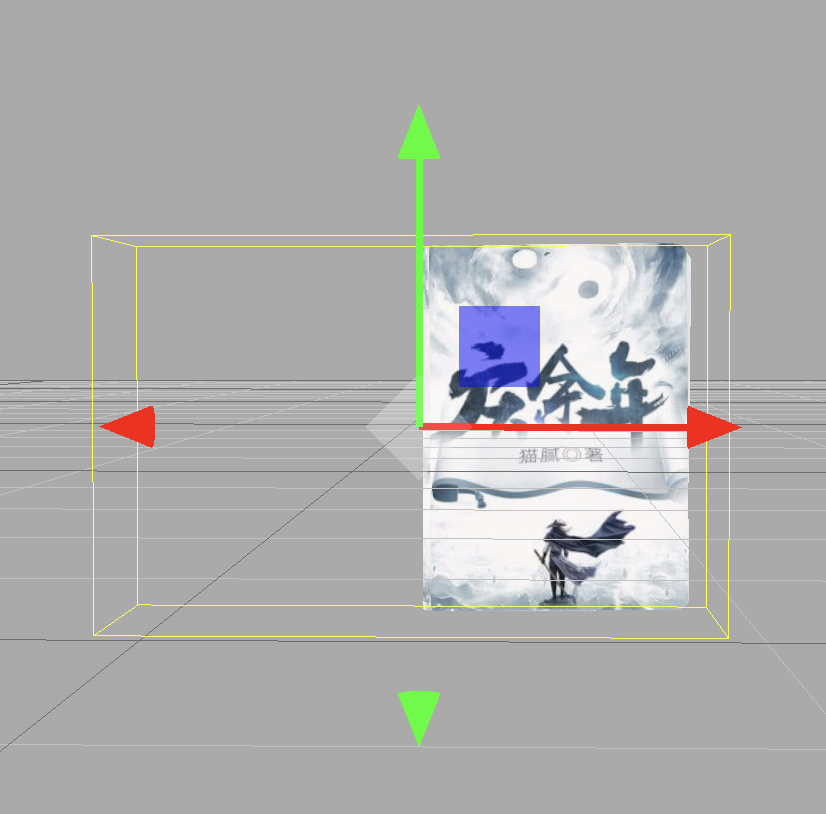
而three.js的 rotation 默认顺序是 XYZ,无论你操作顺序是怎么样的,最终都会按照xyz的顺序进行旋转,因此在进行比较复杂的多角度旋转时会有问题,比如下面的书籍,从箱子飞出来时已经围绕 X轴 和 Z轴 做了旋转操作:

然后在此状态下,想要在用户滑动操作时呈现下图“绕Y轴旋转”的效果,这个场景就不能用 rotation.y 来实现了;
一个很方便的替代方案就是用 rotateOnAxis(new THREE.Vector3(0, 1, 0), chg) 模拟Y轴旋转,这样就不会受到欧拉角旋转顺序的影响。

02 注意模型的原点位置
接下来第二个很关键的问题,在建模时,就要注意和设计同学沟通好模型的原点位置,我们前面说过,绑骨模型的原点要重合于世界坐标系原点,除此之外,如果物体需要旋转,还要根据所需要的旋转效果把原点放置在物体的 旋转中心;但有的时候,物体可能会需要两种不同轴心的旋转,怎么办?
还是看上面书籍的例子,这是它自身的旋转轴⬇️,可以完成书本合上状态时的旋转。
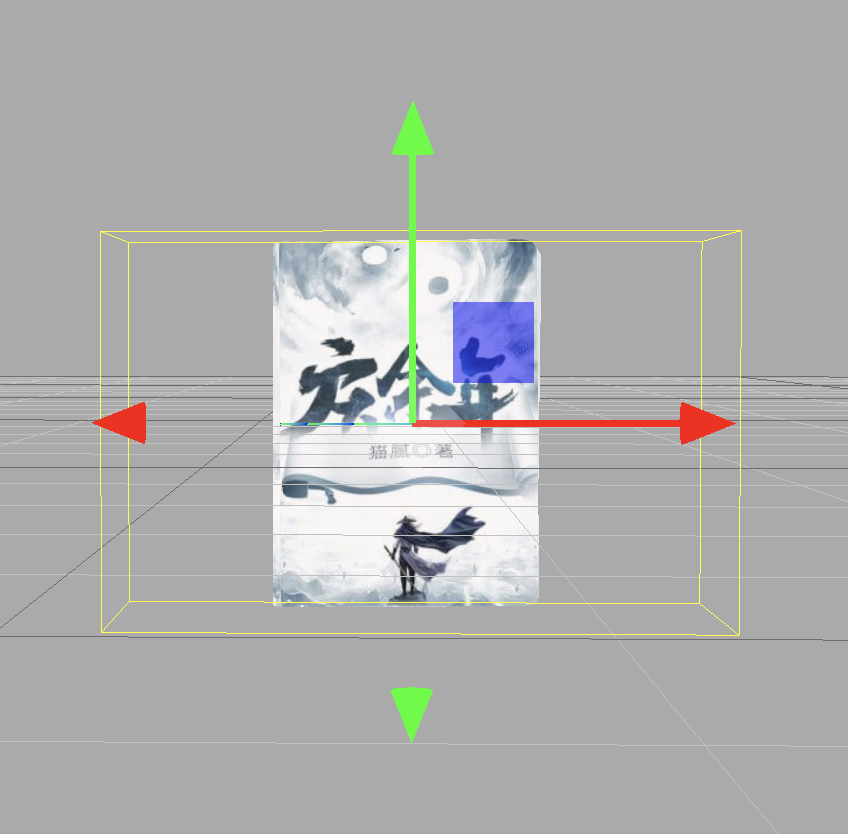

当书本打开时,我们需要一个位于书籍中缝的轴心,一种方法是 外面套一个父容器,利用父容器的轴心来实现旋转 ,我们在外面套一个像图中黄框大小的父容器,旋转时直接操作外面的容器,就可以模拟书籍打开时的旋转效果了。

03 如何实现第一视角的镜头移动

前面都是物体自身的变换操作,那这种“第一视角镜头移动”的视觉效果如何实现呢?可以通过操作物体、或者操作相机来实现,两种方案都有各自的优缺点;
什么情况适合移动相机?
在光影比较丰富的场景中,直接移动相机,可以更真实的模拟视角转换;
物体数量比较多,移动相机更方便;
一个物体的矩阵变换结果,依赖于所有 父级模型的变换,因此当父对象体和子级对象同时进行矩阵变换, 还需要做世界坐标和局部坐标的变换, 这种情况下,移动相机就可以减少操作的复杂度,规避这种情况。
当然啦,移动相机的方式也会出现比较复杂的情况,比如相机的位置发生了变化,此时还需要物体 正对镜头,那么就需要一些方法来确定物体的旋转角度;
可以先利用 lookat() 来确定物体在某个朝向时的 rotation 数值;
利用四元数 (camera.quaternion) 来获得朝向相机的角度;
然后再把获取的 rotation 数值应用到动画里。
具体api使用方法不多赘述,不过要注意导出模型时,物体正面需要设置为Z轴正方向,这样调用 lookat() 才会转动到正确的朝向; 总的来说,采用移动相机的操作起来会更直观一些,整体实践下来还是更推荐这个方案。
———
Part 3. 关于性能优化
3D模型往往存在资源太大、性能损耗严重的问题,这也让许多 3D 创意止步于开发阶段。这部分主要通过在项目中的测试数据从 内存、帧率、加载速度 几个方面来分析性能优化方案。
初看这个问题比较容易没有头绪,在这个相对小众的领域,也缺少相关的研究,以及比较成熟的实践方案、性能规范等等,不过我们还是遵循“测量数据”、“定位瓶颈”、“进行优化”的思路,先对内存管理以及页面加载性能做了初步的探索。
一 内存管理
我我们换用另一个内存优化空间更大的项目来进行测试,QQ阅读端内常驻页面“小Q的家”页面涉及3D模块的加载和卸载,其中的换装功能还涉及到模型的频繁添加与移除,所以这个项目测试数据会更直观。
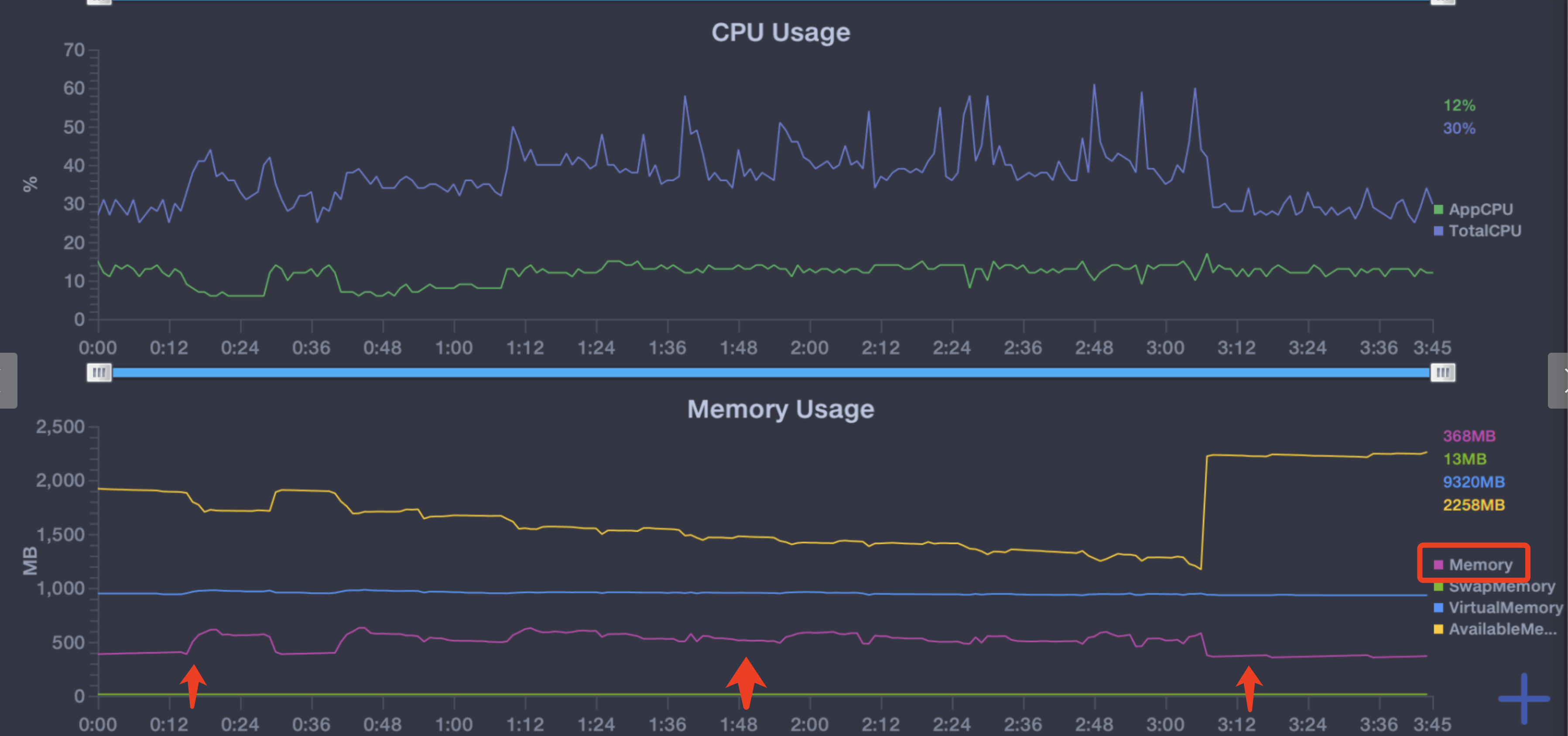
先先看一下优化前的数据情况,从app进入页面,并进行多次切换3D模块的操作,检测数据:
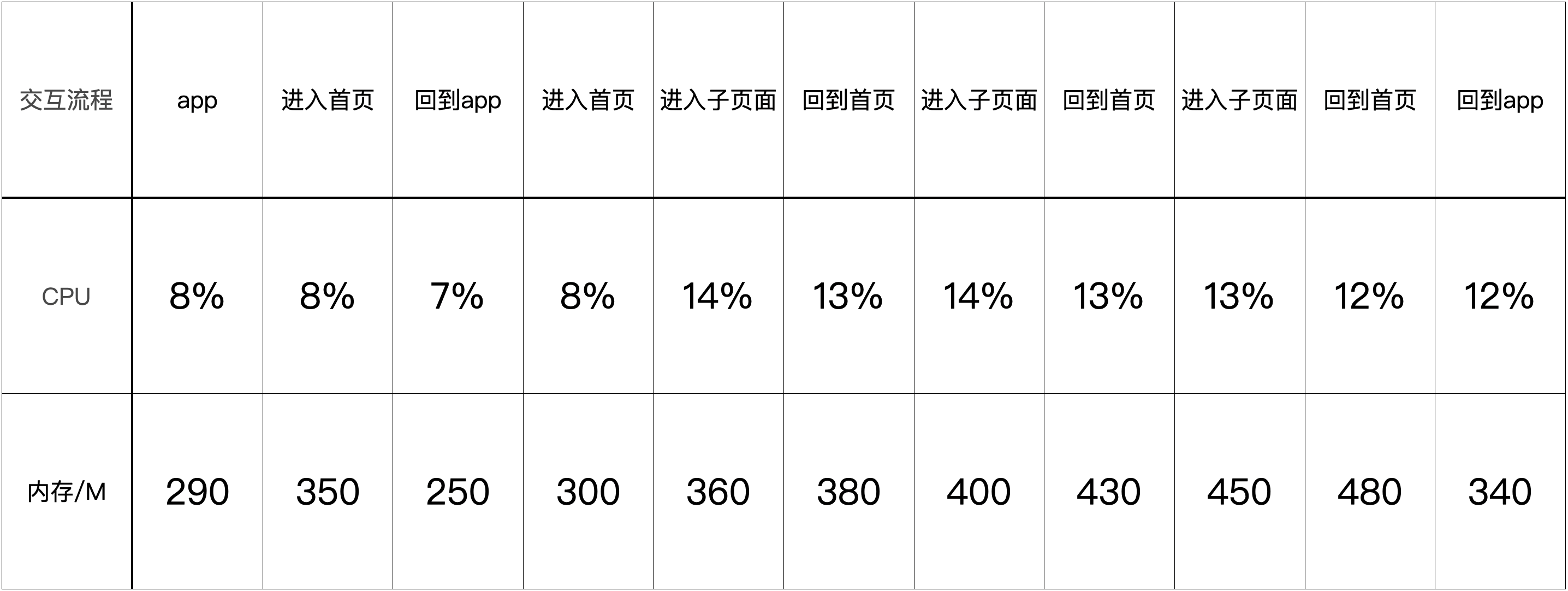
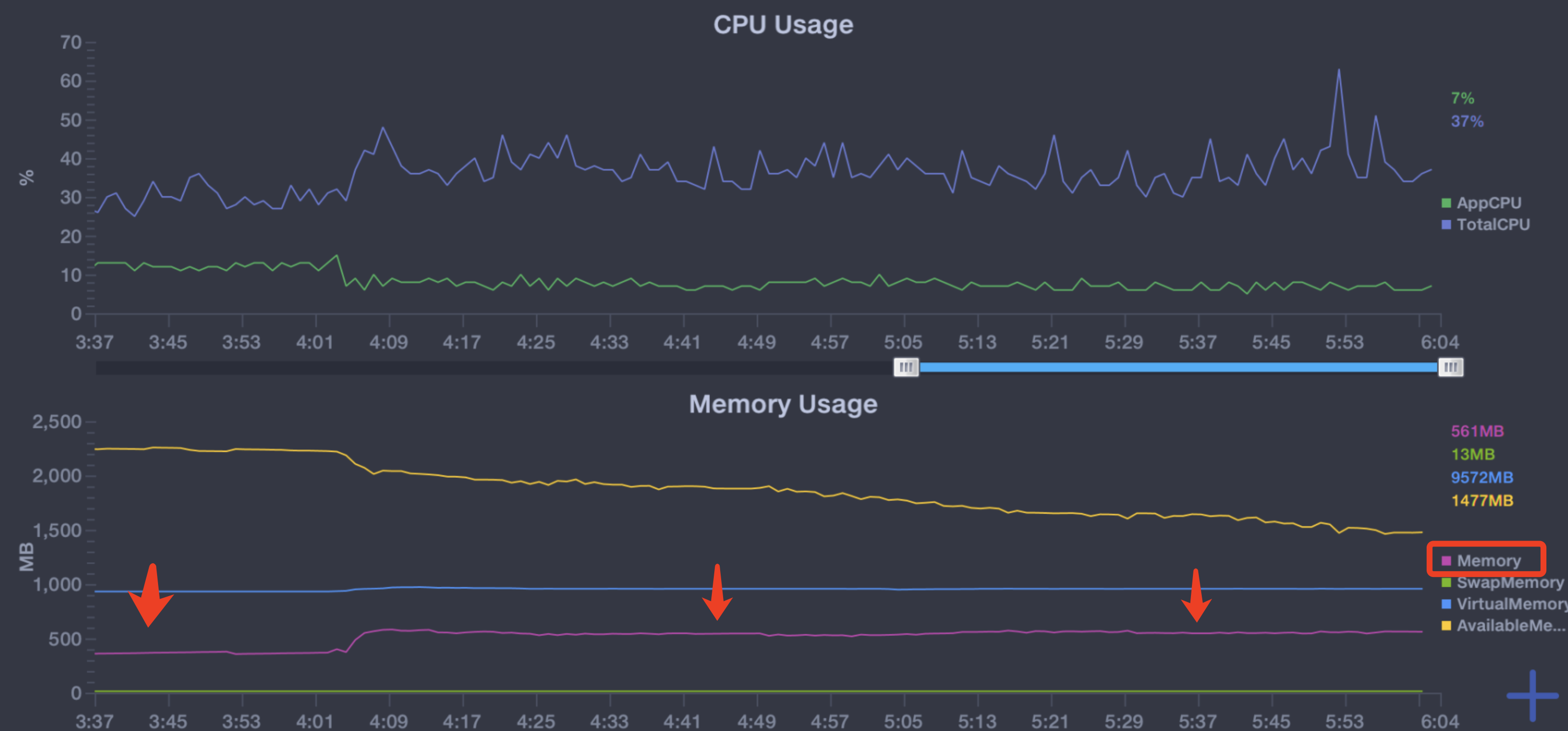
可以看到,随着组件的卸载和重新加载,内存不断上升,cpu的消耗不明显,暂时不做处理;
在小米mix2上,切换七八次后内存就达到了近1000M,有些机型会发生白屏闪退。
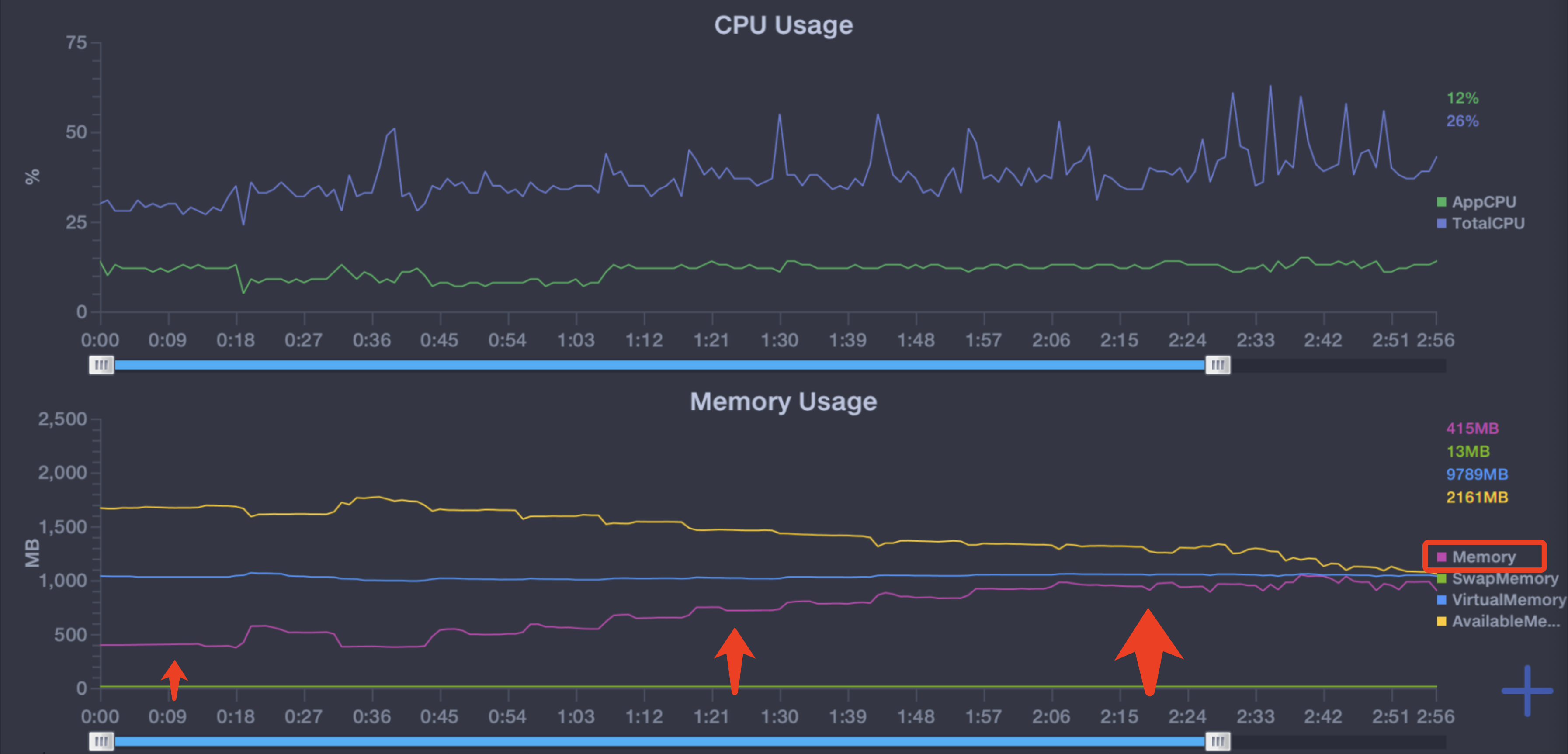
如何优化?
three.js不会自动释放内存,不过提供了相关方法,其实简单说就是 认真看每一个类的api,把能释放的都释放掉,在合适的时机,比如组件卸载、模型切换时,释放不用的资源。
简单示意:
obj.traverse((item) => {
if (item instanceof THREE.Mesh) {
item.geometry.dispose()
item.material.dispose()
}
})
因为纹理可能会被多个材质共用,所以回收 material 时,使用的纹理不会被清除,需要我们单独做处理,比如:
item.material.map.dispose()
item.material.normalMap.dispose()
item.material.roughnessMap.dispose()
当我们使用外部模型时,找到每个对象具体使用的贴图类型比较麻烦,可以用 three.js的编辑器[4] ,很方便的看到用了哪些贴图;
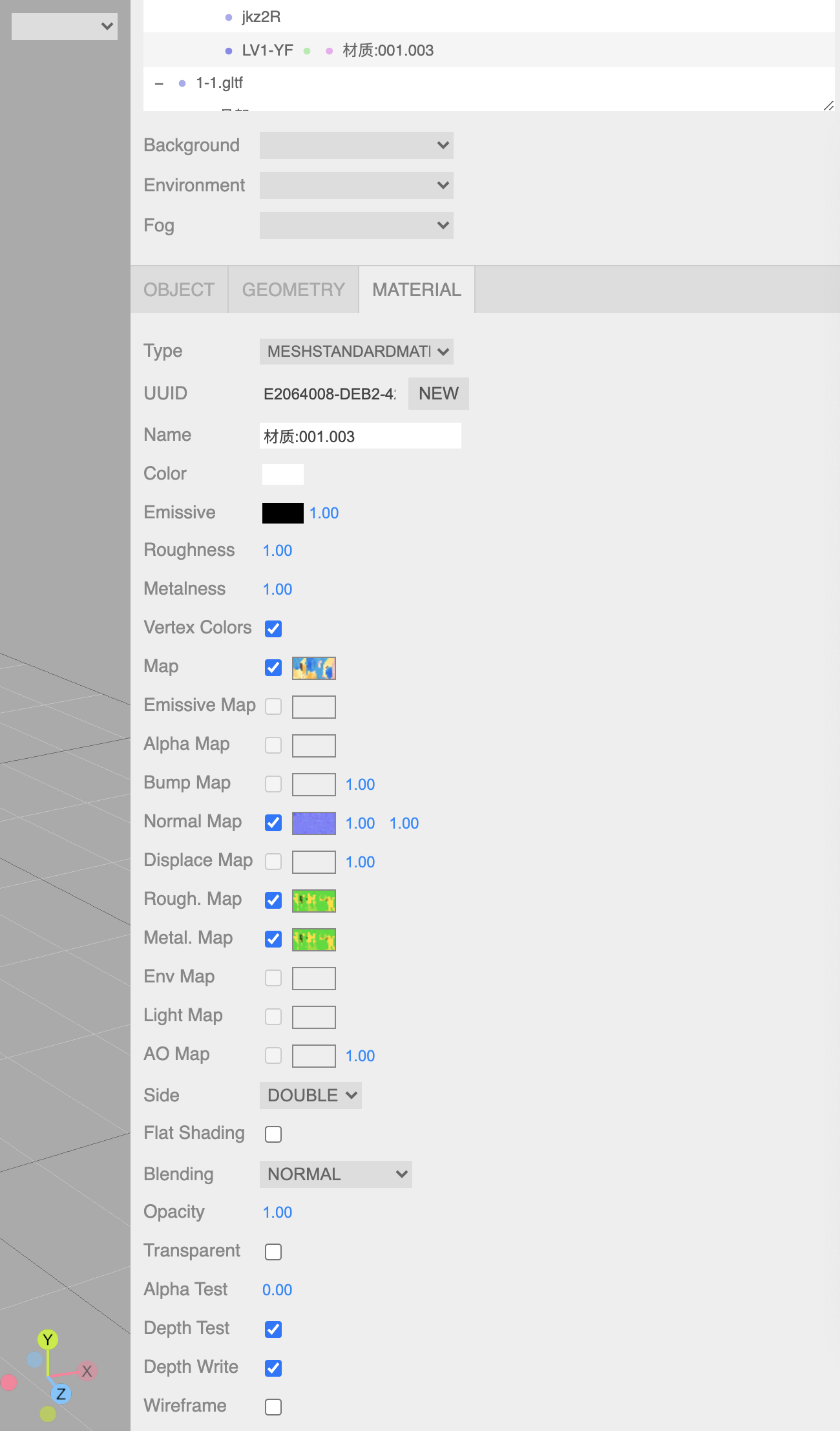
three.js中还有一些其他自带 dispose() 方法的东西,比如控制器、 WebGLRenderer,能清除的可以都清掉,动画混合器(AnimationMixer)包含很多缓存机制,动画不使用的时候把动作、clip等资源都释放掉;
优化后进行相同的操作,可以看到内存维持在相对稳定的水平,退出页面后也基本回到初始状态;
二 首屏时间
在会员装扮项目中,根据实际的测试,像渲染器初始化,灯光、粒子初始化,以及模型的操作等等,这些流程时间几乎都可以忽略不计,也没有太大优化空间;首屏时间主要消耗在两部分:模型加载和解析,以及 首次渲染 ;
01 首次渲染
虽然动画过程中每一帧的渲染时间在10ms以内,但是进入页面的首次渲染花费时间却很大,针对这个过程我们先定位瓶颈,逐一做对比测试,找到明显的几个高消耗操作再逐一优化,核心思路就是在 首屏内做更少的事情;
1. 所有添加的渲染效果,其中有两个能看到明显的耗时:
增加灯光的阴影投射
开始HDR光源的映射
比较意外的是粒子动画的渲染带来的时间消耗不是很明显,增加粒子数量到8000 ~ 9000时才有明显的感知;
去掉这两个之后首屏绘制的效果也可以接受,所以就在首次渲染之后再加。(注意需要放在setTimeout方法内,不然会出现延迟绘制,即调用了render之后并没有马上执行绘制。)
2. 当然, 影响耗时最显著的还是模型中物体面数的数量。模型中箱子内部的物体在首屏中是看不到的,就可以先隐藏掉,可以在首屏中只渲染底部转盘和空箱子,其他物体进行延迟渲染(添加其他物体时,要注意还原物体之间的父子关系),这一过程在chrome测试效果明显,可以节省500ms左右的耗时。
3. EffectComposer的渲染和render的渲染,耗时并没有很大的差别。不过使用单帧渲染两次的方法实现局部辉光效果,多出一次的渲染必然会造成更多的开销,所以在需要辉光效果时再打开。(经测验在chrome可以减掉300ms左右的渲染时常,主要取决于辉光模型的数量)
经过以上的缩减处理,首屏渲染的时间优化对比如下:
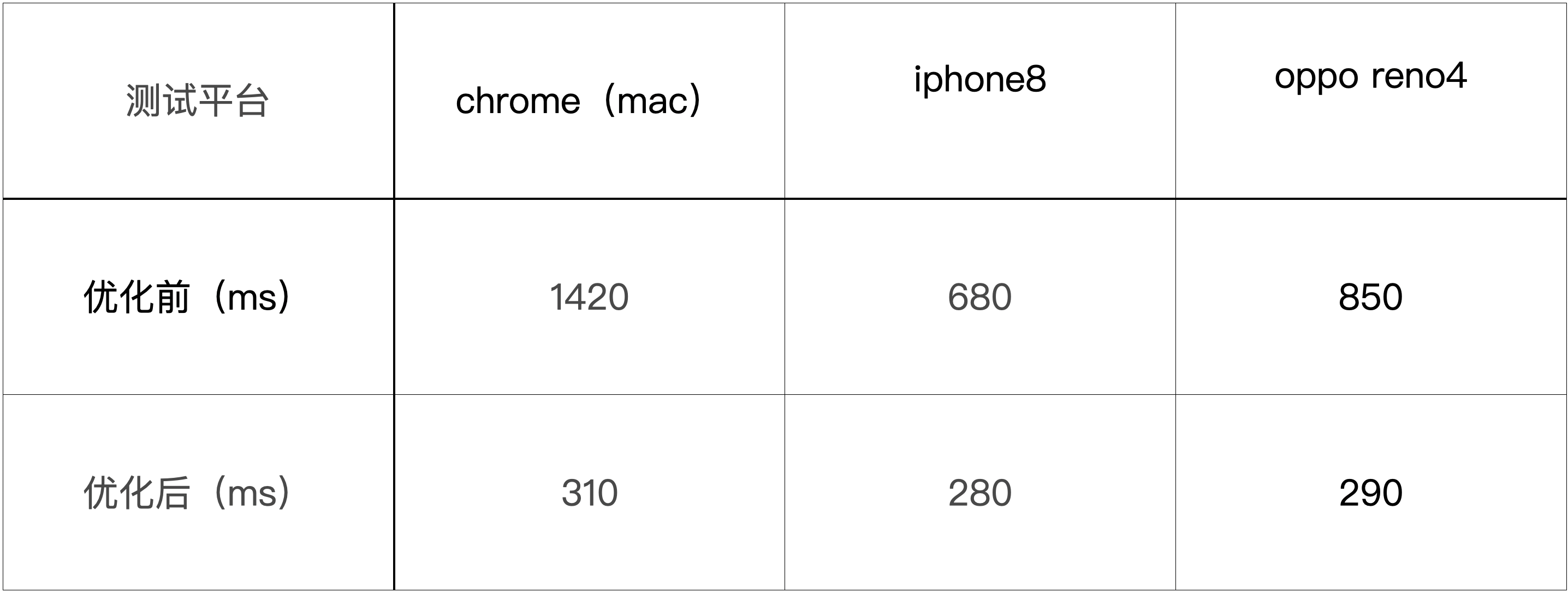 移动端测试时,不同的浏览器或webview也会有影响,数据取平均值
移动端测试时,不同的浏览器或webview也会有影响,数据取平均值
02 模型加载和解析
模型的格式直接选择了传输和渲染都比较优秀的gltf/glb,测量了不同大小的模型在不同平台的 加载+解析 总耗时,先列出测量的数据情况:
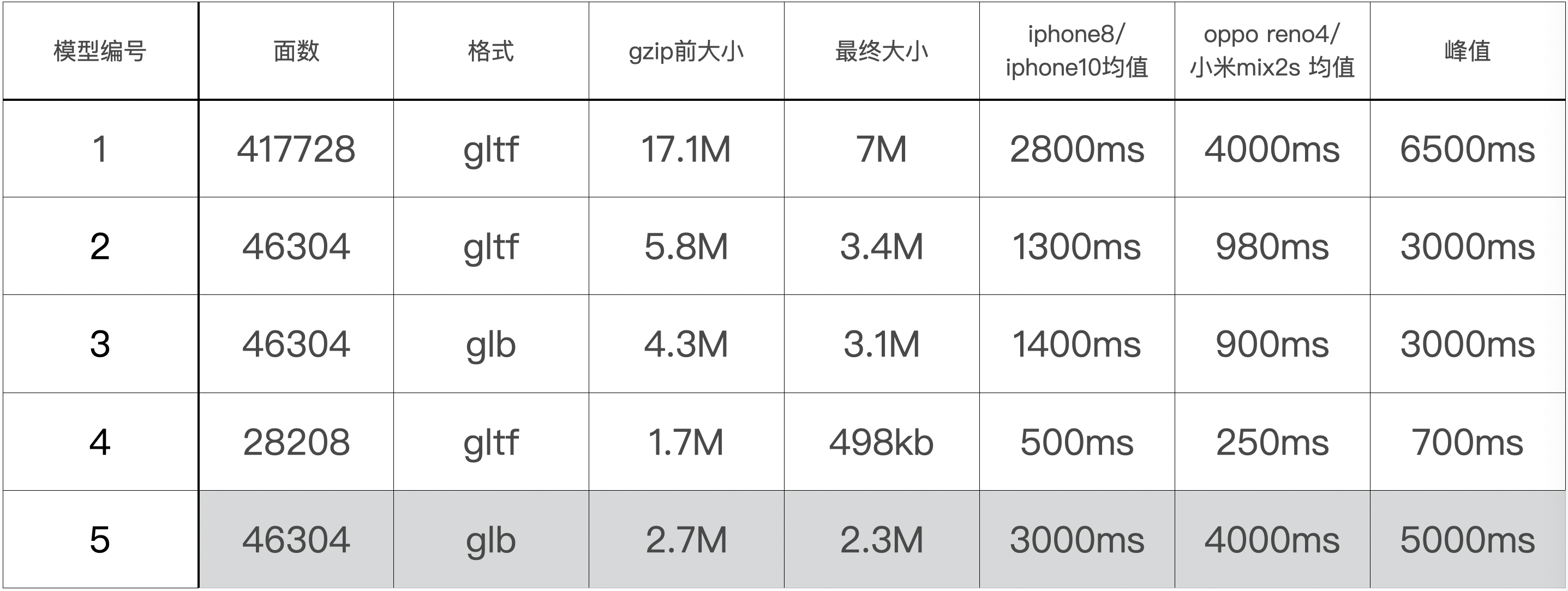
先观察前四个模型数据,整个耗时主要是加载模型所需要的时间,可以看出资源的加载耗时,直接依赖于 模型的文件大小,模型的格式也会影响传输和解析速度,不过目前的测量结果来看影响不显著;
观察2号模型和3号模型,同样的模型,导出glb格式会比gltf小很多,但经过gzip之后两者的差距不大;
而在使用资源缓存之后,整个过程会大大减少;3M大小的模型iphone缓存后所需时间大概为200ms,安卓会久一些在700ms左右。
直接影响模型大小的就是模型的三角面数和贴图,设计师在建模的过程中注意减少不必要的模型细节、模型数量,压缩贴图等等;
大小的把控要根据场景的复杂度,也没有办法一概而论,设计同学需要对不同模型大小的加载耗时有大概的判断,在性能体验和画面精细度之间做平衡。
draco压缩
在面数不变的情况下,我们把3号模型进行了draco压缩,即5号模型;
在默认的压缩力度下,尺寸由4.3M压缩到2.7M(其中模型大小占443kb,其余贴图的大小有2M多),gzip之后为2.3M,相比于原本的3.1M小了很多;
但是draco压缩带来的解析代价也很明显,直接增加了2s~3s的总时长,不同机型的测量结果差距也比较大,低端安卓机体验很差,目前的模型大小并不适合draco压缩。
03 总结
首次进入页面时加载耗时往往会非常高,并且资源加载太依赖于网络环境,测试数据中的峰值是在网络相对稳定下测量,项目的实际环境可能会更无法估量,所以还是要用loading进度条做兜底;
当资源大小和解析时间出现冲突,还是选择减少解析的时间,用缓存来解决资源的问题;
同时减少首次渲染的时间,根据目前测试:缓存后,页面的首屏可以稳定在500ms(iphone)和1000ms左右(安卓)。
———
Part 4. 最后
Web3D技术相较于其发展成熟的前端技术还算是比较小众的领域,上手门槛高,开发比较复杂,生态也不够完善;
不过近年来随着移动设备的快速发展和产品设计的多样化,越来越多的3D互动项目以及平台解决方案出现在人们的视野里,在3D技术领域,我们还有很多的空间可以探索,同时开拓业务场景,让技术能力与产品需求相辅相成,降低开发成本,解决上手难、开发周期长的问题,发展工具化、平台化等等,为Web端的表现力和互动性提供更多可能性。
参考链接
[1] https://threejs.org/examples/?q=post#webgl_postprocessing_unreal_bloom_selective
[2] https://github.com/mrdoob/three.js/blob/master/src/core/Raycaster.js
[3] https://github.com/mrdoob/three.js/issues/6548
[4] https://threejs.org/editor/
请用手机微信扫描下方二维码,体验线上项目。
![]()