广告
了解详情
【夯】GPT-image2模型全攻略(电商设计师实用版)




成都/平面设计师/18小时前/464浏览
版权
【夯】GPT-image2模型全攻略(电商设计师实用版)
内部学习笔记,冒死偷偷转为文本分享给大家~
一、基础信息
1、简介:GPT-image2模型实则为【image系列模型】的迭代升级版本:
● 一阶段:
DALL·E 2、DALL·E 3
早期小弟!干不过开源的XL/Flux等模型;
● 二阶段:
GPT-4o
封神之作!多模态用嘴做设计的转折点,具备原生多模态能力,能结合上下文+图片+世界知识+逻辑理解进行图像编辑,之前我们也着重讲过。
● 三阶段:
GPT-image 1.5
时运不济!其实也不弱但奈何谷歌的香蕉太猛,能画/会改/能理解,但综合表现一般;image1的增强版,但称不上强多少,所以只配叫1.5。
● 四阶段:
GPT-image 2
逆天改命!找到差异化进一步快速迭代,三十年河东,三十年河西,且看下文娓娓道来。
2、使用途径:
● 官网:https://chatgpt.com,需魔法+注册GPT账号。
● 第三方渠道:如 LibTV、Lovart、tapnow、flowith等一切均接入了api接口。
3、渠道价格:
官网:月费&滚动使用机制
● Go会员49元,按每天用满约等于30张/天*30天=900张,每张0.054元(1~2k);
● Plus会员136元,按每天用满约等于45张/3h*3次*30天=4050张,每张0.033元(1~2k);

第三方平台(注:价格存在变动,以下仅做参考,数据采集时间:2026年5月10日)
● LibTV:https://www.liblib.tv/
(1)429元/月-会员:1积分=0.037元(本次计算对象);
(2)最顶级会员:1积分=0.014元(每积分优惠62.1%);
(3)image2 积分花费测算:

● lovart:https://www.lovart.ai/
(1)218元/月-会员:1积分=0.062元(本次计算对象);
(2)最顶级会员:1积分=0.027元(每积分优惠56.4%);
(3)优势:部分会员提供0积分出图活动;
(4)image2 积分花费:

● Tapnow:https://www.tapnow.ai/referral/iAap5oUx
(1)143元/月-会员:1积分=0.04元(本次计算对象);
(2)最顶级会员:1积分=0.03元(每积分优惠25%);
(3)image2 积分花费:

(4)注意,当前积分按写帖时正在举行的限时5.5折活动进行计算:

● 其他,基本差球不多~ 每个平台除积分外的玩法规则均有不同,以自己实际需求为准,以上积分仅供参考。
4、充值
● 第三方AI平台:直接在平台上购买,基本均支持微信&支付宝。
● GPT官方:
A、官网信用卡购买:
(1)20美金/月的plus版本即可;
(2)需要能支持VISA等的国际信用卡。考虑到后续使用,可以尝试办理信用卡,开卡很简单,银行送礼求着你开。但有了卡未必能使用(有的时候能,有的时候又不能),不能的时候可以先打电话联系银行查询,如果银行说卡没问题,那就是平台的问题了,这没办法。
B、官网支付宝购买:
(1)核心思路:通过支付宝里的第三方应用商店购买礼品卡,然后兑换到你的苹果美区账号中,再回到GPT的APP里使用账号余额进行订阅(详情步骤请私聊领取完整版手册获得)
(3)安卓系统可以用Google Play钱包(前提是需要开通谷歌钱包,但这又绕回到国际信用卡上了)
● 卖会员的二道贩子:比如***,因此话题较为敏感,在此忽略,如有需求请领取手册查阅。
二、GPT-image2 技术浅析
1、传统:扩散模型(Diffusion Models)

●
代表模型:
Stable Diffusion、Midjourney。
●
工作原理:
扩散模型本质上是一个“去噪”过程。它从一幅完全随机的高斯噪声图开始,根据文本提示词的引导,逐步预测并减去噪声,最终显现出清晰的图像。这个过程是并行处理整个图像像素(或潜在空间特征)的。
●
优势:
擅长生成纹理细腻、光影自然、结构复杂的艺术图像;计算效率在推理阶段通常可以通过蒸馏技术(如 LCM)优化得非常快。
氛围、质感、随机美学。
● 劣势:
缺乏全局的“序列感”和“逻辑规划”。因为模型是同时优化所有像素,它很难理解“左边是A,右边是B”这种严格的位置关系,也很难处理需要严格笔画顺序的文本渲染(经常出现乱码或拼写错误);文字乱码、位置绑定错乱、排版崩塌、参考图保真不足。
2、GPT:GPT-image2 原生多模态架构

●
代表模型:
GPT-image1、GPT-image1.5。
●
工作原理:
原生多模态输入理解→语义/构图/风格计划→图像token/latent表达生成→解码为最终图像;不是随机生成一团噪声再去噪出图,而是在统一多模态大模型里,把图像当成一种可以被“组织/推理/生成”的视觉语言(先理解关系,再生成画面)。
● 优势:
更多文本训练,更强语义绑定,指令依从度大幅提升。
● 劣势:
偶尔幻觉、物理逻辑遵从度偏弱(依赖不降质的规划能力)。
3、谷歌nano:自回归模型(Autoregressive Models)

●
代表模型:
Google Parti、Nano Banana Pro (Gemini 3 Pro Image)、Sony/Google Fluid。
●
工作原理:
将图像视为一种语言。它将图像切割成一系列离散的小块(Patches),并将其转化为序列化的标记(Tokens)。生成图像的过程就像写句子一样,从左上角到右下角,一个标记接一个标记地预测出来。
●
优势:
Gemini 3 pro理解任务→推理/规划/调用世界知识/搜索→组织图像内容→图像生成与编辑;DiT扩散变换器+物理推理引擎+搜索增强生图+多参考图融合;能理解是在画什么东西?长什么样?逻辑是否正确等等。
●
劣势:
推理速度较慢(因为必须串行生成),且对长序列的显存占用极高。
4、技巧板块小总结
●
图像模型发展至今已经都很强了;
● image2和nano技术略有不同但解决问题思路相近,因此生图效果也较为接近。
三、模特特征
1、优势提炼
●
官方原话:
高保真写实、自然光影、准确材质、身份保持复杂结构化视觉、风格迁移、现实知识/推理···
●
个人总结:
(1)美学在线
(大多数时候,默认美学水平更高)



(2)真实感提升(降AI味)


附-AI检测助手:https://matrix.tencent.com/ai-detect/

(3)语义绑定,指令遵循度更高


(4)可靠信息字符/UI渲染
① 原理:
文字本质上是离散符号,扩散模型是把文字当成图案纹理,因此容易乱码,而GPT路线本就是语言模型,天然对字符/词/句子/版式关系更敏感。
② 擅长:
标题、包装标签、信息图、短句、slogan、UI截图、漫画对白、说明注释。
③ 问题:
但对于小字,极细字体,中文复杂排版,仍存在一定问题。


(5)添加源功能(官方平台)
① 可通过添加各种新应用产生跨软件联动,如做简单的抠图和导出PSD文件等(注意这里的所谓导出PSD分层源文件效果简直"拉"爆了,别被营销号给忽悠了)

(6)自带简单编辑功能
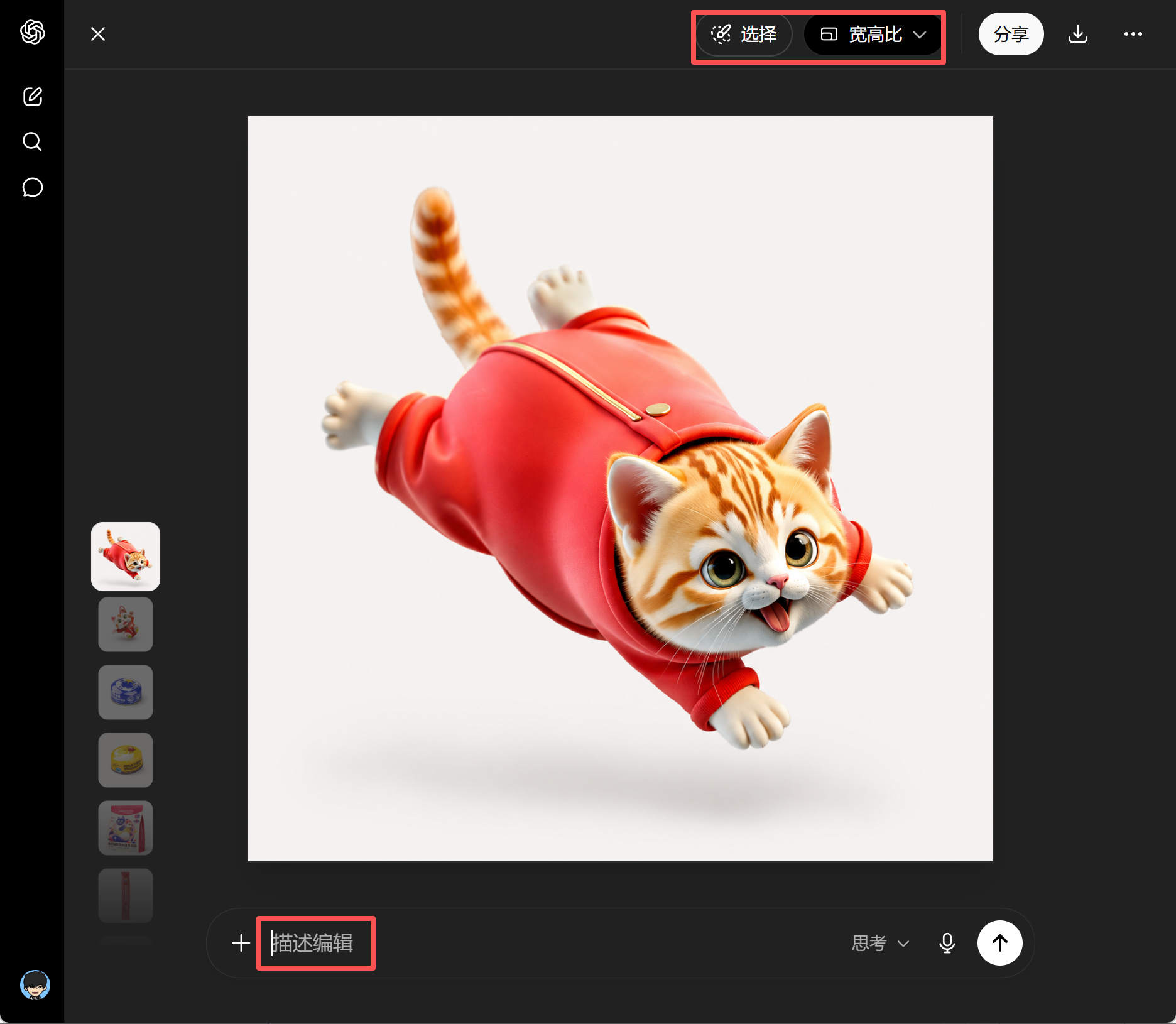
2、赏图(想必大家已经看腻了,我就直接放大招了)
推荐AI资产平台:站酷
https://www.zcool.com.cn/ai/generate-database推荐AI图片平台:OpenNano
https://opennana.com/?ref=N6Z53HMR
3、仍旧存在的问题
●
贵、生图速度偏慢
(且第三方ai平台速度比GPT官网更慢)
下图为LibTV上image2模型相较nano模型的积分消耗比较(注:以下仅供参考,积分消耗可能发生变化)

●
物理逻辑规律弱
① 举例:物理细节表现(左image2;右nano pro)

↑提示词:
顶级商业摄影:一只哑光黑色钛金属质感的智能手表,静止在如镜面般光滑的黑色大理石桌面上。
反射效果: 桌面必须呈现出手表清晰、深邃的高亮倒影(Top black smooth surface reflections)。
光影: 侧方单一硬光源,在手表边缘勾勒出极细的轮廓光,展现出金属表壳的拉丝纹理。
细节: 表盘的蓝宝石玻璃盖板上要有极其轻微的指纹油膜感(仅在特定角度可见),并折射出周围环境的微弱冷色调。
画质: 电影级光效,原生 4K 质感,极其真实。
② 举例:反逻辑遵从度(左image2;右nano pro)

↑提示词:
一个超现实主义的室内空间,其核心逻辑由以下指令严格构成:
反重力结构: 房间的天花板是由一个发光的、流动的蓝色海洋构成,海洋里倒悬着一艘老式帆船。
地板物理: 地板并非固体,而是由密密麻麻、垂直竖立的古老书籍组成的“森林”,书页在无风自动。
空间融合: 房间的四面墙壁不是实体,而是由巨大的、嵌套的**克莱因瓶(Klein bottle)**结构组成,瓶中循环流动着霓虹色的液体,并投射出复杂的数学公式刻度。
核心焦点: 房间中央悬浮着一个由透明水银和活体青苔混合而成的、不断变换形状的几何正十二面体。
光影逻辑: 光源并非来自灯或窗户,而是直接来自天花板倒悬海洋中的那艘帆船的桅杆,光线呈冷蓝色,穿过书籍森林,在地板上投射出清晰的书页文字阴影。
画质: 电影级微距,超高对比度,没有任何乱码或逻辑妥协。
③ 举例:逻辑文字渲染
(左image2;右nano pro)

↑提示词:
一个极度精确的、由拉丝不锈钢构成的潘洛斯阶梯(Penrose stairs)。
核心结构: 这是一个几何学上的不可能图形,阶梯在一个四方形回路中不断上升,最终回到原点。
细节约束: 每一个台阶的侧面都必须刻有一个连续的递增数字(1, 2, 3...),数字必须沿着阶梯的上升路径排列,不能中断,且数字的透视角度必须随台阶面完全一致。
光影干扰: 阶梯中心悬浮着一个强光源,光线在每一个不锈钢台阶上产生复杂的、交叉的金属拉丝反射。
视觉陷阱: 阶梯的阴影投射在下方一个无限延伸的切比雪夫平面的棋盘格上,棋盘格的线条在经过阶梯阴影时必须保持完美的直线透视,不许有扭曲。
● 细节过剩 (极度复杂的画面细节+不符合逻辑的细节渲染。产生原因:物理逻辑规律弱。(仔细观察大图可发现))

● 管控加码(儿童/性感/伦理/肖像/版权··· 总的来说监管将会越来越严格。如果不清楚是什么原因被拒,可以主动询问。)

3、图像尺寸
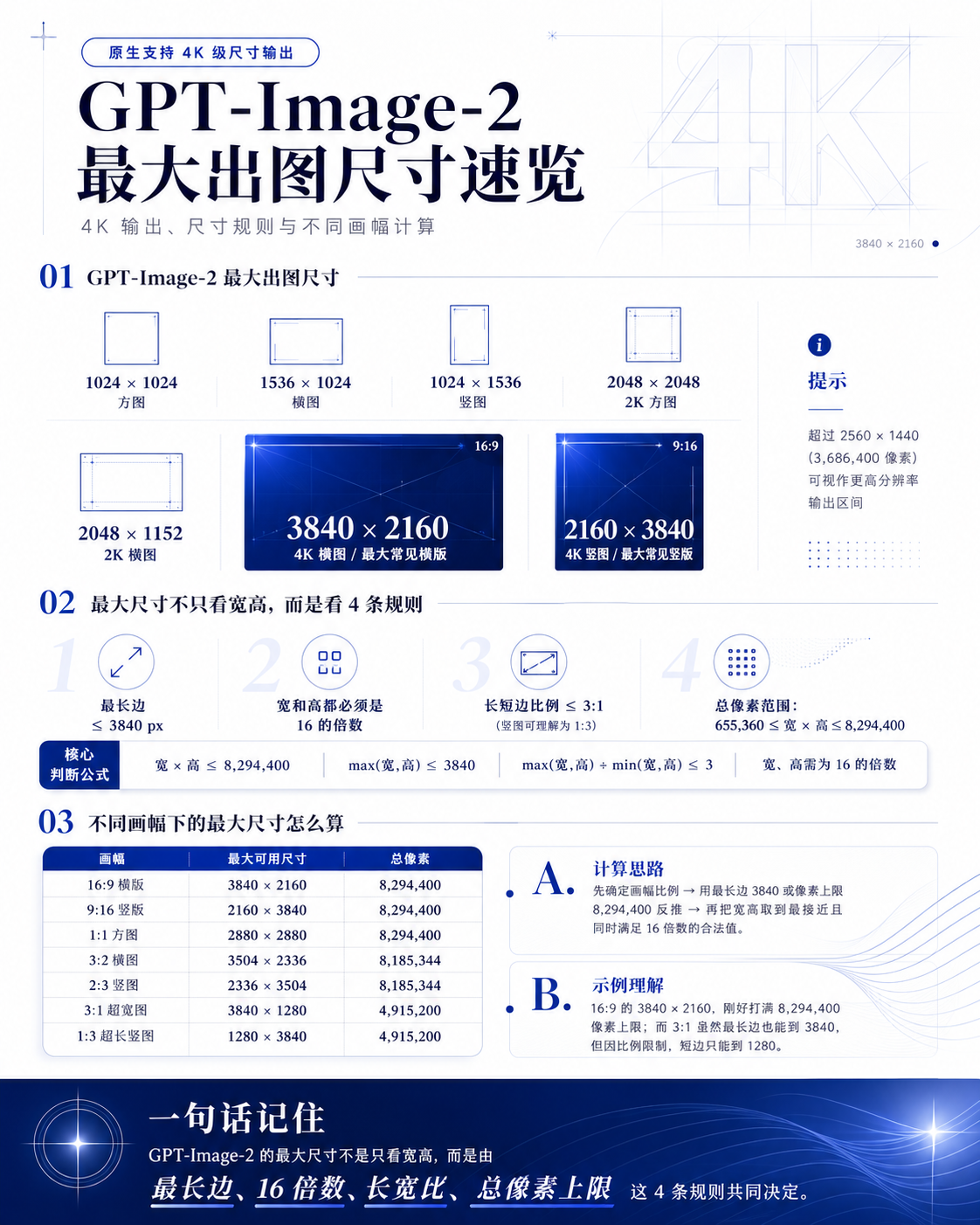
●
官方对话窗口:
无法通过自然语言提示词控制具体尺寸,大多时候生成的就是1~2k的尺寸。
●
API接口/第三方平台:
因此可生成4k画质(前提是API前端有做适配)
●
图像参考:
① GPT官网支持最多12张参考图。

② 第三方接口支持最多16张参考图(需AI平台有类似功能)。

③ 注意参考图多了容易分散权重,并非越多越好。
④ nano 模型第三方最多支持20张参考图。
四、使用指南
1、趋势
香蕉那一套,依旧适用,这也是模型未来的趋势,即氛围出图,用嘴做设计~
2、什么时候用GPT-image2
●
图&文多模态生图时
可视化图/多文字/UI界面/包装/版式/作品集/详情页···

● 对美学要求高/文生图的时候
提示词描述的再复杂它都能在保持美感的总前提下出图


● 跑人物模特的时候
美学基准线高/AI味弱/细节差异性丰富


●
对物理逻辑规律/真实性数据要求不高的时候

● 需要对图像进行精修的时候

这篇教程帖子可以看一下(工具不同,但技法思路通用)https://mp.weixin.qq.com/s/tPdVAH9_GtZHdiBnfTMOoQ
● 整体难度不大,但又不知道怎么描述画面想偷懒的时候


●
对特定人像样貌迁移要求高的时候
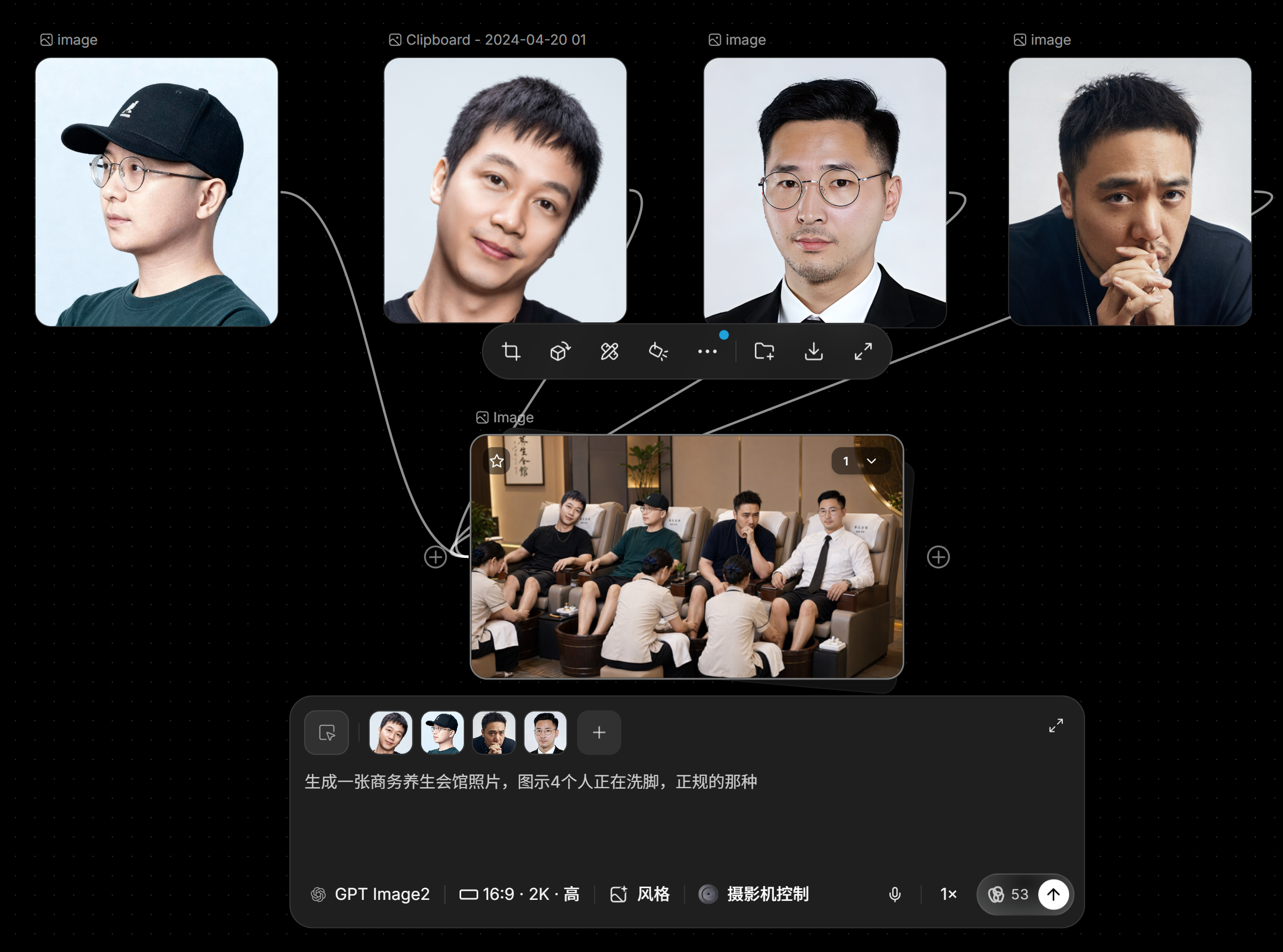


3、什么时候不用?
● 画面整体过于复杂/或容易复杂的时候
会失真/会画蛇添足(用提示词反向约束可一定程度改善)


● 对真实物理规律/材质表现/结构还原要求高的时候
会变扭/无法理解真实逻辑
提示词:生成这个结构的3D空间多视角图片,上中下,左中右,45°角上中下,一共27个视角图,把这27个视角拼合到同一张图片发我。
此类特殊结构在多视角功能(各平台自带/千问开源模型),AI- 3D模型均难以准确还原结构。

4、模型使用整体逻辑
①
在综合无特殊要求的情况下,优先按下面顺序使用模型:nano 2 > nano pro > image2。
② 理由:
nano 2 便宜+出图快+基本都能解决。在nano 2无法解决的时候再试试nano pro(并开启联网功能)。

5、综合提效技巧
● 根据需求选择工具
① 单一任务:
直接选择图片生成器生图+搭配小工具。
② 复杂任务:
使用自带通多模态模型的Agent出图,比如详情页,需要分屏确认信息的时候;如果没有则可以用第三方模型出方案+生图器生成(但更麻烦且易丢失一致性)。
● 官网多窗口并行

① 官网实行:动态并发作业。
② 并发情况:
a、免费用户:基本单任务工作;
b、plus用户:约3个并发(取决于任务难度);
c、pro会员:约5个并发(取决于任务难度)。
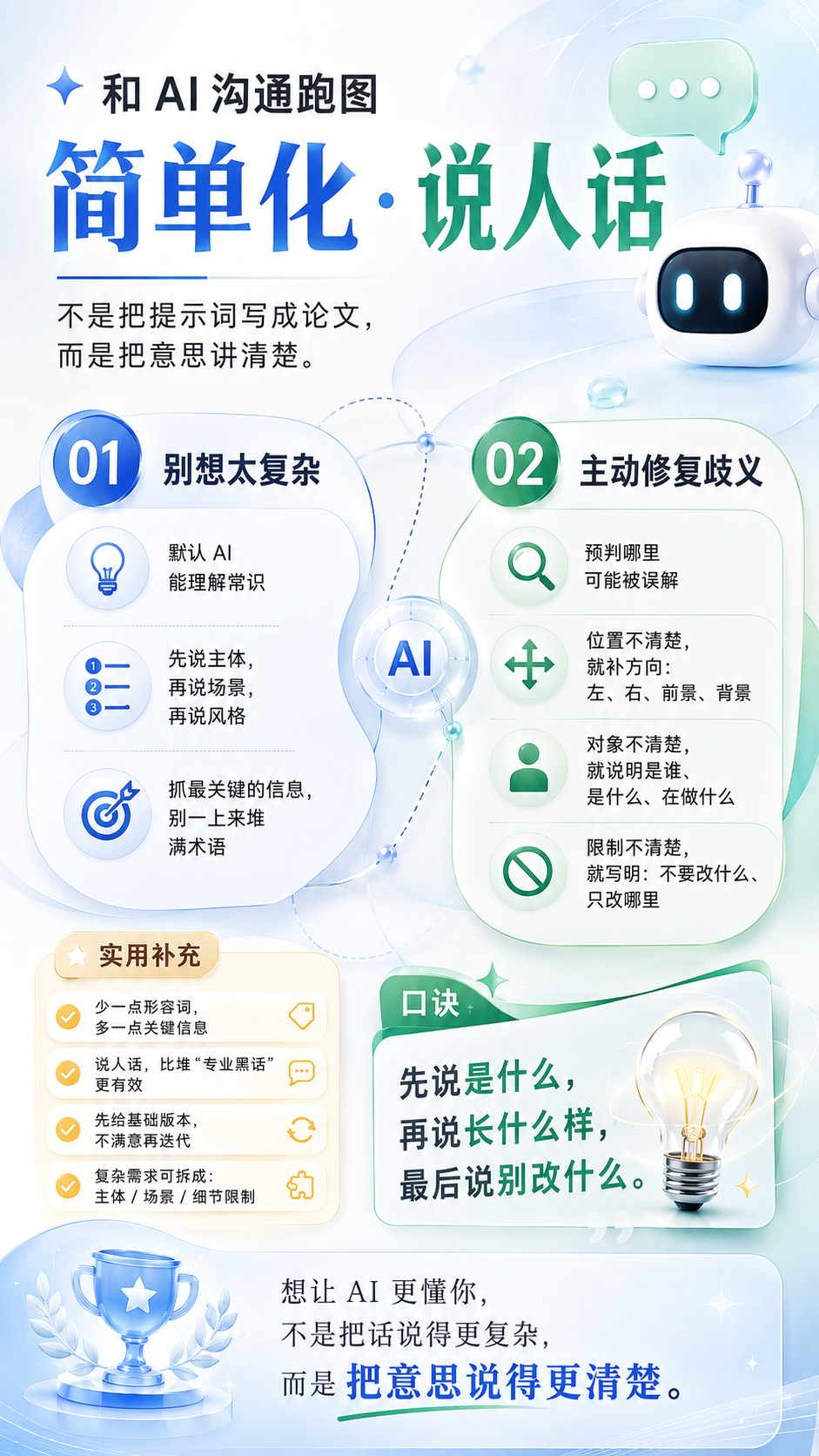
● 简单化/说人话
① 不要想太复杂,以默认ai都能理解的方法去生成。
② 预判可能存在的歧义并主动修复。
学员案例:请私信获取手册查看。
● 官网等待超时问题
如果在GPT官网使用的时候遇到一张图【卡在一直出图中】,此刻请手段刷新页面,大概率图片一下或者很快就出来了(前提是先排除梯子稳定性问题)。
非常感谢大家的观看~🥰
希望这篇总结能对您有所帮助!ღ( ´・ᴗ・` )比心💖
13
11
分享
相关推荐

















评论你的想法~
表情
喜欢TA的作品吗?喜欢就快来夸夸TA吧!
推荐素材
























你可能喜欢












相关收藏夹























登录注册
13登录即可同步推荐记录哦
11登录即可加入我的收藏
评论登录即可评论想法
分享分享