数字化时代,用户研究正迎来前所未有的机遇与挑战。每天涌进来的海量用户反馈、访谈记录和评论,是蕴藏需求的“宝藏信息库”,可传统分析方法很难扛住这份“信息量”。今天就聊聊AI大语言模型在用户研究里的实际用法,重点说短文本反馈分类、长文本分析洞察这两个核心场景,帮用户研究人员省出更多时间做关键决策。
给用户的主观反馈分类,是用户研究里最基础却也最磨人的内容。现在常用的两种办法都有明显短板:①纯人工分析就是“人海战术”,不仅慢,几个人判同一个反馈可能结论不一样,还容易标错,要是分类标准变更,之前的工作全白费;②技术辅助也不省心,关键词匹配只能抓表面字眼,比如用户说“登录总卡壳”,没提到“卡顿”俩字就识别不出来,还得专人维护关键词库;机器学习更不用说,得先人工标上万条数据当“教材”,还得有算法团队卷入,普通团队根本玩不转。
针对短文本分类,现在有两种主流AI解法,各有各的适用场景。
这种方式特别适合那些偶发的、数据量不算特别大的“临时任务”,或者是项目初期还在探索确立分类标准的阶段。它的操作逻辑非常直观:你可以先将一部分用户反馈连同项目背景一起扔给 AI,让它基于语意分析自动总结出合适的分类标签;待分类标准定好后,再命令它依照这些标签批量给反馈进行打标。这就好比你请了一位理解力极强的“临时工”,不仅能帮你制定分类规则,还能迅速执行繁琐的分拣任务。
这种做法的优势在于具备良好的
灵活性和便捷性
,你无需提前准备复杂的训练数据,甚至当发现标签不合适时,只需一句话指令即可随时增减调整,完全不需要重新训练模型。而且它的
使用门槛低
,利用市面上常见的对话式 AI 工具(如豆包、Deepseek、Kimi等)即可上手;若数据量庞大,只需对接一个 API 接口便能实现飞一般的处理效率。当然,这位“临时工”也有局限,当面对复杂度较高或涉及深奥行业术语的分类任务时,它可能会因为缺乏专业背景而出现判断偏差。
想要这位“临时工”干活漂亮,你给它的指令(提示词)很关键!
明确角色
:告诉它“你现在是一名资深用户研究员”,让它进入状态。
说清任务
:告诉它“只需专注做分类,别干别的”,避免它跑题。
讲透规则
:把每个分类标签代表什么、排除标准是什么,给它解释清楚。
引导思考
:让它在输出结果前,先想一想为什么这么分(思维链),这样结果更靠谱。
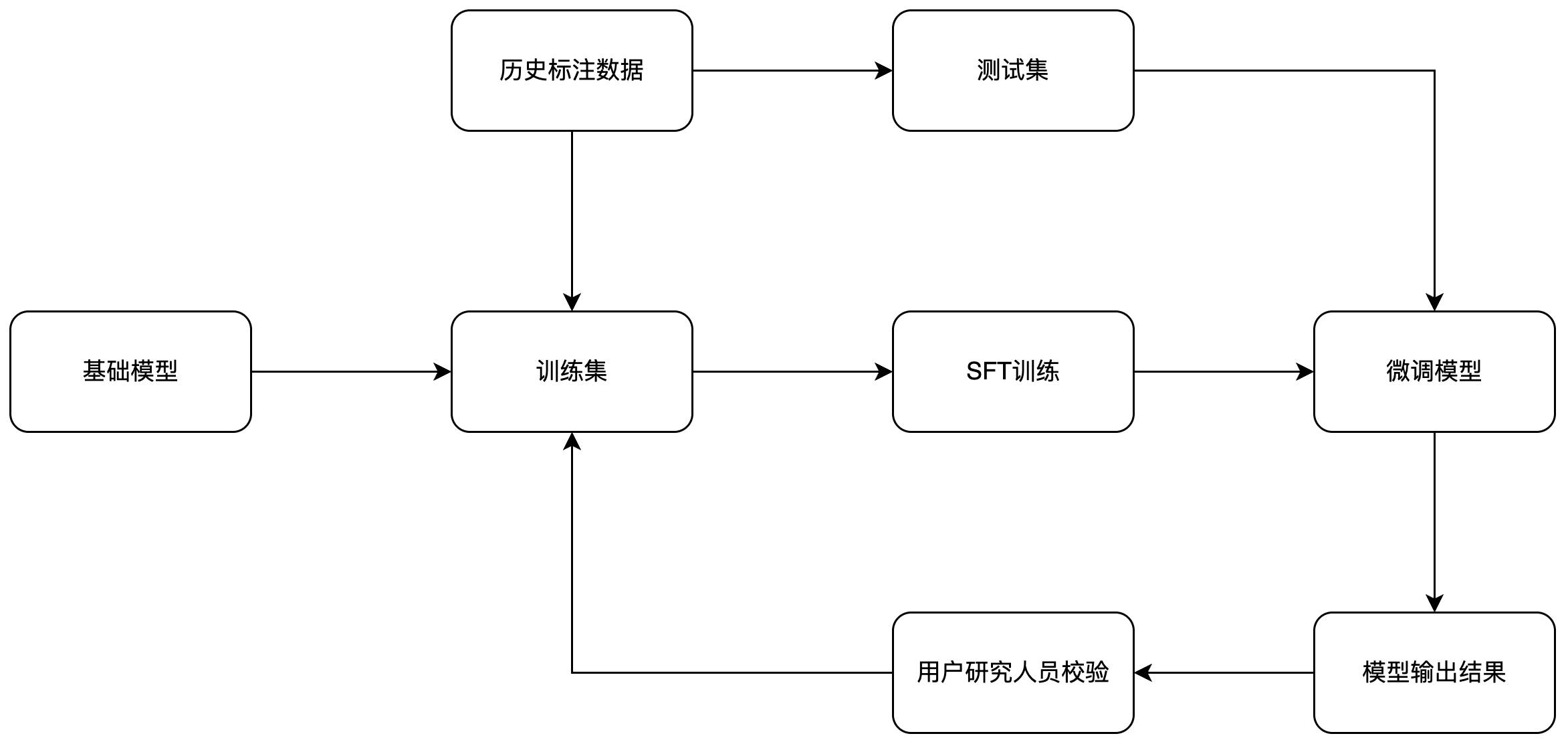
打个比方:通用大模型就像一个博览群书、啥都懂点的 “实习生” ;而SFT(监督微调)就像给这个实习生报了个“行业特训班”,专门教它某个领域的规矩、行话和判断标准,把它培养成“只在这行精通”的专家。
这个过程与医生的培养路径如出一辙:将通用大模型这位“医学生”,送入“用户反馈科”进行 SFT 微调进修,并利用大量经过人工精准标注的“经典病例”数据对其进行高强度训练。最终,它将蜕变为一位不仅通晓常识,更深刻理解你家产品特性、听得懂用户“黑话”的专家级医生。
这种方案最适合那些拥有大量历史数据、业务形态稳定且需要长期持续监测,同时对分类准确率有着极高要求的场景。虽然前期需要投入大量精力准备高质量的标注数据,并需要一定的技术力量支持其训练(即“闭关修炼”),但一旦这位“专家”出师,它将展现出出众的
准确度与效率
。不过需注意的是,这位“专家”比较“死板”,一旦分类标准发生根本性变化,它就必须重新“回炉重造”才能适应新规则。
想要“专家”水平高,“教材”(标注数据)质量最关键:
类别均衡
:别光给看某一类的例子,其他类的也要雨露均沾。
用户访谈、焦点小组等这些长文本“宝藏信息库”往往让人望而却步,因为传统分析方法存在三大痛点:①需人工逐句筛选关键信息导致人力与时间双透支;②用户非直白表述的痛点易被当作无关内容忽略而造成洞察遗漏;③初级用户研究人员因缺乏经验,既难以快速识别信息背后的用户需求逻辑,也会因主观判断偏差出现洞察误判。而AI在这类场景中恰好能发挥巨大作用,无论是单个人的深度访谈记录、还是用户撰写的长篇产品体验日志,它都能高效胜任,这一过程的核心依托是
RAG技术(检索增强生成)
,通俗来讲就是配备了一位“超级管家”。
具体运作时,首先将所有的访谈记录和资料整理切分,构建成 AI 能够理解的知识库(备齐食材);接着搭建好智能体并下达指令(写提示词);最后,当你提出诸如“用户最不满意什么功能”的问题时,这位管家会立即深入知识库,精准检索出所有相关的原始语料,并据此整理分析,最终为你呈上一份客观全面、有理有据的洞察报告(点菜上桌)。
RAG 技术的强大之处在于它极大地提升了
信息处理的效率与完整性
,它能在几分钟内提炼出原本需要数小时才能整理完的信息;同时,它纯粹基于数据说话,还能通过关联分析发现那些容易被人忽略的深层洞察。
想让“管家”干得好,关键在于你食材怎么切、它怎么找:
合理拆分文本
:要把长文本切成大小合适的段落,保证语意完整。
优化检索方式
:用关键词加语义理解双重搜索,确保找回来的都是相关的。
控制上下文
:给 AI 的参考资料别太多也别太少,刚好够用就行。
明确工作规则
:通过指令告诉 AI,“只能根据访谈资料回答,别无中生有”。
用AI做用户研究,效率上去了,但有两个风险一定要警惕:一是用户隐私要守好,反馈要脱敏处理,设置好访问权限,有条件的话可以本地部署;二是要防AI“瞎编”(也就是“模型幻觉”),关键结论一定要人工再核对一遍——这也说明,用户研究人员的专业判断永远少不了。
AI确实在改变用户研究的工作方式,但它不会取代研究人员,而是会成为超给力的辅助工具:帮你搞定重复繁琐的环节,让你有更多精力去提炼洞察、制定策略。未来AI在这个领域的应用会越来越深入,用户研究从业者既要愿意尝试新技术,也要守住专业底线,这样才能保证研究质量,让AI真正发挥价值。