2025生成式AI平台交互体验观察(大语言模型篇)

深圳/UX设计师/1年前/8316浏览
版权
2025生成式AI平台交互体验观察(大语言模型篇)
The world is changing,it's time we change too
2024年是AI应用元年,从2023年ChatGpt爆火到国内百模大战,到现在AI技术应用在C端、B端百花齐放,新一代互联网商业模式MaaS(Model as a Service模型即服务)应运而生。
尽管AI应用很新潮,过去我们积累的用户体验设计经验也未必不管用。过去一年,我们看到了很多基于大语言模型的产品百花齐放,我想聊聊我的观察。
AI产品很多,功能很复杂,我们需要找到一个切入点,我想从黑箱理论说起。
苹果公司的黑箱理论:就是用户不需要了解系统或功能背后的实现逻辑,只需要关注呈现在用户眼前的交互界面即可。
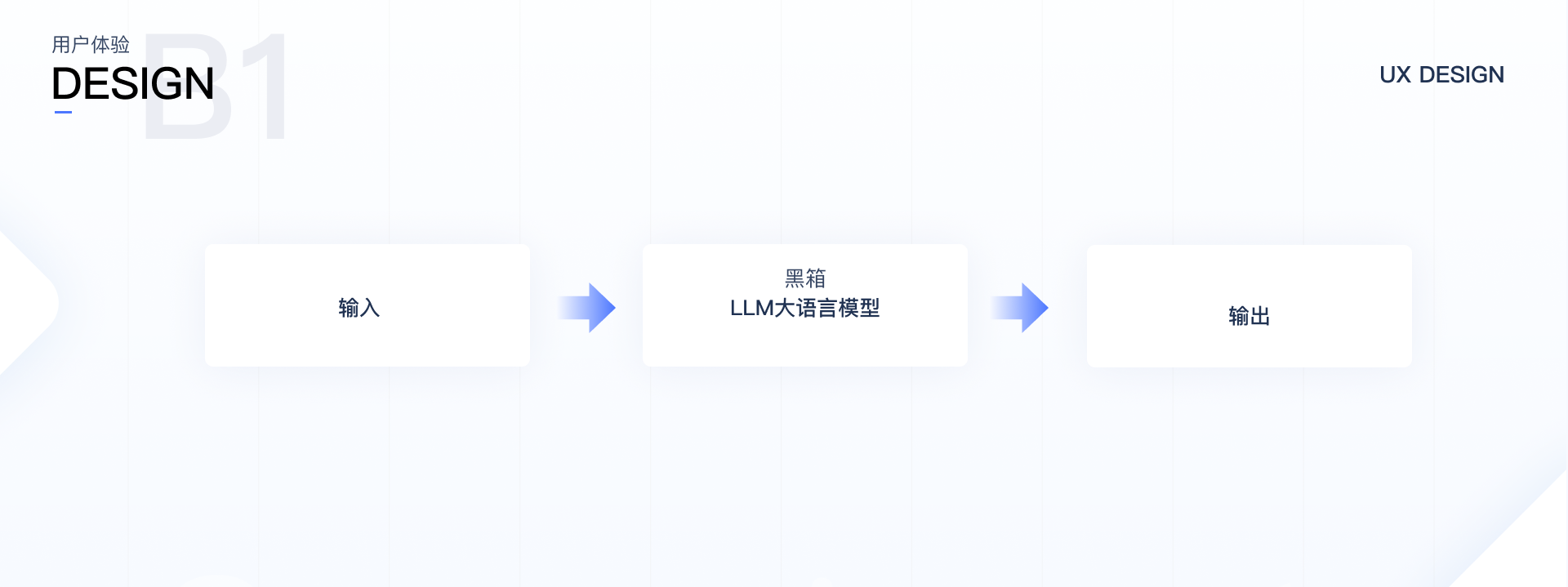
很有意思的是,大语言模型从技术上来说本身就存在黑盒特性,这些模型的内部工作机制常常对我们而言是一个“黑盒”。虽然这些模型的代码、参数和训练方法是公开透明的,但我们仍然难以追踪和理解它们如何从特定的输入生成特定的输出。这种复杂性源自于模型内部多层次的非线性数据处理和海量参数的复杂交互,使得追溯和理解其决策路径成为一项巨大挑战。
就像人类决策是由复杂的情感、多重动机和丰富的个人经验交织而成的。AI模型同样如此,尽管我们了解它们的基础架构(类似于人类的基因)和训练过程(类似于人类的教育和经历),但模型如何综合这些因素以做出特定响应仍是复杂且难以预测的。
基于此,从黑盒理论和用户的角度出发,大语言平台本质上可以看成三个模块,输入模块-分析模块-输出模块,由此我们就有了相对简单的观察角度。
输入模块
输入通俗地讲叫向大语言模型提出“问题”,比较专业的说法叫“提示”或“指令”,也有一个专门的工程类别叫“提示工程”;是将信息输入到大模型中的必要前提;很多时候一个好提示将决定结果的输出质量,并且一个问题经常是需要多次迭代才能生成最终的结果,用户的真实想法往往和实际意图之间差了好远。

吴恩达在《给每个人的大语言模型课》中说:“我不认为有一个适合每个人的完美提示,用户选择输入有一个从“想法”到“提示工程”到“模型回复”的过程,更有用的是有一个流程,当我自己在使用大模型时,经常会尝试和迭代,比如如果我不喜欢结果,我可能会澄清,如果仍没有给我想要的确切结果,我可能会进一步进行澄清和迭代。”
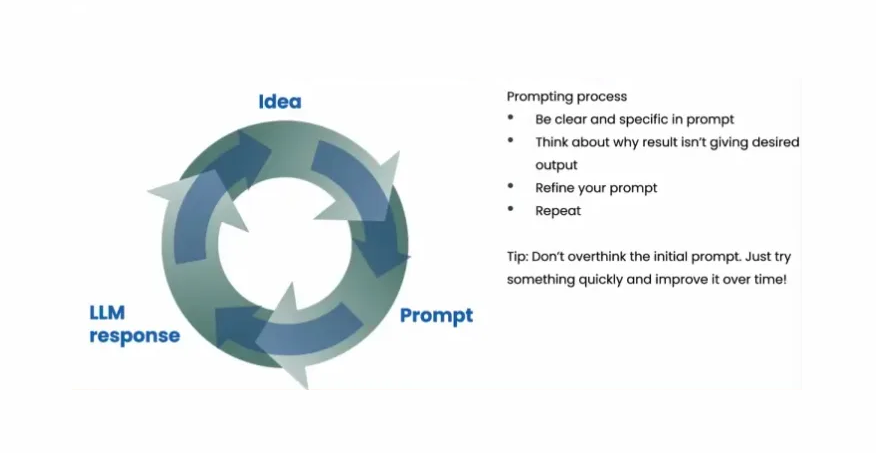
因此,在输入模块,提升用户体验的核心就在于如何更高效地帮助用户从一个想法,不断优化提示,使其更快速地接近所需答案的过程。
国内外生成式AI技术平台为此做了很多的努力。输入本身是有成本的,我根据用户痛点,对大语言模型平台的核心功能点进行了梳理。

降低输入成本
OK,小朋友们,让我们回到小时候的语文课堂,当我们在描述一件事情的时候,通常会遵循5WH原则,即什么人在什么时间点在哪里做了什么事情,是如何做的,为什么做。同样的,在向大语言模型输入提示的时候,我们依然可以遵循这样的原则。
who:我是谁why:我为什么想要问这个what:我想要什么结果when:什么时候完成where:这个提示的具体场景是什么how:最终输出的要求是什么
但往往,可能是因为在真实的社交场景中,人与人在互相交流前就已经事先共享了一部分信息,在描述事情的时候也不需要那么全面。大语言模型尽管由海量的数据训练出来,但面对单个用户时,双方其实并没有事先共享信息。所以帮助用户降低输入成本就比较重要了。
主动理解意图
当面对交谈的对象语无伦次,东一榔头西一棒槌地描述的时候,我们会反问:“你想说的是不是这个...意思?”。在输入模块,平台帮助用户做的也是这么一件事情:你想表达的东西,我帮你表达一部分,你看看是不是这个意思。
ChatGpt的对话框下提供了多个用户常见的场景,创建图片|给我惊喜|总结文本|分析输入|分析图片|帮我写等。点击之后推荐对应场景的联想问题来帮助完善提问。
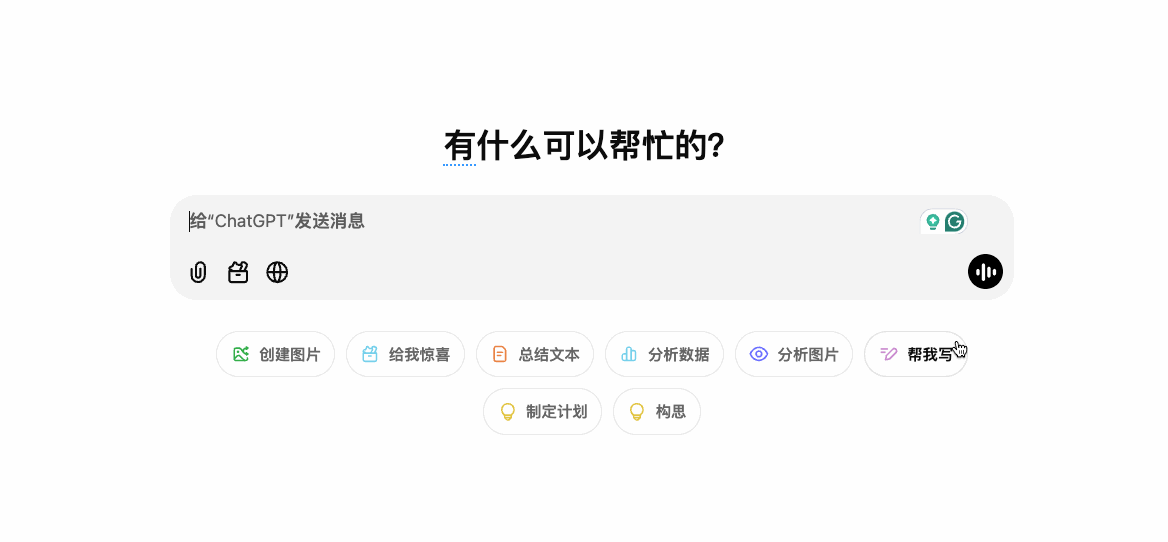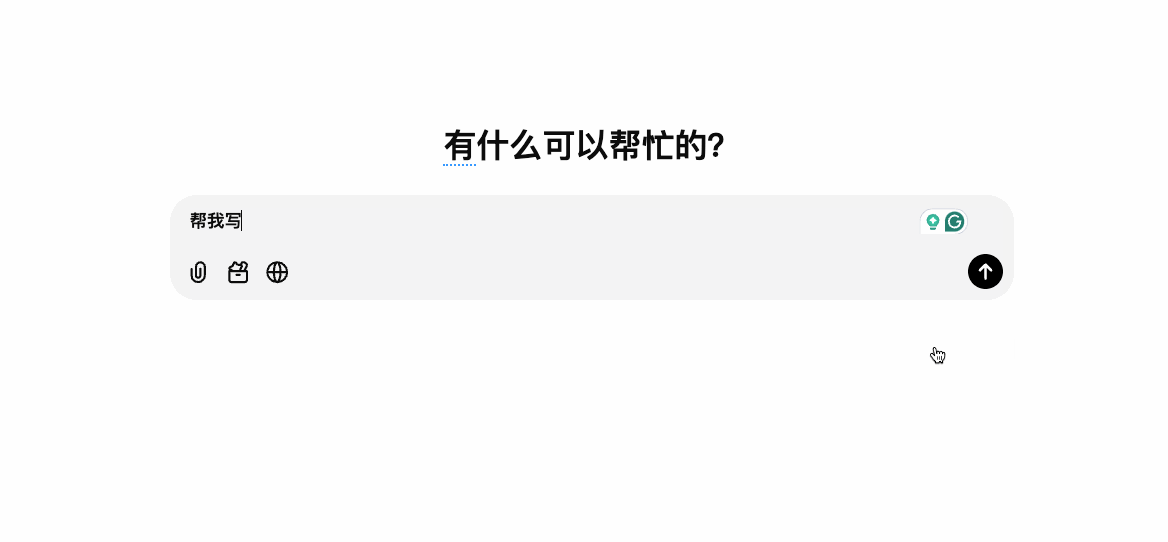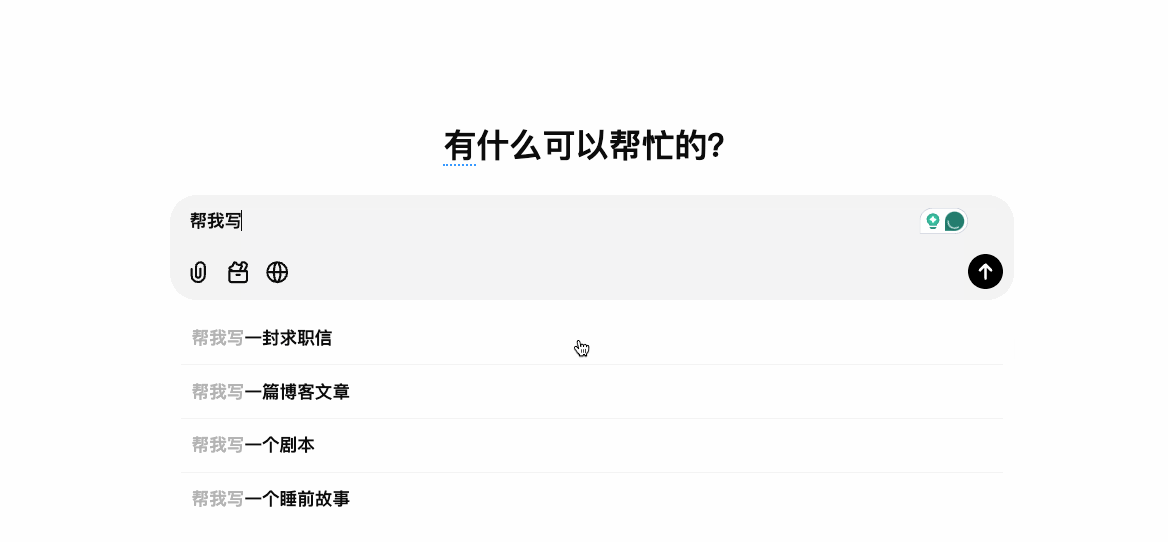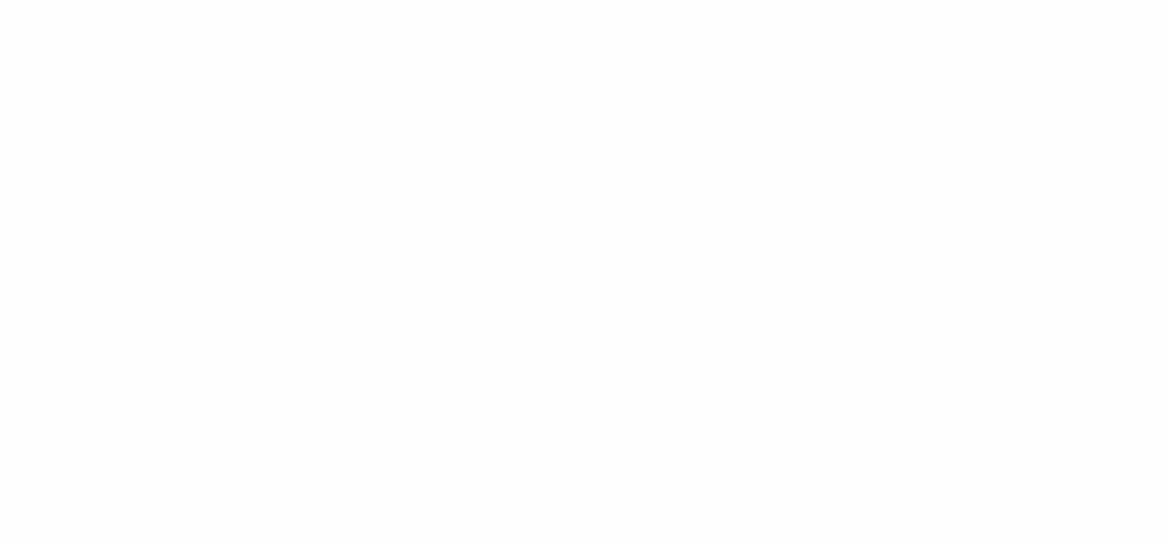
豆包和文心一言甚至更贴心地把常用技能模块细分到更加具体的使用场景,进一步明确用户的目标,事先提供对应场景的功能,并且提供对话模版,用户只需要在对应窗格中填充文字即可。

Copliot在界面上提供各式各样的主题卡片,教育用户如何提问。

Kimi在输入关键词时向用户推荐更加全面的相关的提示词参考,提前理解用户意图。并且在后续的生成结果中,继续提供用户可能会提问的问题来引导用户。
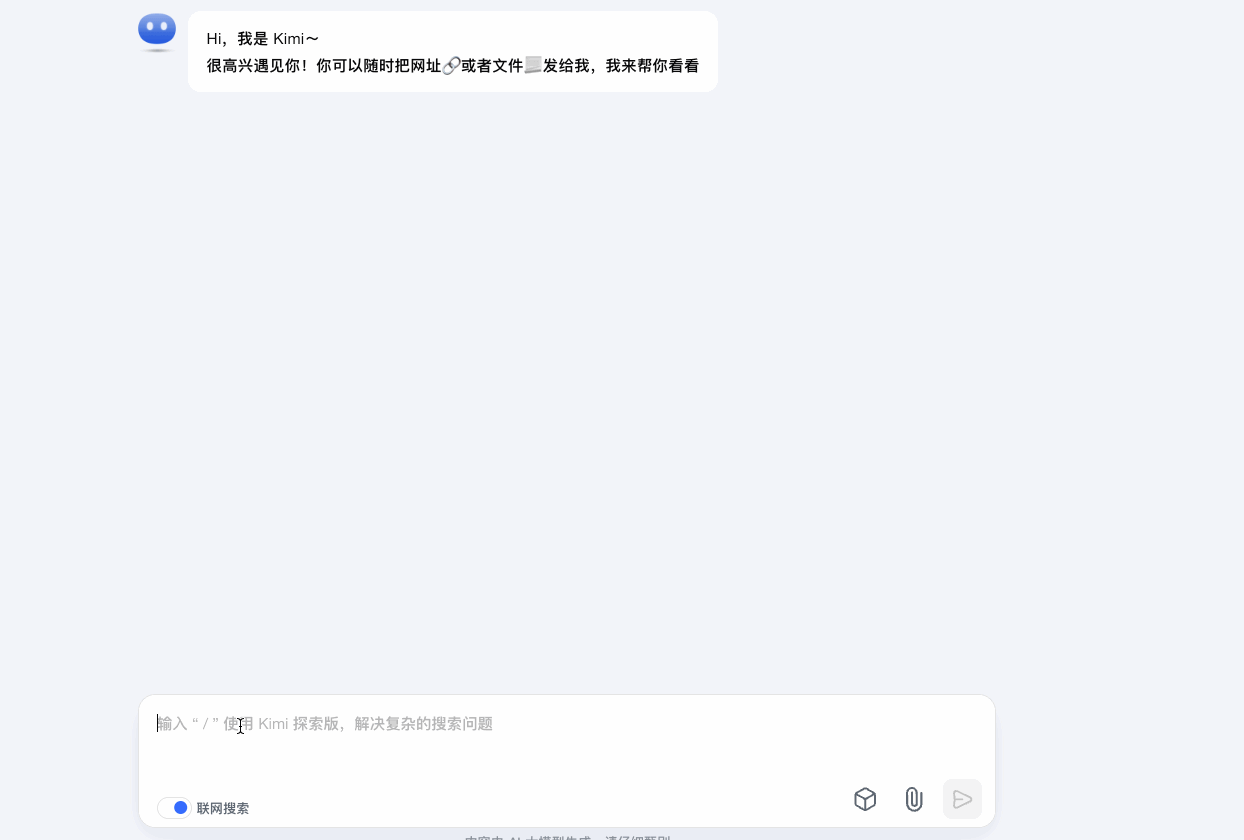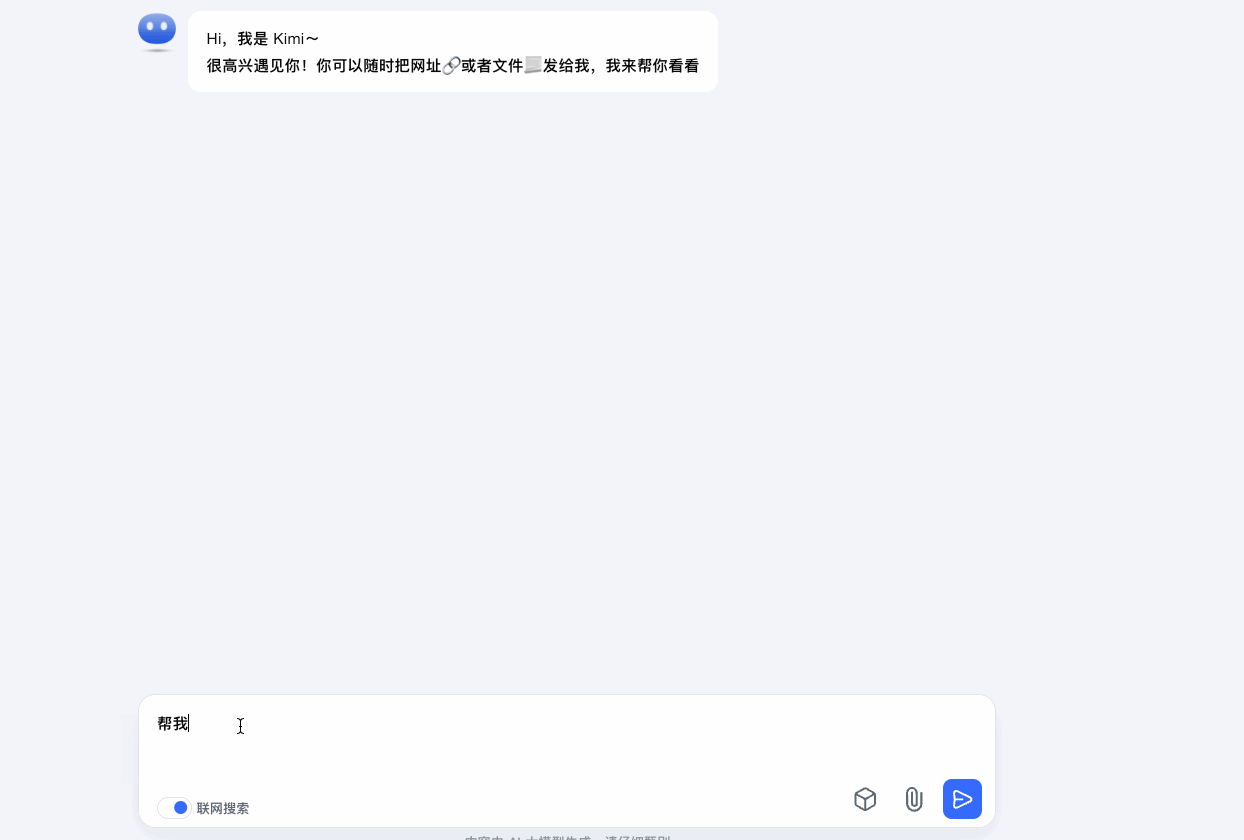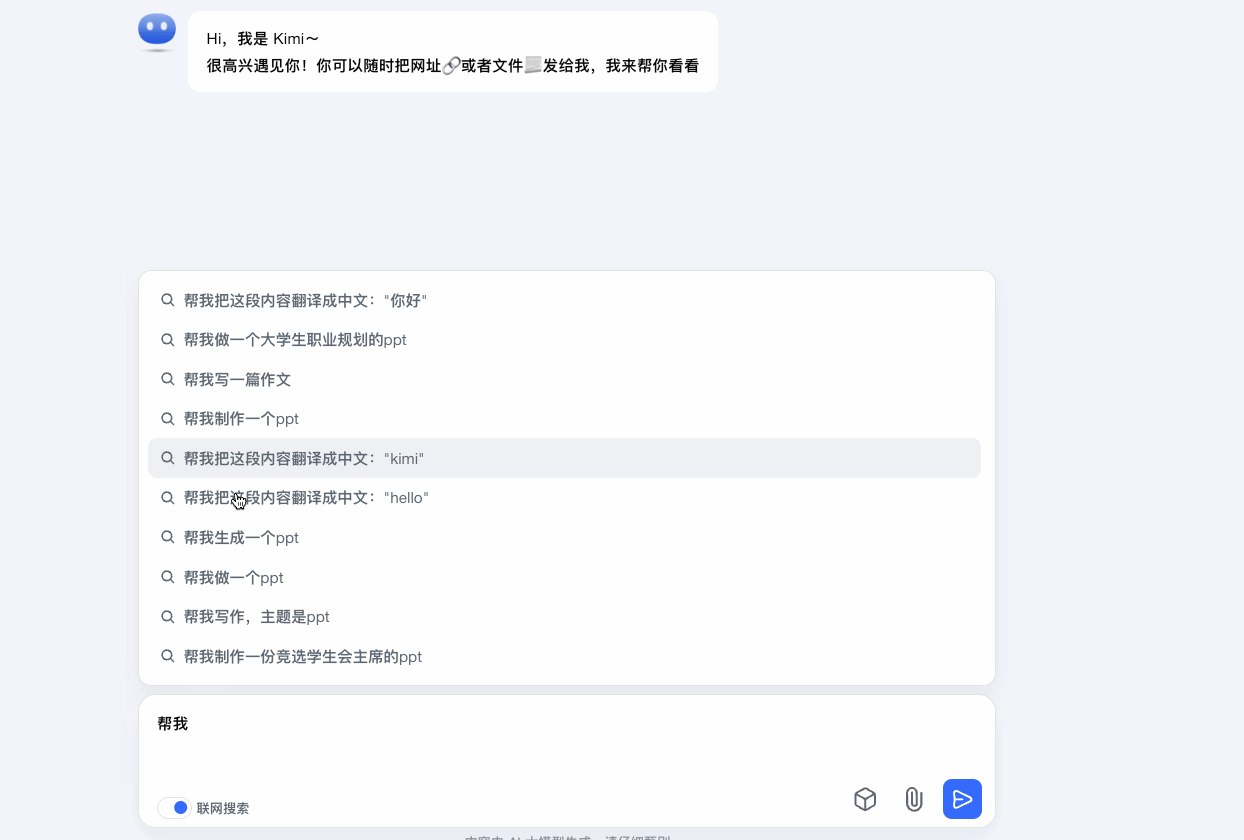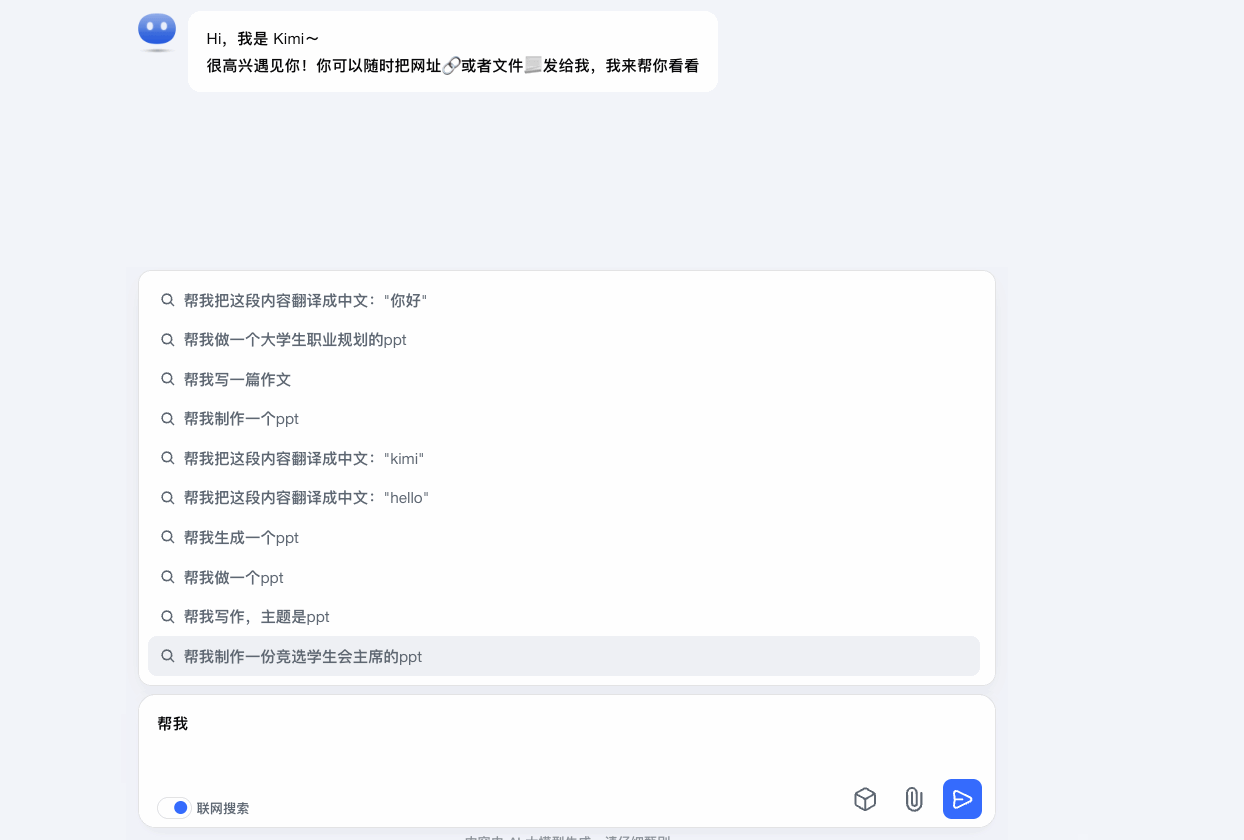
增加输入参考
当有些信息无法用简短的语言描述时,比如图片、文档、网页,最简单直接的办法就是直接上传上去,作为输入的附加参考。用户只需说:“参考这个内容帮我做XXXX事情”,这些附件内容会和文本信息会一起送进大模型黑盒里去。如今上传文件,上传图片,联网搜索,语音输入已经成为了生成式AI平台的标配功能。

自定义智能体
除此之外,尽管大模型很通用,在对话时,对于特定领域的业务,还是需要针对不同的属性进行定制化,让大语言模型先有一个明确的自我定位;比如是一个数据分析专家,或是健身教练,也可能是多角色的集合体AIAGent。
ChatGpt的探索模块支持使用并创建自己的智能体,针对特定的使用场景:提高效率|体验交流|价值创造提供多种多样的自定义版本的智能体。

Kimi+针对办公提效|辅助写作|社交娱乐|生活实用的特定场景提供各种各样的智能体。同样类似的还有文心一言、360AI、通义千问等。
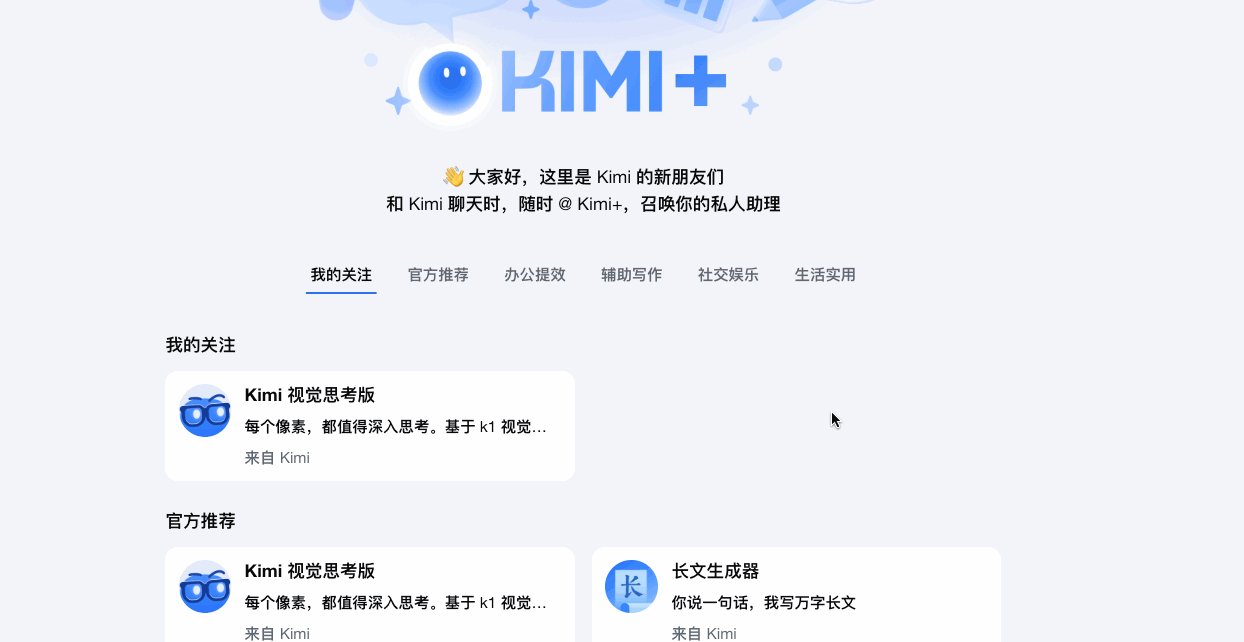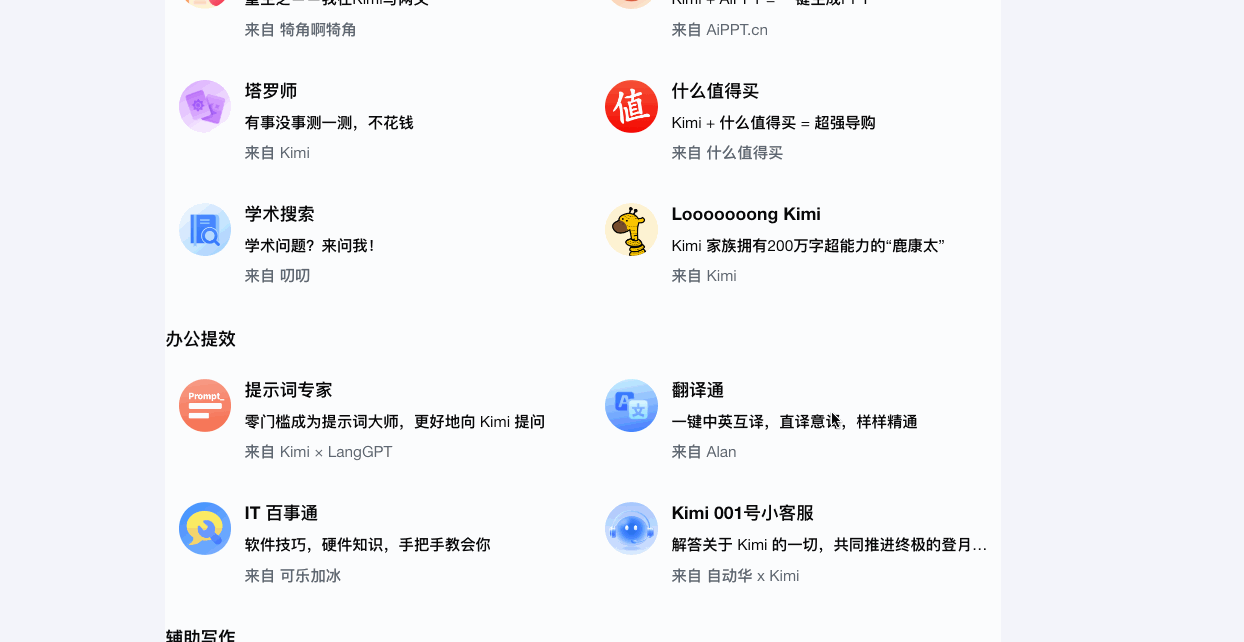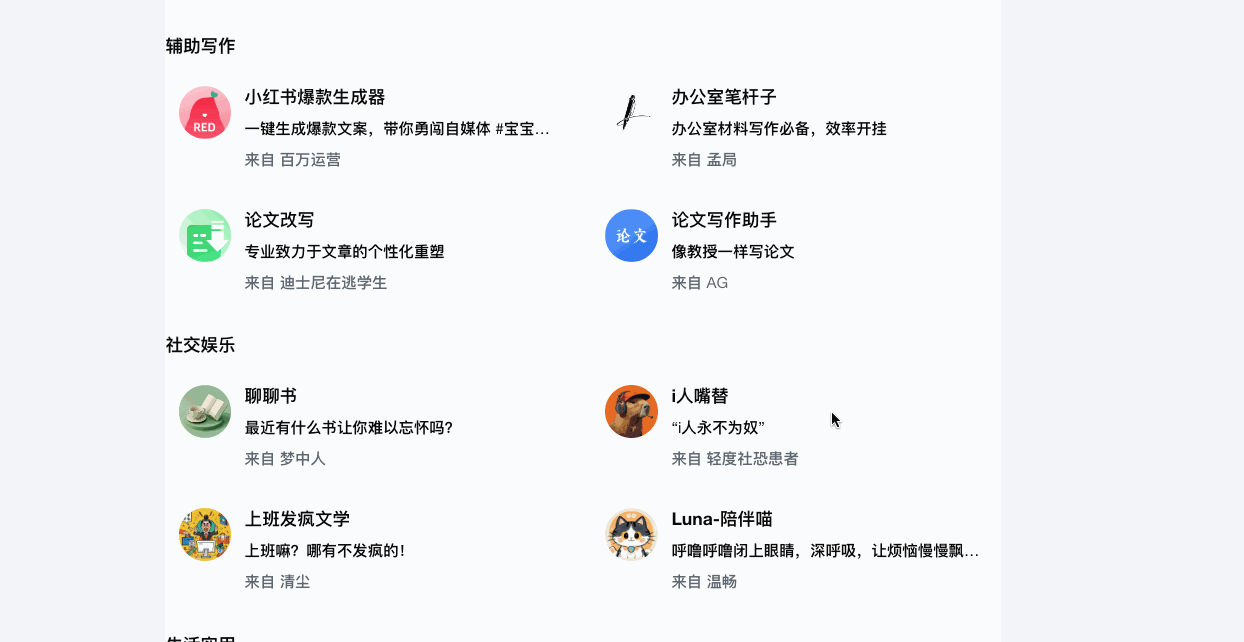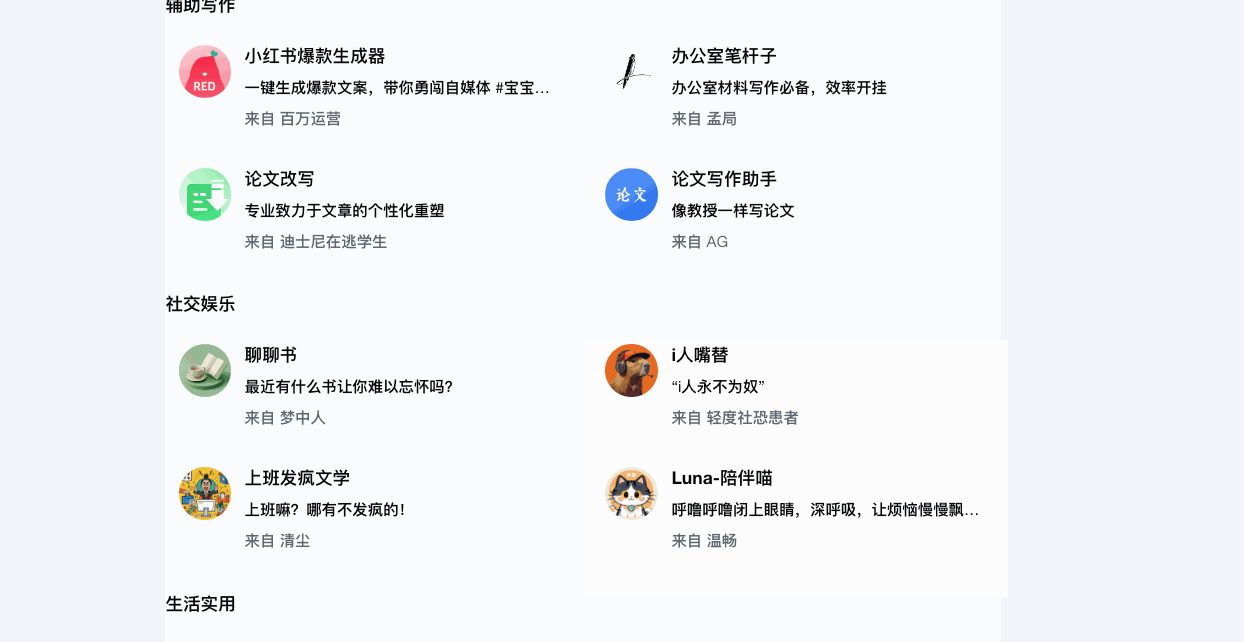
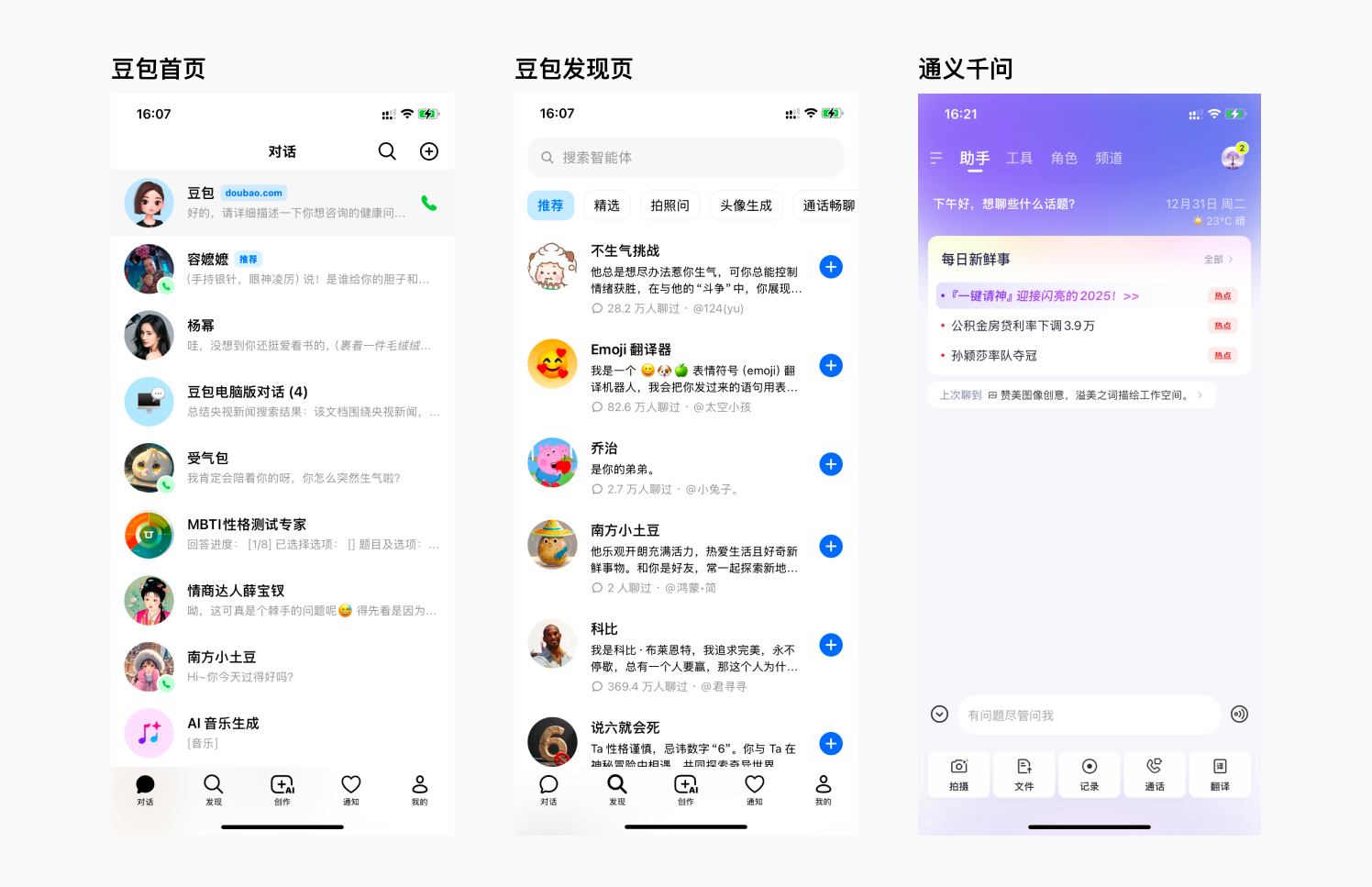
而豆包比较有趣,在网页端,还比较正经,推荐了一些跟提效创作有关的智能体。而到了手机端,豆包自己本身变成了一个几乎和其他智能体权重平等的应用,发现页中推荐了各种各样的情绪体验型智能体,主打和各种各样的明星和数字人聊天、打电话、谈恋爱、玩游戏,获得陪伴体验。在集体AI平台都在卷AI硬知识技能时,豆包选择了将AI和娱乐挂钩起来,让AI产品变得有趣,在年轻人的荷尔蒙中发酵,这是互联网流量思维的玩法。
分析模块
在分析模块,当前主流大模型尽管在语言理解和文本生成上表现优异,但仍然在一些方面体验不佳:大模型回复等待时间长;不允许打断、插话;存在幻觉等。我将从这三点聊聊体验设计在其中的应用。
等待时间长-减少等待焦虑
在过去的加载页面等待研究中,我们有这样的共识:用户等待页面加成功时的耐心程度一般在2-3秒范围内,GooGle研究显示,大约53%的移动设备用户会在加载超过3秒时离开,每增加1秒延迟,用户转化率可能下降7%或更多,过长的等待时间会让用户感到不耐烦。
耐心时间范围
0-2秒:最佳用户体验,加载速度快的页面会显著提升用户满意度。3-5秒:用户的注意力开始下降。如果加载时间超过这一范围,可能会导致用户放弃。6秒以上:用户放弃的可能性显著增加。研究显示,大约53%的移动设备用户会在页面加载超过3秒时离开。
因此,过去如果系统加载慢,用户体验师会设计加载动画或进度条,优先加载关键内容等方式来延长用户耐心,生成式AI平台也通过类似的方法来提升用户体验。
ChatGPT通过逐步每次都将生成的部分内容展示出来,使用户可以边阅读部分边生成来延长用户的忍耐程度。如果你在python中调用过大模型的API的话,大模型只会在生成所有文本后返回结果。你会发现大模型在生成长文本的时间其实还蛮长的。

通义千问和秘塔搜索通过展示加载分段式进度条来告知用户任务完成程度,降低时间感知,避免不确定等待。进度条的存在也能显示系统正在正常工作,增强用户对平台的信任。

Gemin通过logo动画,更加自然的淡入淡出刷新文字的加载动画,来进一步体现所搭载的大语言模型性能

不允许打断、插话-提供打断工具
不允许打断插话这一点当前业内普遍做法都是提供停止输出工具,功能大多也大同小异。
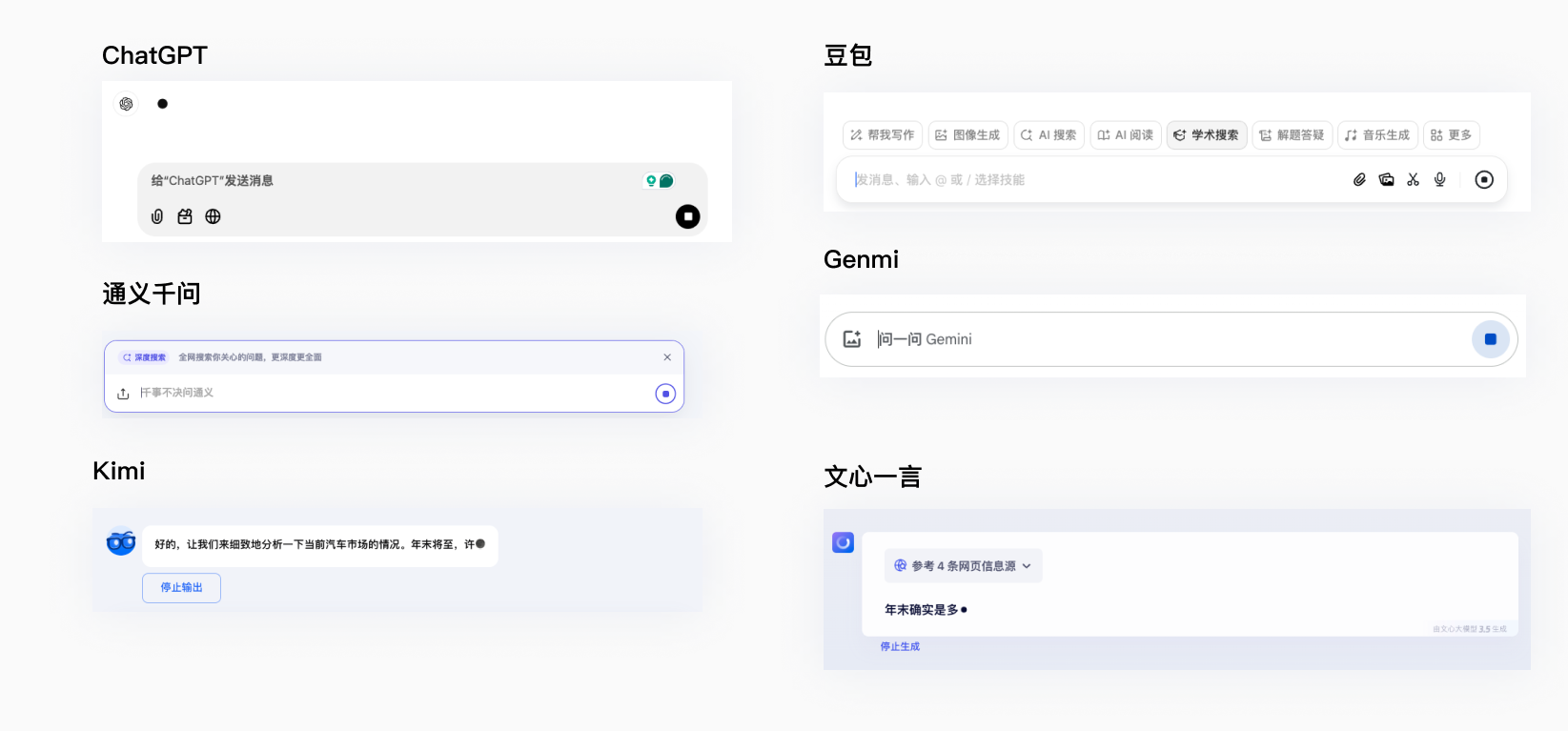
不过最新的ChatGpt提供的画布模式,支持了对分析结果的具体内容进行进一步地编辑,引导用户进一步细化结果。
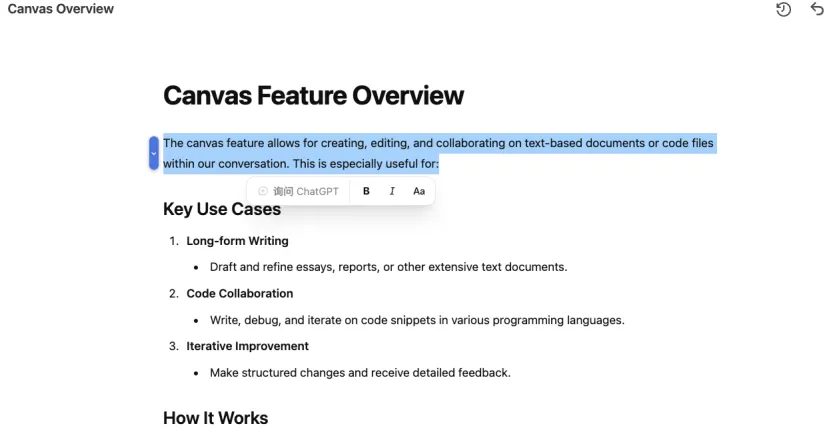
大模型存在幻觉问题-安全意识
由于大模型的黑箱特性,尽管RAG等数据投喂技术在一定程度上减少了大模型的幻觉,但当前业界最好的大模型推理一致性在97%左右,幻觉度约3%,距离ToB/ToH领域的规模应用,如网络规划、仪表和电器精准控制尚有差距。故AI生成能力本身的可信任度依然是需要担忧的事情。为此,在用户体验层面,设计的核心点在于增加大模型生成结果的客观性。
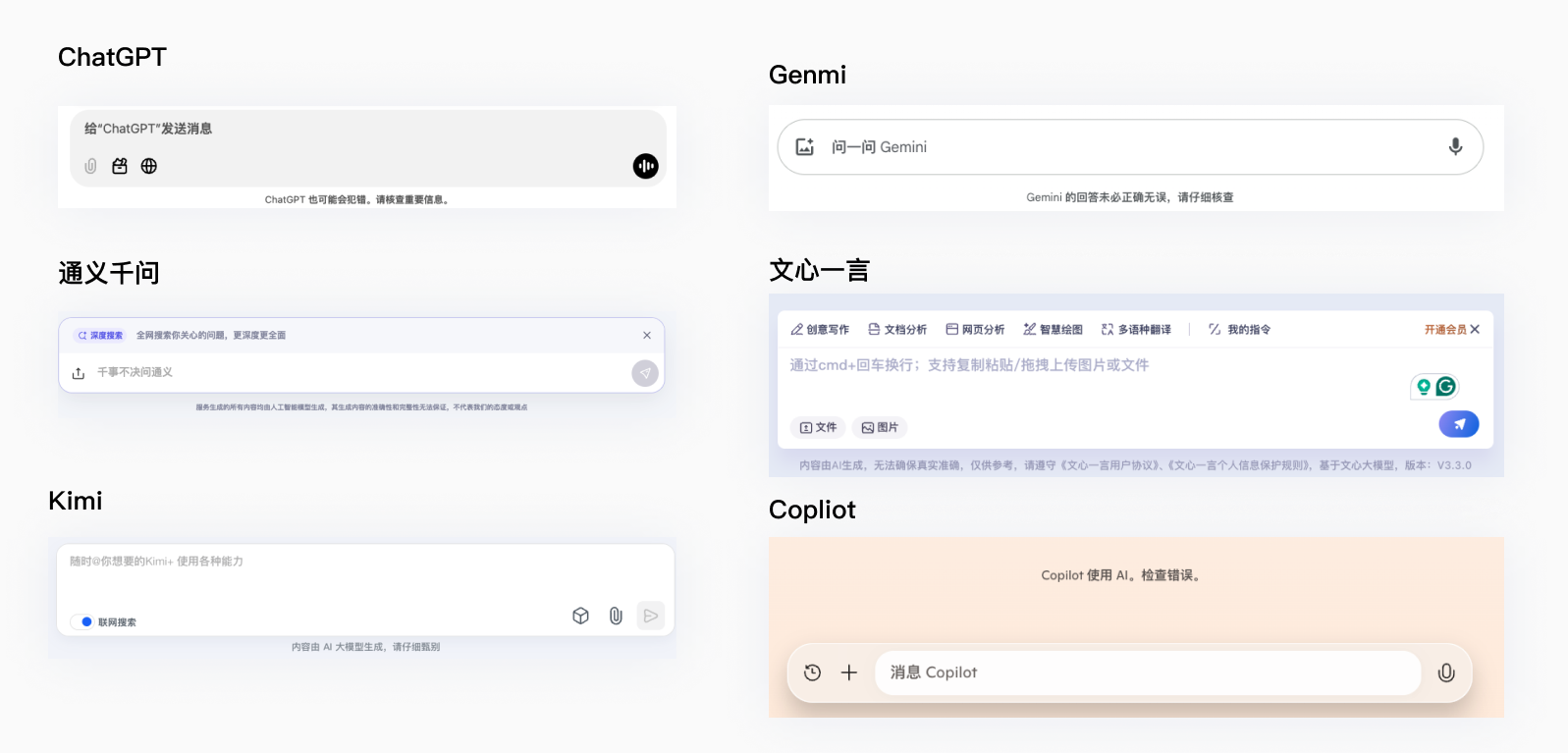
增加安全提醒-降低信任预期
大模型需要告诉用户生成的内容仅具有参考性,也可能会犯错,通常会在界面对话框底部强调。
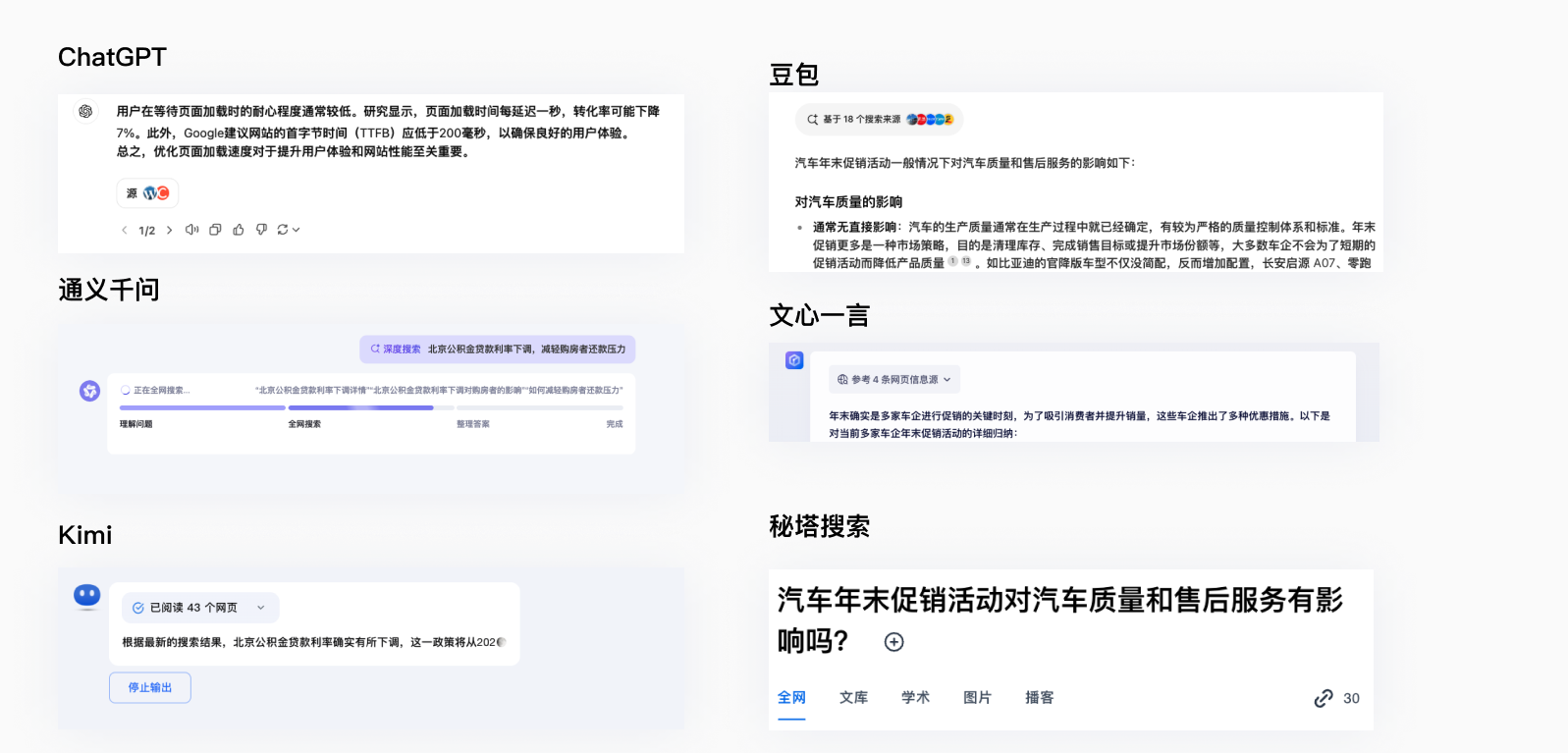
参考多篇网页内容-增加生成内容客观性
通过RAG、LanGChain等技术与搜索引擎结合,从多个来源提取关键信息,实时检索和验证,生成综合性的回答,减少“幻觉”现象,提升答案的准确性和可信度。
输出模块
在输出模块,我想聊聊大模型的记忆、反馈、多模态输出的体验设计。
记忆模块
如果用python调用过大模型的API的话,我们会意识到大模型本身是没有记忆的。但是在与用户的对话中,平台会将当前会话的上下文信息作为输入模型的一部分,利用注意力机制处理这些信息,从而生成与上下文相关的响应,使得模型能够在单词对话中保持对近期信息的记忆,从而提供连贯的回答。
然而,大模型的上下文窗口长度是有限的,通常在数千个标记(toKens)范围内。这意味着当对话长度超过上下文窗口的容量时,早期的信息可能会被遗忘或忽略。技术层面研究人员为此提出了多种方法来增强模型的记忆能力。比如循环记忆、引入外部存储机制等,但仍然存在一定的局限性。
于是我观察到了针对这一场景的体验设计:
ChatGpt提供了归档功能,通过归档功能,ChatGpt可以记住用户在之前对话中的偏好、习惯或重要信息(如兴趣爱好、工作方向),从而更接近用户的需求。
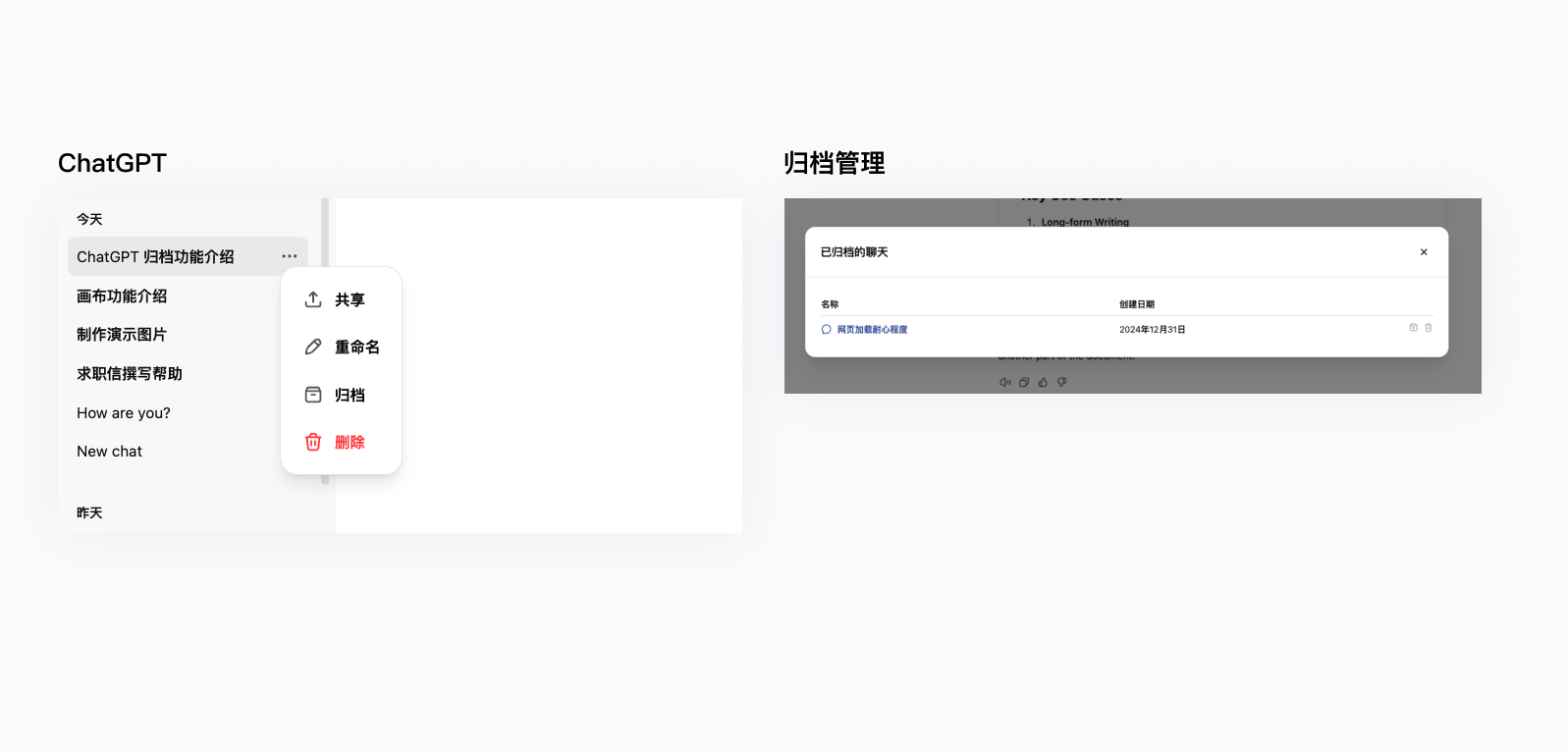
Kimi/通义千问/文心一言则通过设置常用语功能来应对可能出现短期记忆突然失效的情况。
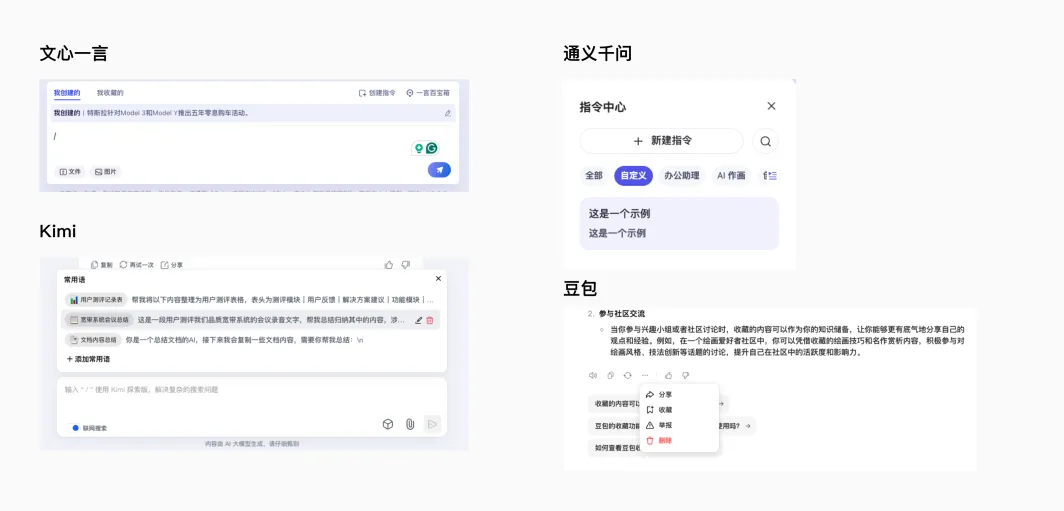
反馈
说了这么多,生成式AI平台的核心竞争力说到底依然是大模型本身的推理能力,如今的大模型依然容易继承和放大训练数据中存在的偏差,AI大模型难以避免会写出看似合理但不正确或荒谬的答案。大模型开发过程中很重要的环节是数据标注,会耗费大量的人力物力,ChatGpt的问世离不开背后大量工程师对模型数据微调校正标注的努力。
同时,AI平台的模型能力的增强也需要用户的反馈,通过每天用户海量的生成结果,从反馈给平台以进一步优化模型推理能力。越强推理能力的大模型平台拥有越多的用户,越多的用户越增强大模型推理平台的能力。
而这个反馈入口就在输出结果的下方,用户可以点击喜欢/不喜欢进行问题反馈,几乎所有的AI平台都有这个看似不起眼,但非常重要的功能。
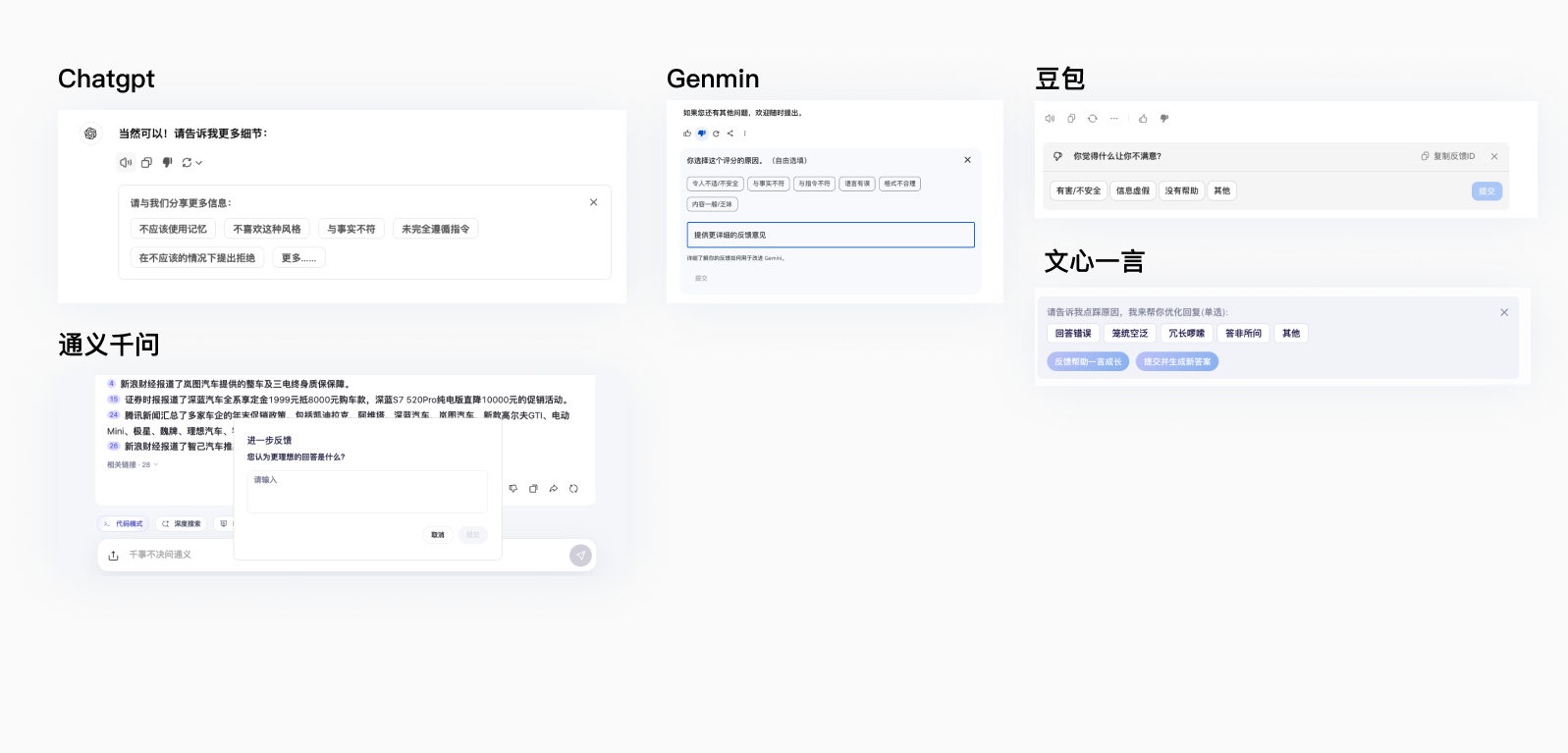
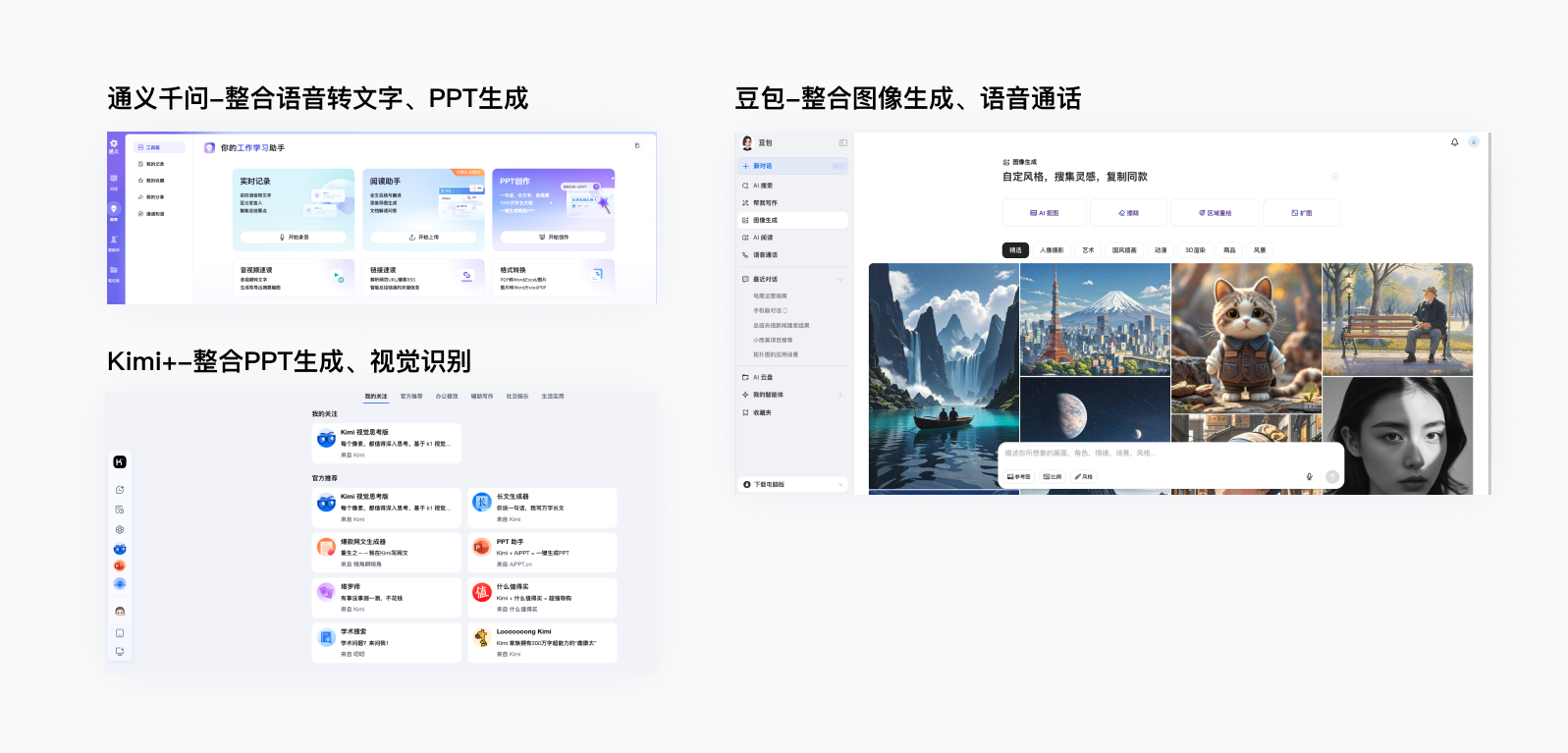
多模态输出
尽管可能我们认知里的大语言模型平台更多是专注于文本类型输出,我观察到国内外很多的大模型平台都在往多模态生态方向打造,大语言模型正在和文生图、数字人、机器人、文生视频、内容理解、文本处理、社区等功能融合。背后的逻辑比较复杂,我将在下一个模块再聊。
88
举报
声明
225
分享
相关推荐

















评论你的想法~
表情
喜欢TA的作品吗?喜欢就快来夸夸TA吧!
推荐素材
















你可能喜欢














相关收藏夹























登录注册
88登录即可同步推荐记录哦
99+登录即可加入我的收藏
评论登录即可评论想法
分享分享