腾讯文档 | 数据化设计


It is ultra experience
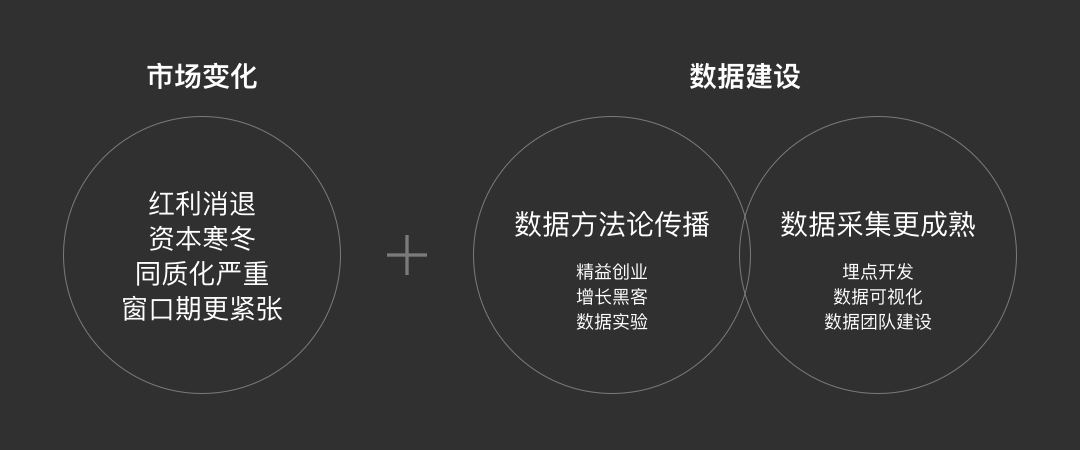
2015年之后的中国互联网,人口红利、流量红利逐渐退场。2019年遭遇第一场资本寒冬,上半年投资总金额同比下降了58.5%。也在2019年,“精益创业”、“精益数据分析”、“增长黑客”等一系列数据思潮开始流行。而UX设计师作为半个产品经理,我们很容易将这股“数据热”迁移到自己身上:每个UX设计师都要学数据分析了吗?数据和设计是什么关系?天天盯数据会限制设计师的想象力吗?数据到底要怎么用?……

Preview
——————————
数据热
过往,设计师一般不会把“数据”挂在嘴边。我们提倡“以用户为中心,打磨极致用户体验”,较少考虑成本和商业效益。
通俗来说,就是产品经理负责“生意”,设计师负责“体验”。以“造鞋”为例子,产品经理做了市场调研,决定要生产儿童运动鞋,设计师负责设计“适合4-11岁的儿童在城市公园玩闹”的鞋子应该长什么样、穿着它跑跑跳跳是不是舒服的。但是设计师不需要担心运动鞋的销量,产品经理则要跟老板汇报销量业绩。
在红利消退、产品同质化严重和快速迭代的多重压力下,UX设计迎来了更高的挑战:仅凭主观判断“好不好用、好不好看”来打磨产品内在体验,不考虑产品的生存、增长和盈利,很难在行业立足。与此同时,随着数据采集工具的日渐成熟,数据以“客观”和“便捷”两大特点,帮助我们更快获得“设计的依据”。精益化设计是必然趋势,而“数据分析”是精益化设计的手段之一。
沿用“设计鞋”的案例,UX设计师要在自己所在领域思考:在设计调研的过程中,我们用什么数据指标来衡量这个儿童鞋好穿、好卖?在鞋进行批量生产前,我们有没有数据资源支持我们研究父母/小孩对鞋子外观的偏好、小孩运动时容易受到哪些物理伤害等等?如果有条件进行小范围的数据实验,我们如何设计数据实验来评估好穿好卖?

PART 01
——————————
数据的定义
“理解任何事物都需要先对它进行定义,这样才能够在头脑中清楚地知道正在讨论的是这个东西,而不是其他东西。”非常喜欢美国经济学家Thomas Sowell在《经济学的思维方式》里说的这句话。
如果我们对“数据”下定义,那么产品设计语境中的“数据”具体是什么?数据是怎么产生的?
从数据采集手段来看,互联网产品的数据来源主要有3个:二手资料数据、问卷调研数据和应用埋点数据。

1/ 二手资料数据
行业数据和竞品数据一般通过二手资料获得,包括商业交易数据、用户群的态度和意愿、用户舆论指数、竞品的用户规模和盈利状况等宏观数据。常用的搜索渠道有:百度指数、企鹅智酷、艾瑞、尼尔森、各大科技资讯平台等。
我们可以将这些理解为“市场数据”,在立项期对产品方向有一定指导意义,能快速了解市场概况,也能帮助产品思考差异化定位的问题。
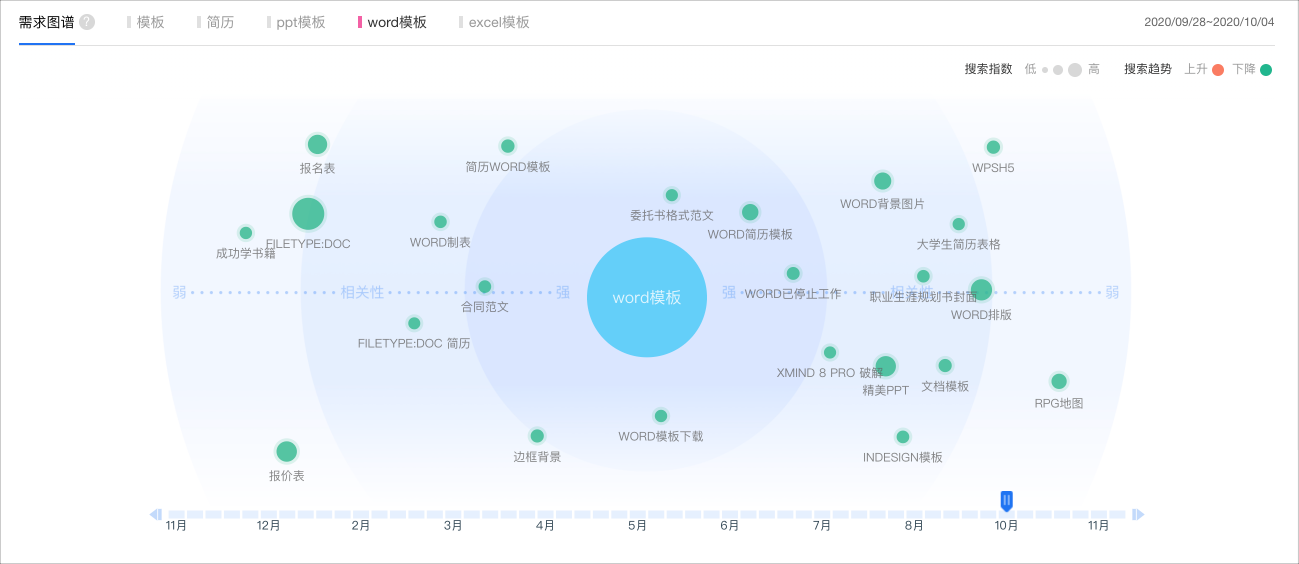
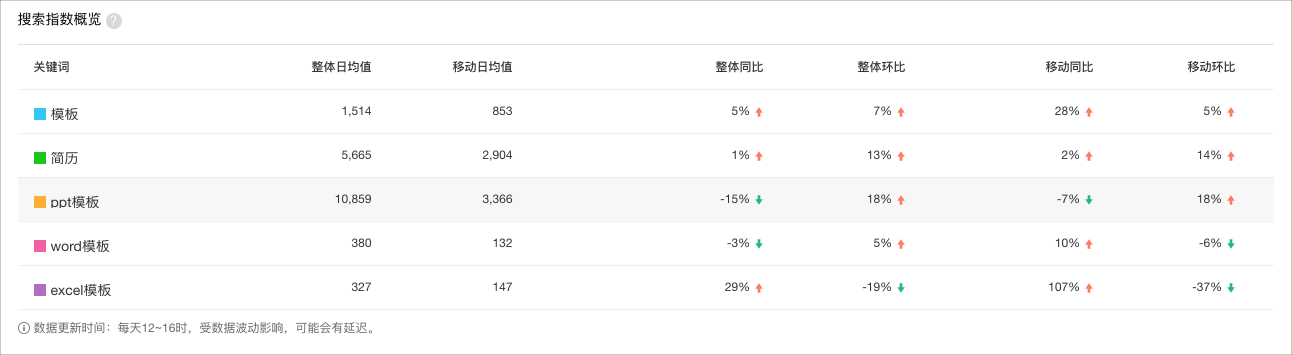
以“腾讯文档为”项目为例,我们想提高腾讯文档用户创建文档的成功率,通过模板创建文档是关键路径之一。研究用户通过模板创建的路径时,想大概了解用户找模板时可能会在意什么。于是我们尝试使用百度指数搜索“模板”、“文档模板”、“PPT模板”、“Word模板”、“Excel模板”,从搜索量得知:PPT模板搜索量最高,符合我们的推测;Word模板内容中,简历、合同需求量较大,而部分用户只是想要好看的Word背景等等。虽然我们得到的有效信息不多,但我们能够通过二手资料的方式,快速了解用户需求的基本面。
2/ 问卷调研数据
问卷调研数据是通过向目标用户发放问卷获得的,侧重于收集人口学信息、用户自述的历史行为、主观态度或意愿,比如用户满意度调查、流失用户原因调查等。本质上是通过建立假设、再进行抽样统计的方法来得到用户口述的答案。也就是,问卷倾向于听用户说了什么、而看不见用户真正做了什么。严谨的问卷分析也会比对后台数据,校验用户说的和做的是否一致,以清洗无效数据。
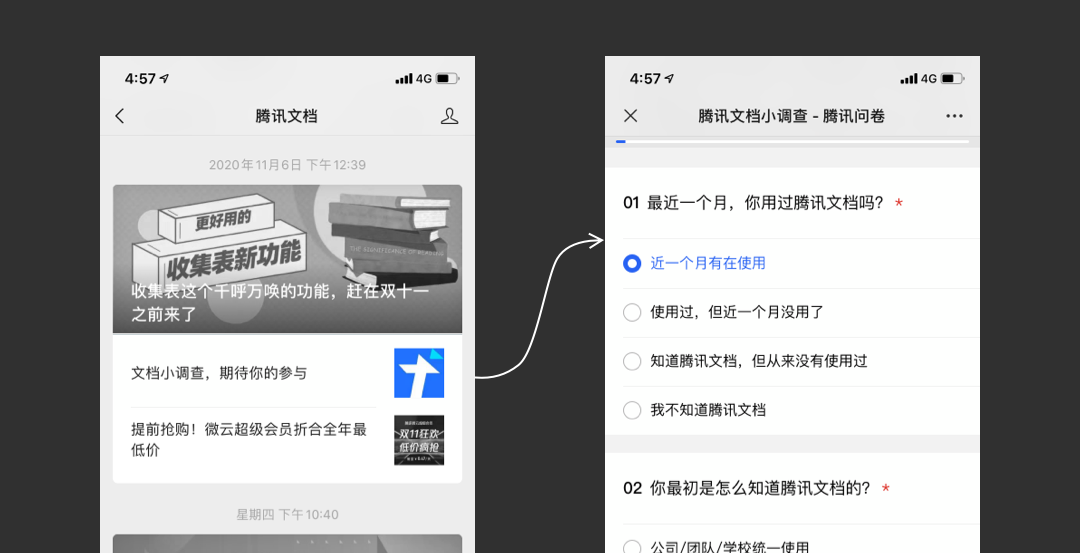
3/ 应用埋点数据
较之于问卷调研数据,我们想看“用户做了什么”,则通过分析应用埋点数据获得。
“应用埋点数据”也叫“埋点数据”、“前端页面数据”,我们可以简单理解为“通过技术手段获得用户在应用内(网站、客户端、小程序等)的操作行为数据”。其背后原理是:用户和界面发生交互,系统需要向服务器发送请求和返回请求,把这些请求预埋一段计数代码,就能得到页面的曝光数据和用户的操作数据。
埋点需要产品经理或设计师做好数据指标的定义,跟开发工程师提前沟通,让开发工程师在代码中嵌入埋点。一个埋点由多个字段组成,规范地定义字段,有利于我们在数据平台搜索埋点更方便。当我们怀疑数据有效性时,也更方便排查埋点问题。

埋点类型可分为曝光埋点、操作埋点和时长埋点:
1. 曝光埋点可以捕捉页面被展示的次数,可以是针对整个页面,也可以是页面中的某个区域。即我们常说的PV、UV。
2. 操作埋点则是在用户对页面某个区域(按钮、卡片、提示条等)进行手势操作(点击、双击、长按、滑动等)时,进行打点记录。对应的,也称之为某个操作的PV、UV。
3. 时长埋点是通过标记以上两类埋点、并计算时间差获得的。比如,我们记录用户选取模板耗费的时长,可以通过离开页面的时间(t2)-进入页面的时间(t1)计算。而离开页面则用点击左上角返回按钮、点击具体模板等“离开”操作来核算。
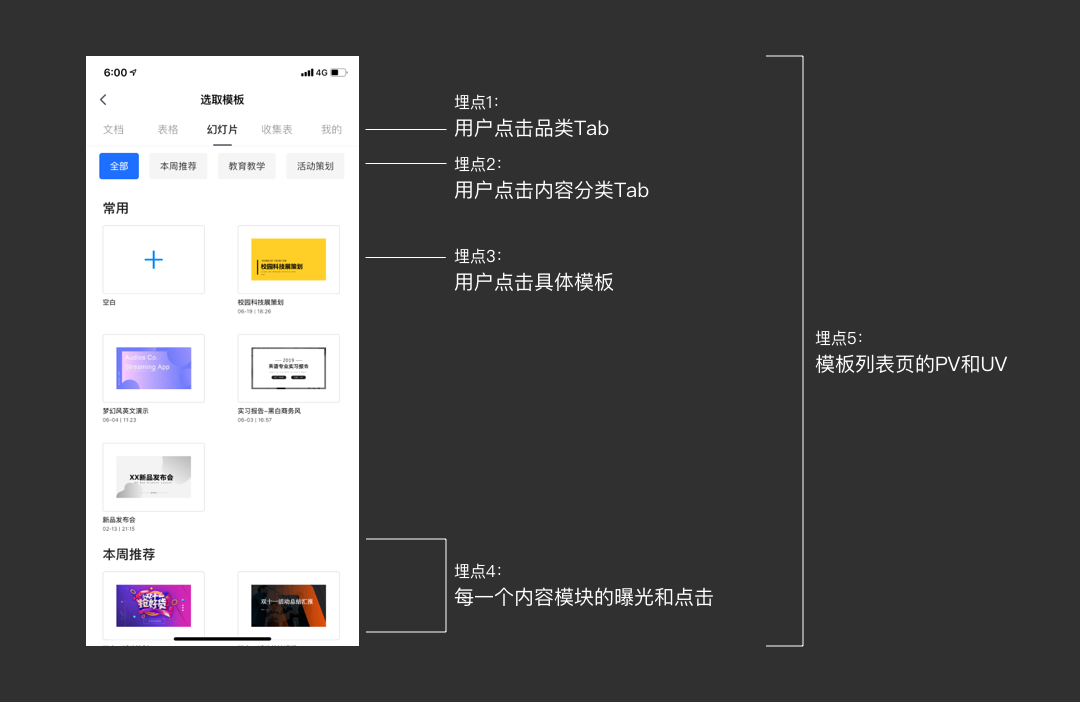
基于以上3种原始数据,我们可以运算得出点击率、功能渗透率、人均点击次数、人均使用时长等具有对比价值的数据。
较之于二手资料和调研数据,埋点数据更加贴近用户的真实表现,作为反馈指标的灵敏度更高,可挖掘性更强,也能作为客观衡量指标引入到每一次产品迭代中。
设计师理解埋点的原理,有助于在数据采集环节跟数据开发更好地沟通,并提出合理的数据需求。另外,当我们拿到一组数据,也需要从根本原理上去判断数据的信度和效度,确保数据没有质量问题再进行下一步分析。
PART 02
——————————
数据之于设计
数据分析能力会在UX设计师的岗位招聘要求中被提及,但除了电商和广告行业的数据化设计知识体系较为成熟,其他领域还在探索。另外,相比于市场营销、产品经理、产品运营等职能,设计师的分析框架是相对晚熟的。
实际上,我们很难从招聘广告中归纳“具备数据分析能力的设计师”长什么样,但我们期望这样的设计师对数据的感知力强、分析逻辑清晰、数据经验丰富,对某个垂直领域的数据仪表盘了如指掌等等。
数据对UX设计有什么用?或者说,在设计链路的哪一个环节,数据和设计才能发生化学反应?

UX设计日常流程为:得到一个需求(需求评审/需求挖掘)——输出设计方案(设计决策)——验证设计方案(设计实验)。顺着这个流程,我们来看看数据在UX设计各阶段的作用。
1/ 需求评审:以提升最终业务数据为目标,评估需求的价值贡献和优先级
肖恩·凯利斯在《增长黑客》开篇就提到“仓筒组织”这个概念:职能组织有各自的KPI,但未必对最终的业务目标都有利。比如开发人力有限的情况下,产品经理想上线新功能,市场运营想搞推广活动,设计想做UI大改版做炫酷的动画——就像N匹马有N个方向,马车跑不快。
尤其是当产品进入成长期,我们会发现“能做的事情真的太多了”!不仅仅是来自老板和产品经理的需求,每天都有用户想教你做产品,刚刚竞争对手又上线了N个新功能等等。另外,当多个产品经理分管不同业务线,每个产品经理都会认为自己提的需求优先级最高。那么,ABCD这几个需求,哪个更值得即刻实现?
有目标导向和成本意识的设计师,不会拿到PRD就开始画稿,而是做需求评审。下次产品经理给你提需求,或者自己想要主动提案,不妨从下面几个问题开始思考效益。
如果这个新功能上线或对已有功能做这些优化点:
|正向评估:如果做,能使哪些用户在什么场景受益?用户会因此使用、消费、甚至推荐我们的产品吗?
|负向评估:如果不做,是否会造成用户口碑变差,甚至弃用我们的产品?
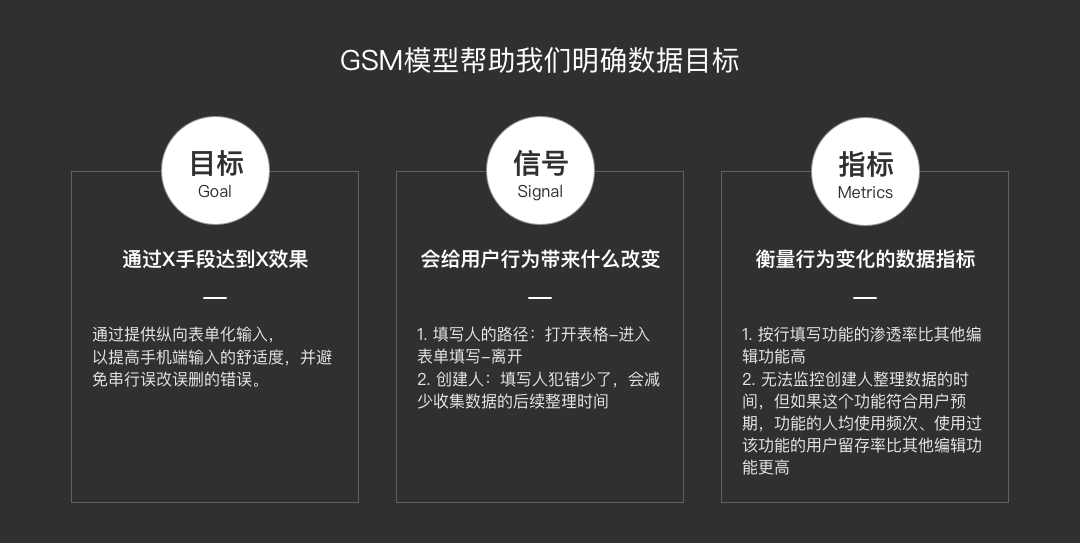
|数据导向:预估这个需求对大盘数据(AARRR)有何贡献?如果无法在短期看到对大盘数据的直接提升,应该取什么样的数据指标来评估其价值(GSM模型)?
|比对优先级:目前有ABCD四个需求,而人力资源有限,当下最应该解决哪个数据环节的问题?
我们以腾讯文档的Excel按行填写功能为例,阐述如何在需求评审阶段就思考数据效益。
一开始,我们只是从用户吐槽中了解到在手机端使用Excel录入信息的困扰:协作人之间容易窜行误删误改别人填写的行,甚至把创建人输入的表头信息都给删掉了。
我们模拟信息收集场景,摘出Excel移动端输入的体验节点,发现“在有限的屏幕内去处理表格信息,需要来回滚动/缩放表格,再回到自己的行再输入”这一点最容易发生错误,尤其在没有冻结首行的情况下。
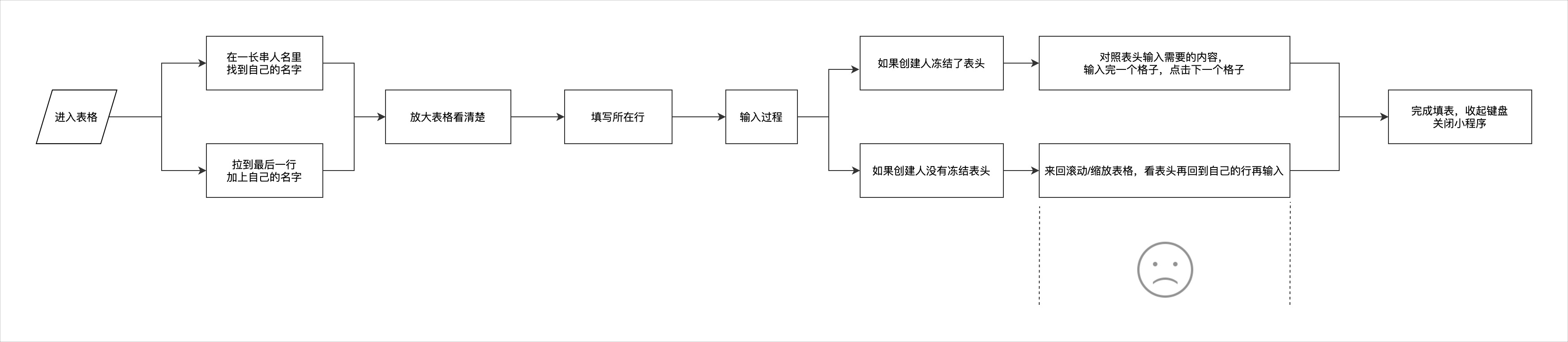
我们有收集表功能,也支持表格转收集表,但是都依赖创建人主动去使用这个品类/这个功能。我们是否可以在创建人不干预的情况下,直接把来回滚动的表格输入变成纵向的表单输入?
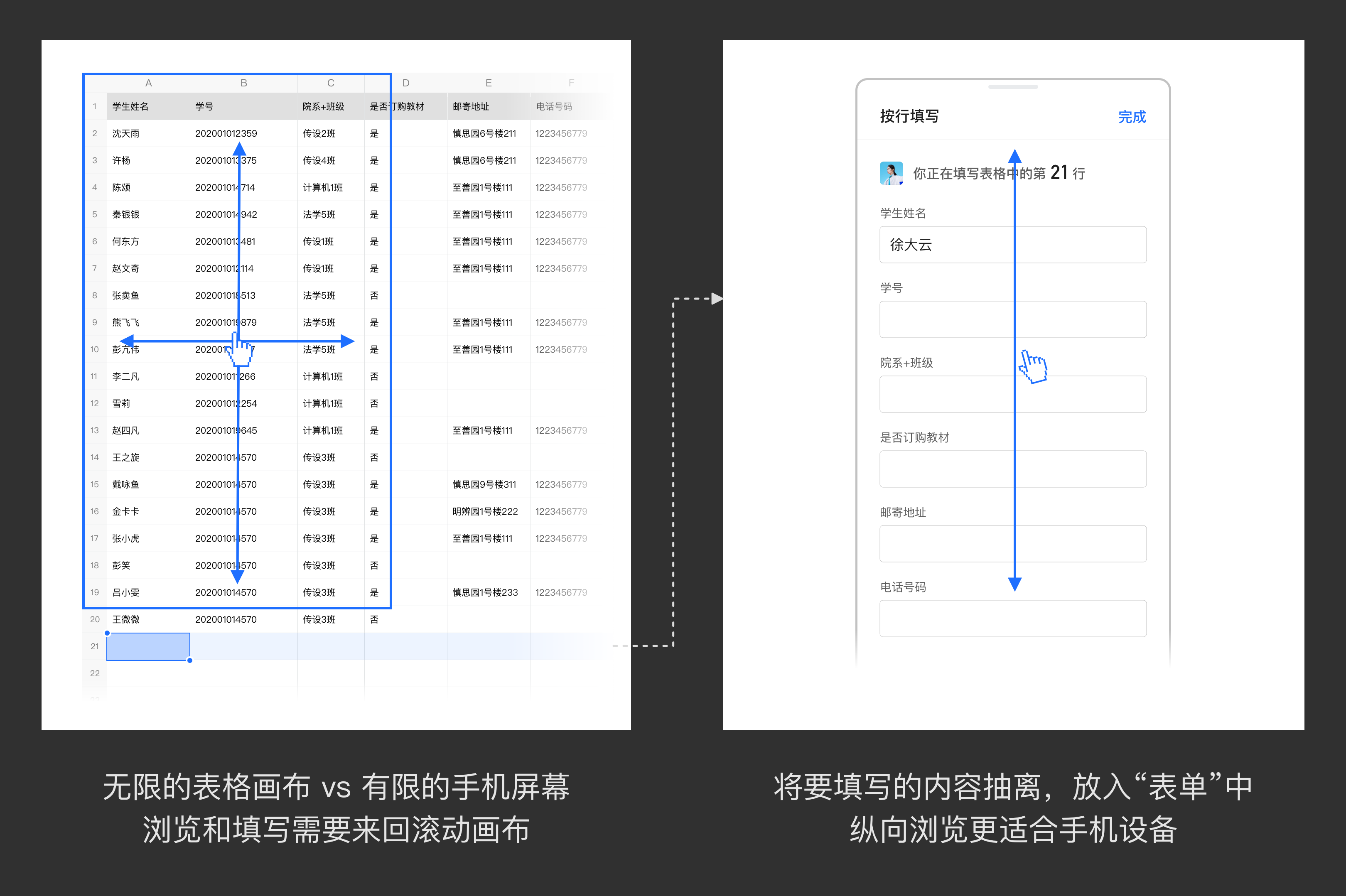
以上都是从“感知”角度发现和分析问题,确认了“存在这么一个问题”,然后提出了一个可行的想法。往往这个时候,我们容易为之兴奋。
但是如果我们坚持更精益的投入产出比,我们应当评估“这是不是一个要优先解决的问题”,即评估收益:改变Excel移动端的输入体验,能带来什么收益?
首先,我们做正负向评估。
|正向评估:如果做,用户可以在手机端更顺畅地录入信息,避免串行删改的错误。虽然这不足以吸引新用户使用我们的产品,但这个体验未在竞品实现,能形成差异化的记忆点,也许能带来好的口碑。
|负向评估:如果不做,手机端的Excel输入体验跟其他竞品无差,用户倒不会因此流失,但是创建人会因为协作者的犯错苦恼,也许会因此转为采用“IM一对一沟通”来避免出错。
然后是设定数据目标:如果这个功能落到数据板上,能作何贡献?
|数据导向:我们预期这个功能能够通过提升手机端的输入体验,来避免用户出错,降低创建人整理数据的负担,以提高用户留存(而非预期这是一个拉新功能)。并且,设计假设正确,应该能通过一些数据指标看到用户的行为变化。
最后,对比同期提出的几个产品需求,评估优先级。
|比对优先级:假设Excel按行填写的需求是A(图中黄色点),同期有一个影响文档安全分享的需求B。如果我们按照正负向评估去考量优先级,将AB两个需求都放在象限图里,越外层越应该优先处理,那么我们就应该优先处理需求B。
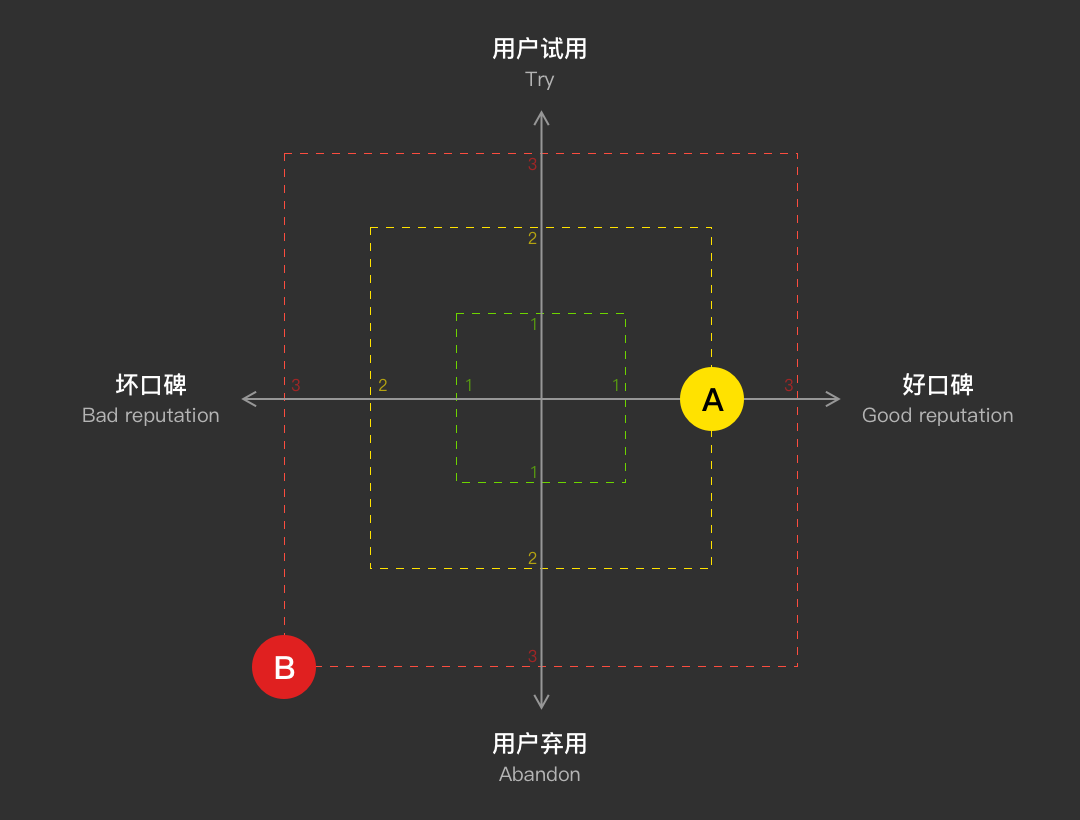
以上是为了将思维可视化呈现给读者,实操时更重要的是数据意识和敏感度。图示仅供参考,用何种形式表达不重要。
掌握一套清晰的需求评审思路,才有话语权去讨论这个需求是做还是不做、即刻要做还是延后再做。这不仅仅是UX设计师需要具备的目标导向思维和需求分析能力,而是整个团队都应该建立的数据意识和工作流。这也适用于对设计师提案的自我审查,避免自娱自乐。
2/ 需求挖掘:数据作为产品健康度的体检指标,为设计圈定问题域
产品在不同的成长阶段关注的短期效益会有所不同。初创期,产品先要验证其假设的需求是不是用户真实需求、商业模式是否可行。当产品发展到一定的用户规模,我们可以通过对比关键数据指标,去判断现阶段是否符合预期。这就像我们去医院抽血做体检,血样指标可以反映我们当前是否健康。
如何检验产品健康度呢?我们首先关注宏观的数据转化是否符合预期,即AARRR。海盗指标这一套,想必大家耳熟能详。但对设计师来说,难点在于如何将宏观数据转化与具体的用户使用场景进行关联,进而落实到具体的设计任务。
以腾讯文档为例,在线文档的核心用户价值是“从创作到协作的多人多端无缝同步”,因此我们定义用户的关键路径是“创作→分享→协作”,即:

基于关键路径,我们继续下钻分析每一个环节,建立用于监控“转化质量”的行为漏斗。比如在“分享”这一步,落到APP里,这个行为漏斗是:
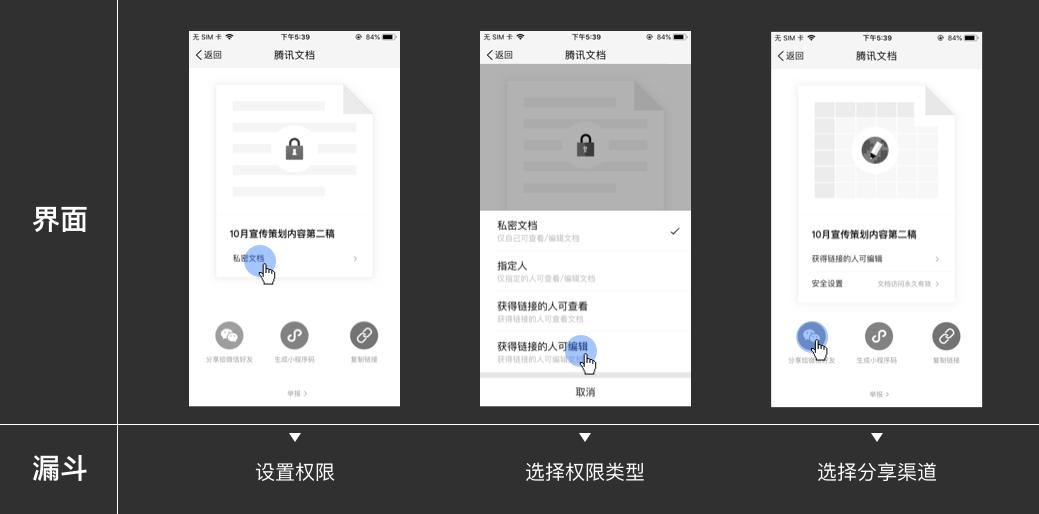
我们发现仅30%的创建人在分享文档前设置了非私密权限——这个数据并不符合我们的预期,因为这会导致创建人分享文档后,协作人无法直接查看或编辑文档。协作人需要进行权限申请,创建人则需要处理相应的权限申请通知或更改权限,从“申请权限”到“审批通过”的时间差降低了协作效率。
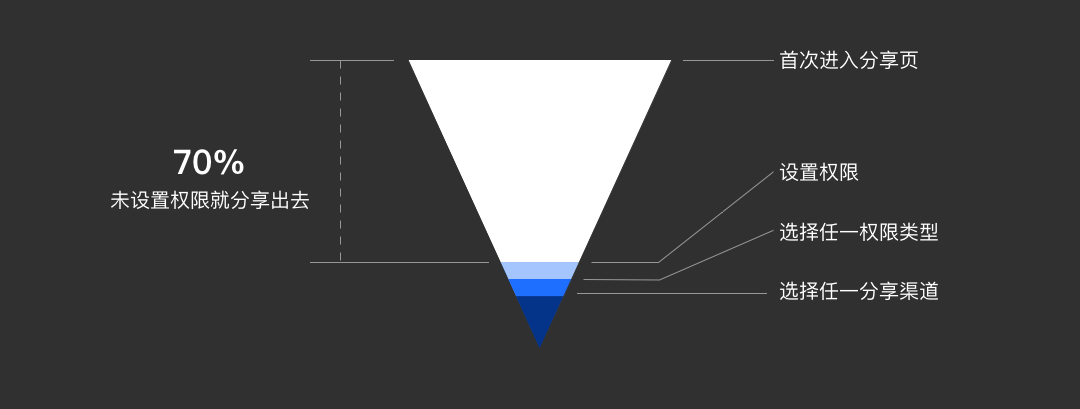
我们进一步去找关联的数据指标,来确认“这给用户造成了困扰”——“有多少用户在文档分享出去之后再返回来设置权限”‘、“一个创建者平均要处理多少次权限申请”等等。
通过小范围的用户测试,我们了解到“权限设置”是一个视觉盲区。于是,我们优化分享页的信息展示,来改善“用户看不见权限设置”这个问题。另外,当创建人在处理权限申请的通知时,提供修改权限的入口,以避免重复处理同一个文档的申请消息。
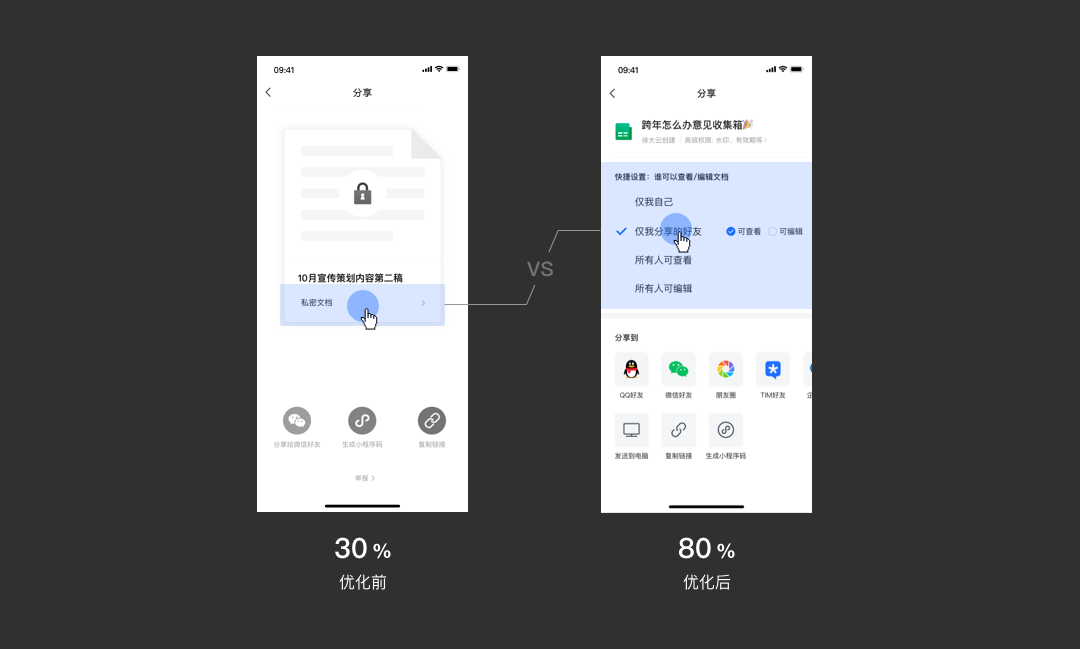
最终,我们将“分享前进行权限设置”的转化提高到80%——吹牛的,业务数据太敏感,无法以真实数据跟大家分享,本文的数字皆为脱敏数据。
这就像一个剥洋葱的过程。先找到产品的核心价值和对应的主路径,再拆解到对应的多个用户任务流,关注微观的某个环节转化是否有问题。利用数据诊断产品健康度,然后继续用数据或其他研究方法下钻,下钻到可以落地到设计点的层面。
3/ 设计决策:借鉴用户行为数据,对方案进行快速决策
2016年听了白木彰老师在杭州的一次现场分享,他对“Design”的理解非常透彻。“Sign”是“标志”,应该是大家最共通的常识,就像国旗是这个国家的sign。那“De”是什么?台下有人回答“重新定义”,而白木彰很自信地说:“不,这是一个否定词”。

对于UX来说,同理。每一次的设计都是一次否定,否定现有体验的合理性,否定现有的产品、服务或某一功能完全满足需求。反过来想,则是审问自己的设计方案:每一次的“否定”,真的更好吗?
这里举一个“小需求”为例:腾讯文档Excel的PC端右键菜单高度优化。笔者目前负责腾讯文档编辑模块的UX工作,日常就是很多这样的“小优化”,其实这更加考验数据敏感度和对“严谨”的坚持。
需求背景就是用户反馈“右键菜单太长了,小屏幕看不到菜单底部的内容”。
“展示问题”的解法有很多:
解法1/ 用UI手段,降低单个menu item的高度。

解法2/ 重新归类,通过折叠来缩短菜单。

解法3/ 当菜单无法完整展示,重新锚定其在屏幕的坐标。
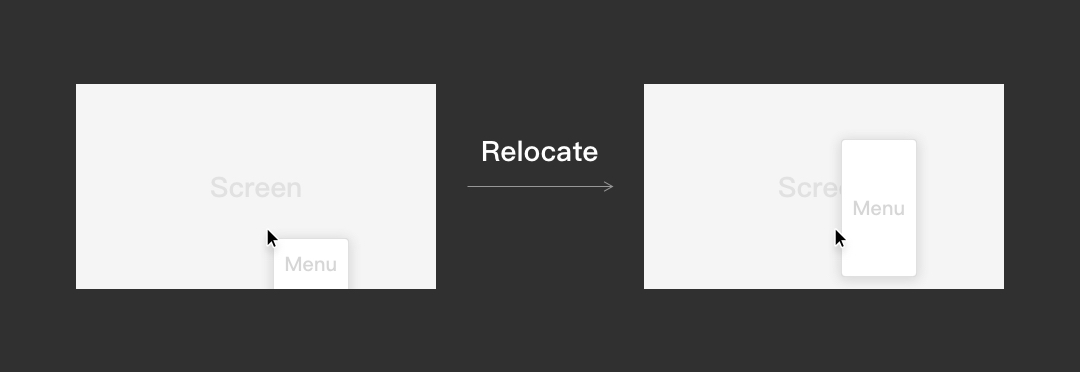
对比竞品,确实有表格产品通过(2)去解决这个问题,但是我们捞数据发现:右键菜单中,插入行列是高频操作(红色部分),点击次数比其他功能高5~130倍,且人均点击量分别是3次和2次。我们决定不去对增加行列进行菜单折叠,因为这样做虽然我们解决了“菜单太高”的问题,但降低了点击效率。

接到某个需求的“A问题”,我们容易一叶障目。但是,会不会因为我们解决了A问题而引发B问题呢?数据帮助我们快速决策,避免B问题的出现。谨慎对待每一次小设计,因为每一次小设计都是一次否定。
4/ 设计实验:采用数据实验对设计方案进行择优或改进
大家对数据实验应该不陌生,常用的方法有AB测试和灰度测试,是一种控制变量的抽样实验方法。
AB测试是指通过抽取抽取等量用户样本进行AB两个设计方案的投放,对比两组数据,进行方案择优。这两个方案的差异要严格控制在“仅有一个因素的差异”。这跟我们初中做生物实验论证“一棵小树的生长需要阳光”的思路一样:两组等量的小树,一组有阳光,一组没有阳光,经历相同的时间后对比生长的平均高度差。水、空气、养分等其他条件要严格一致。因此大改版等“多变量”的设计并不适用于AB测试去印证。
大改版则通过灰度测试或拆分变量去做AB测试来确保效果。灰度测试是指如果软件要在不久的将来推出一个全新的功能,或者做一次比较重大的改版的话,要先进行一个小范围的尝试工作,然后再慢慢放量,直到这个全新的功能覆盖到所有用户。也就是说在全量发布的黑白之间有一个灰,所以这种方法也通常被称为灰度测试。
设计师需要观察综合的数据指标,以腾讯文档为例常规的指标有:PV、UV、人均点击次数、功能渗透率、使用该功能的留存率等等。另外是多渠道收集用户反馈,包括腾讯文档的“吐个槽”社区、微博搜索关键词、随访身边的用户朋友等。
Conclusion
——————————
结语
数据化设计不是对“精心打磨体验”的否定。恰恰相反,对设计工匠来说,数据分析能力是一种新的“打磨工具”,提倡在设计实施和决策过程中更科学和客观。UX和数据的关系,就像我们期望鞋子被量产之前能够有数据佐证“这款鞋好看好穿好卖”,而不是否定“好看又好穿的鞋子能带来更好的销量”。
最后,“价值-设计-数据”是一个动态课题,必然随着业界经验的沉淀和数据工具的发展,不断迭代。欢迎留言区交流和指正 :-)

感谢阅读,以上内容由腾讯ISUX团队参与设计,版权归SUPERFICTION、腾讯ISUX分别所有,转载请注明出处,违者必究,谢谢您的合作。注明出处格式:
文章来自公众号:
腾讯ISUX
(https://isux.tencent.com/articles/qq-sf)