如何衡量设计(改版)的效果

第一次写文,简单描述了各阶段衡量设计的方法,文章篇幅过长,浏览大概需十五分左右~


0.1 为什么要做
设计师同学们可能经常在公司遇到开发说:“你不就是个美工,没啥作用,谁上谁都行”,也有可能在面试时会经常遇到一个问题“你怎么衡量你的设计”。当然还可能是更多没有列举出的情况,那么作为设计师,当我们面对到这些问题时,是不是有时候会哑口无言、无从下手、有点懵逼。
为了体现自身的价值,为了证明你的工作,为了检验你的设计,我们要去采取一些行动,获取一些数据来衡量我们的设计或改版。
0.2 使用阶段
首先,要知道在什么阶段,我们可能需要来衡量设计(改版)的效果。其实也就是我们的目标是什么:是上线前的敏捷性测试,还是上线后的价值衡量。
如果是上线前我们会遇到的是认知走查或是可用性测试,上线后一般可能我们要去做一些用户研究和数据分析。
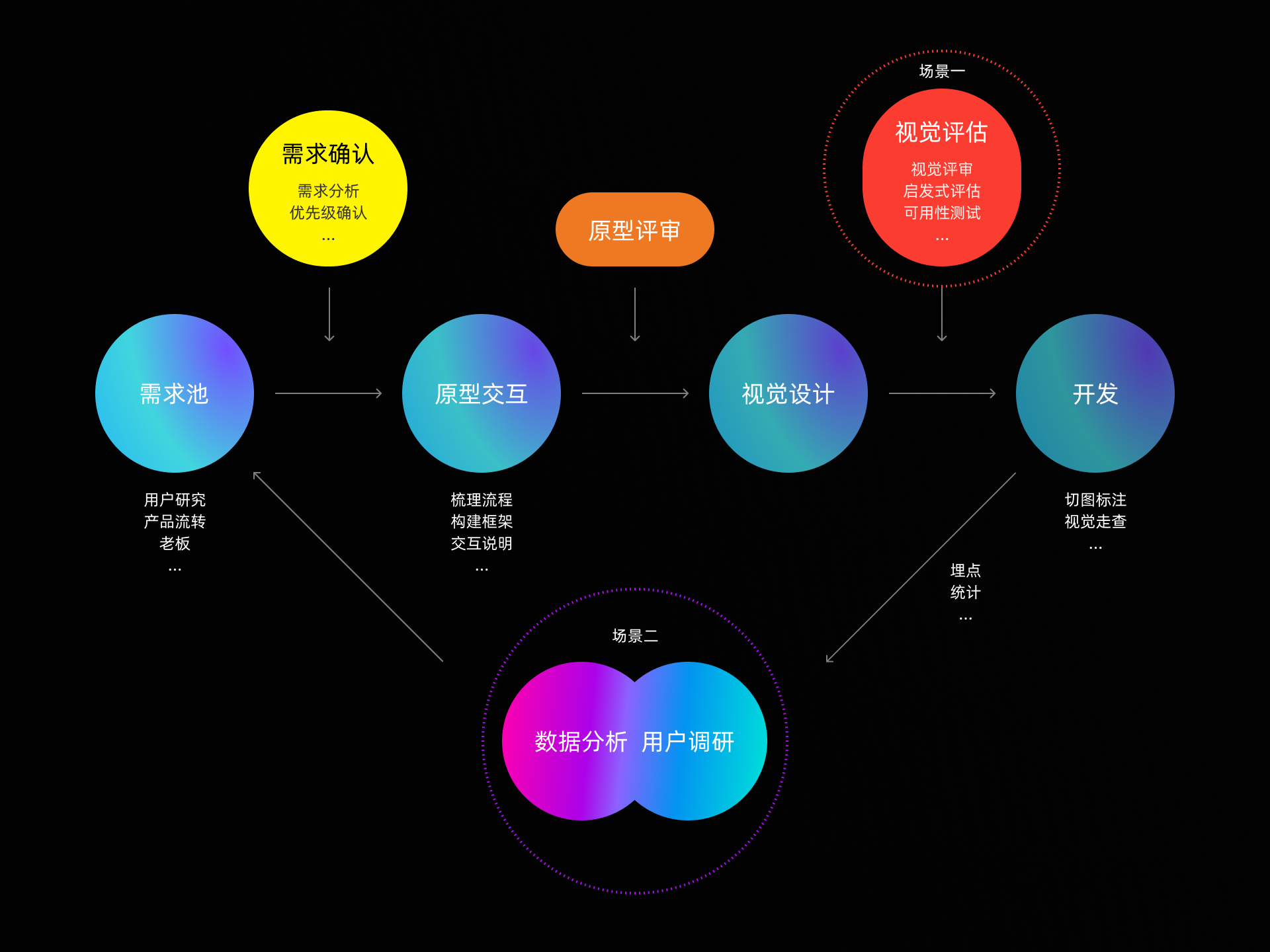

1.1 启发式评估
启发式评估就是使用一套简单、通用、有启发性的可用性原则来进行的可用性评估。即几个评审人员根据一些通用的可用性原则和自己的经验来发现产品的可用性问题。有试验表明,每个评审人员平均可以发现35%的可用性问题,而5个评审人员可以发现大约75%的可用性问题。

我们可以找身边的同事进行一场敏捷性的评估,发现我们设计的可用性问题,可能包含(交互流程、信息架构、视觉等等),然后进行调整保证设计所带来的价值。

完成评估后,进行问题分析、总结、讨论,找出可行的解决方案。
总结:根据启发式评估,我们可以快速的发现设计的问题,挖掘出用户潜在的需求,然后进行快速修改,从而减少产品的周期成本,也可以增加我们设计的说服力。
1.2 可用性测试
可用性测试是一种在真实情境下进行严格可用性评估方法。通过比较不同条件下的正确率、任务完成时间、用户主观满意度评价等指标发现产品存在等可用性问题。
可用性测试与启发式评估都是为了发现产品可用性问题,不同的是可用性测试可以在产品任何阶段适用,启发式评估一般是上线前的评估。
可用性测试分为用户测试和专家测试,一般来说招募用户测试成本可能需求更大,而专家测试会带来时间及认知的大幅度提升,所以如果我们没有大量的成本投入,一般会选择专家测试。
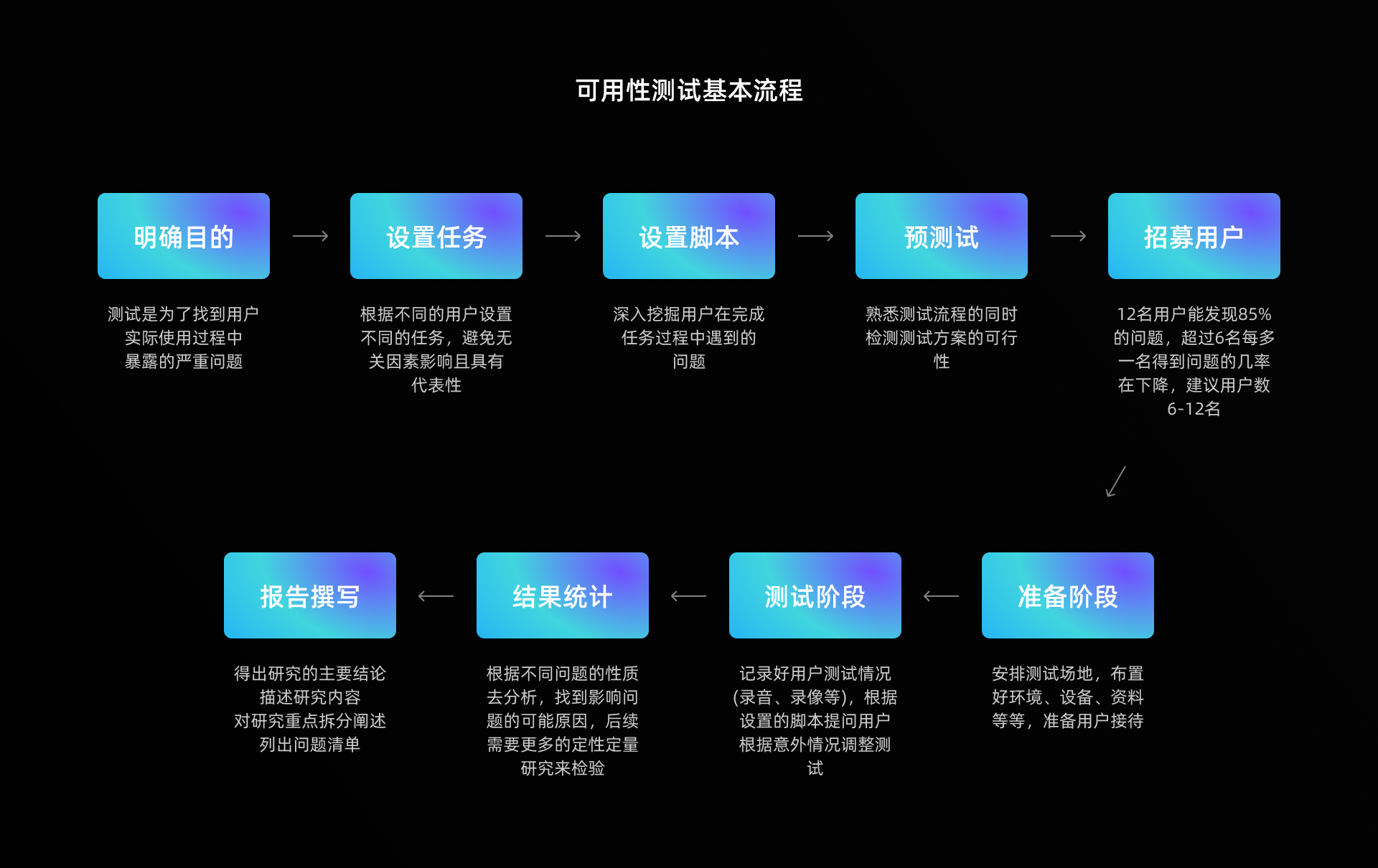
测试的过程中要保证客观性,尽量保证测试环境还原用户真实使用场景。在测试前,产品和设计师都会对产品可能存在的问题有个预判,所以提问时不要诱导用户。测试的目的是发现问题而不是验证问题。如果需要验证问题,后续需要大量的定性定量的研究。
因为人们思想或习惯的差异性,测试的结果往往让你意想不到。
总结:可用性测试可以利用客观的数据结果,使得测试结论更加具有说服力和可信度,从而去衡量我们的设计(改版)的效果。

2.1 数据分析
2.1.1 活跃度
一般情况下,我们设计或改版一个或多个新功能,用的人越多,表示设计或改版更可能是成功的(钉钉、政务类一些刚需或者是垄断类型的产品除外)。
那么我们通常会用到的两个指标:DAU日活和MAU月活。
活跃度在不同的公司衡量的标准不同,对外宣布一般都是登录数,如果内部使用可能是类似于电商开单、音乐类听歌、笔记类创建任务等等。
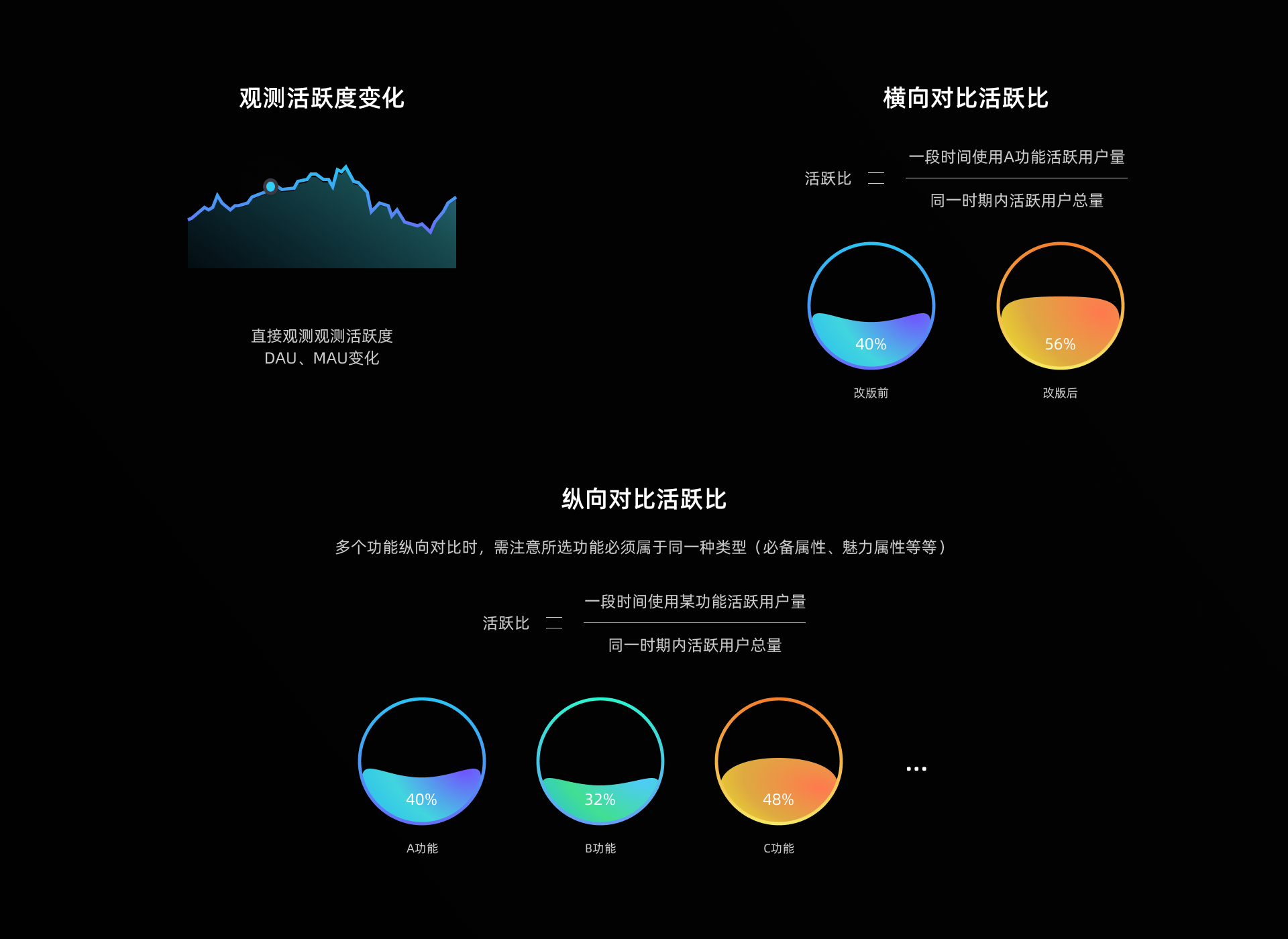
但是活跃度的多少,还会受到功能之外很多其他因素的影响,不能单纯只凭这一指标判断我们设计或改版的价值,还要结合其他指标多方面进行评估。
2.1.2 重复使用率
我们设计或改版的新功能,如果能够得到用户的认可,用户一定会重复的使用。反之,如果新功能存在糟糕的视觉、交互体验极差或是与用户心理预期偏差过大,用户往往是不会再使用此功能(钉钉、政务类一些刚需或者是垄断类型的产品除外)。
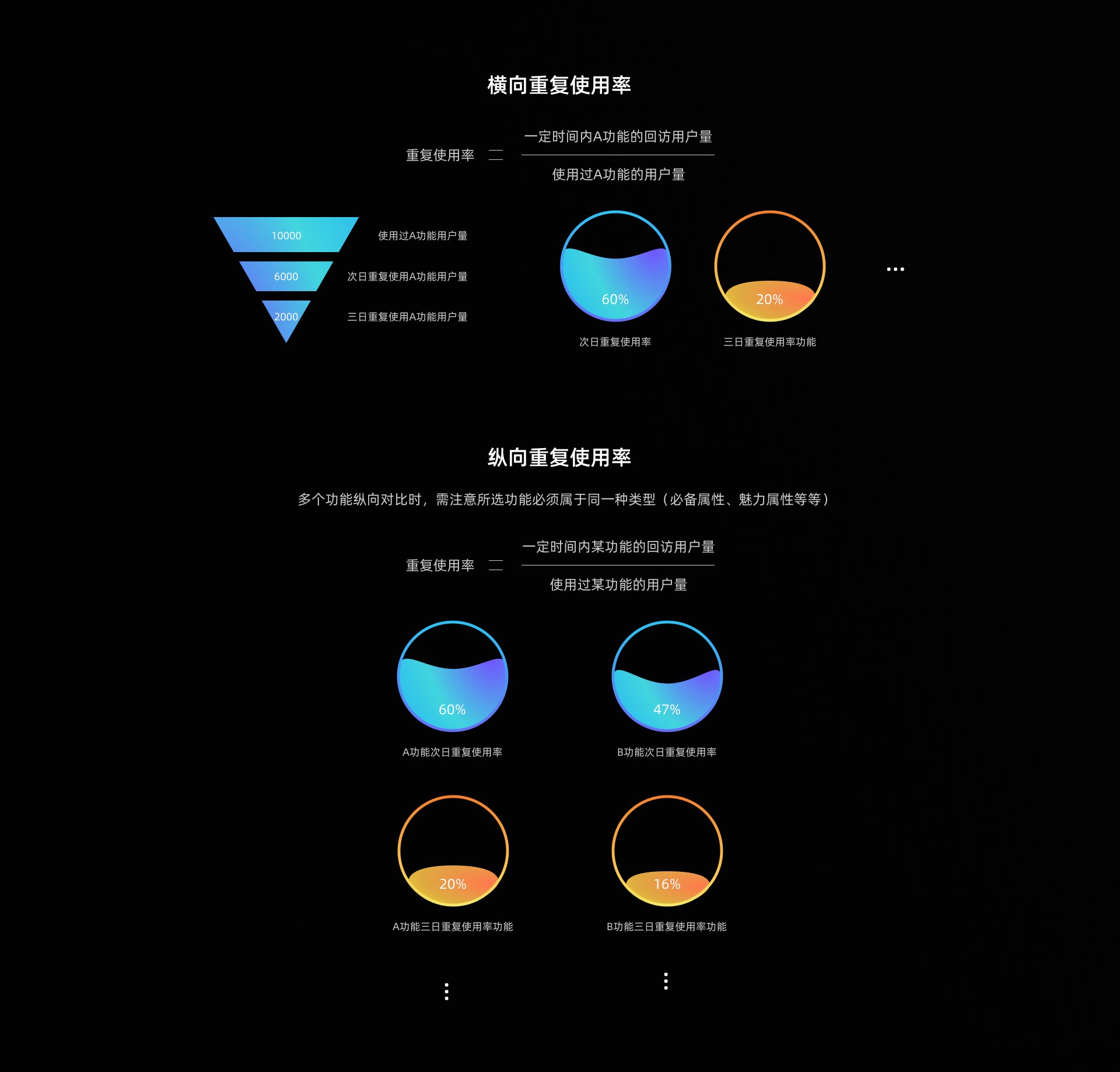
重复使用率越高,说明有越多的用户反复使用该功能,就能证明我们的设计是有价值的。
2.1.3 转化率、完成率
如果我们设计或改版的新功能处于某个用户使用流程中(电商产品的购买下单流程、分享红包流程等等),这个时候我们可以利用漏斗转化率或完成率来衡量我们设计的是否起到了优化作用。
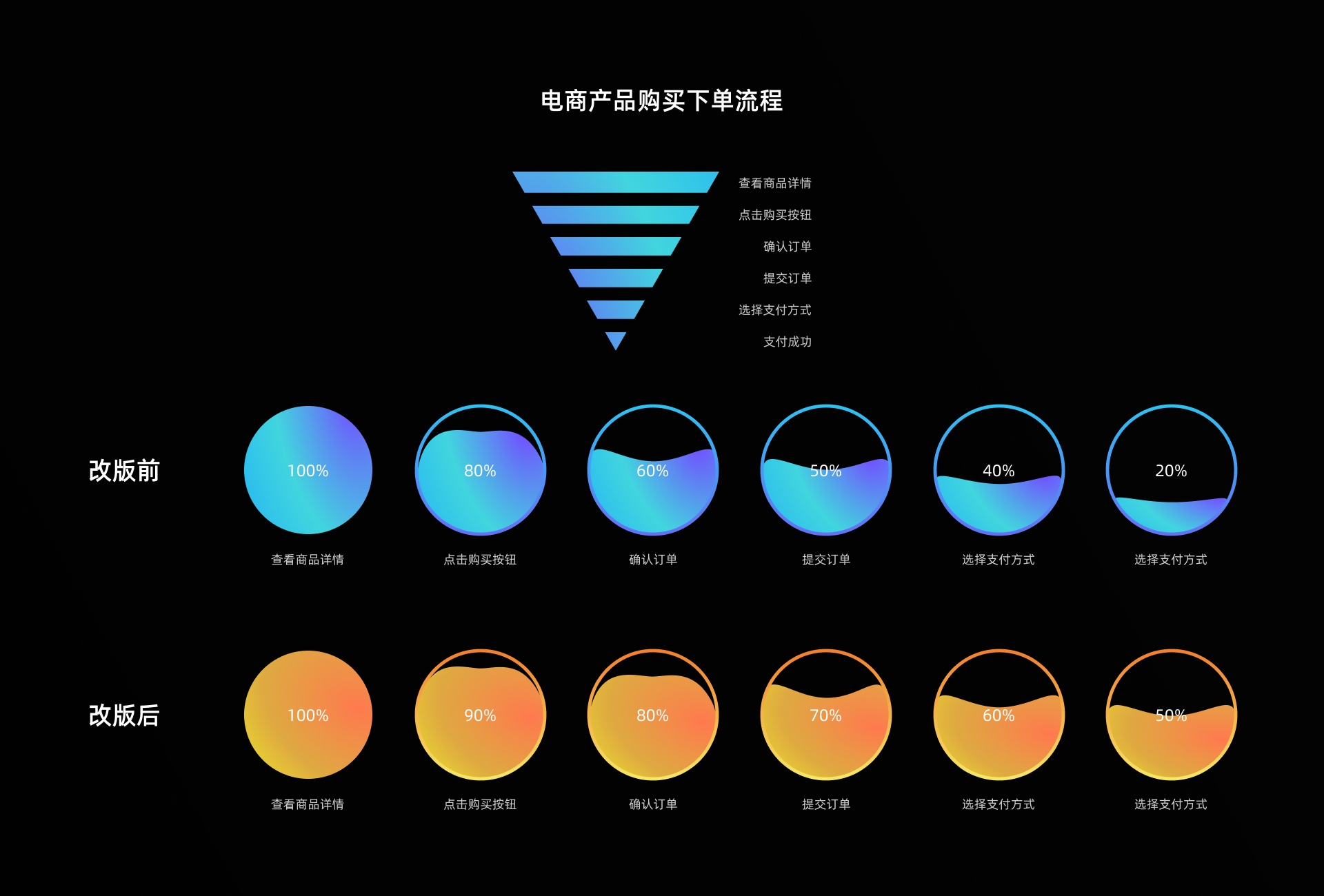
我们可以通过对比改版前后,用户使用流程的漏斗转化率或完成率的变化,转化率或完成率提升的越多,说明设计的效果越明显。从而评估出我们的设计的价值。
2.1.4 留存率
新增用户在初始时间后第N天的回访比例,即为N天留存率,常用指标有:次日留存率、周(7天)留存率、21天留存率、月(30天)留存率等。
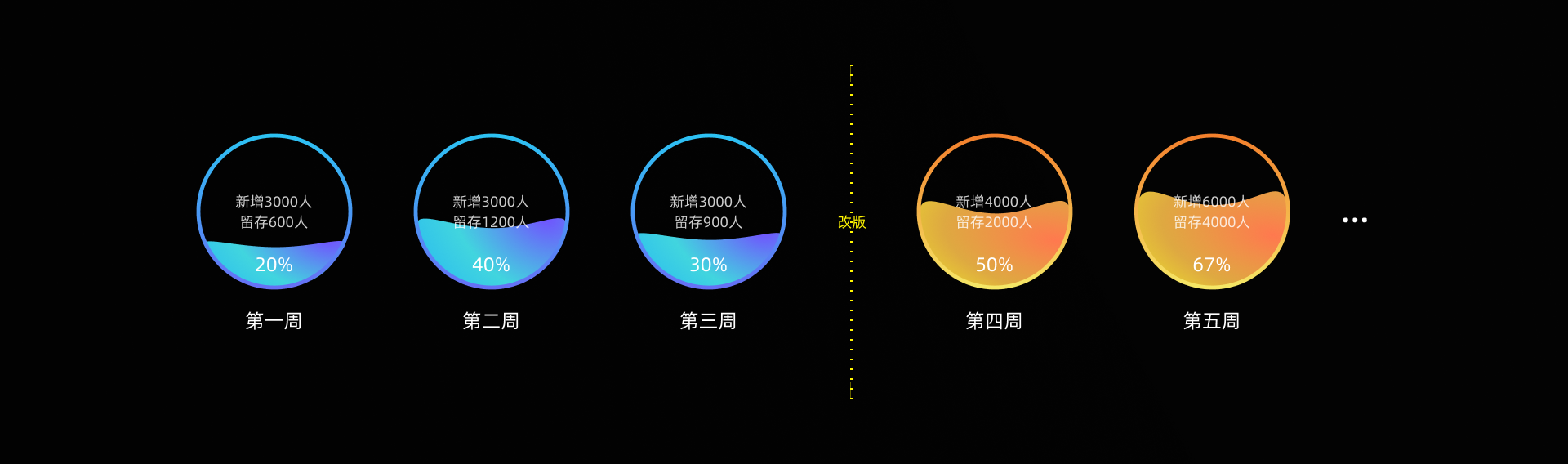
一般来说,一个优秀的设计或改版,会增加用户对产品的喜爱,而让用户频繁的使用产品。通过对比改版前后留存率的变化,可以衡量我们的改版设计的价值。
2.1.5 启动次数
一般情况下,我们的设计或改版上线后,能够让用户的启动次数提升,也能作为一个参考。但是同样会受到多种纬度的影响(例如电商双十一、各种造物节等等),不能够直观去衡量我们的设计。
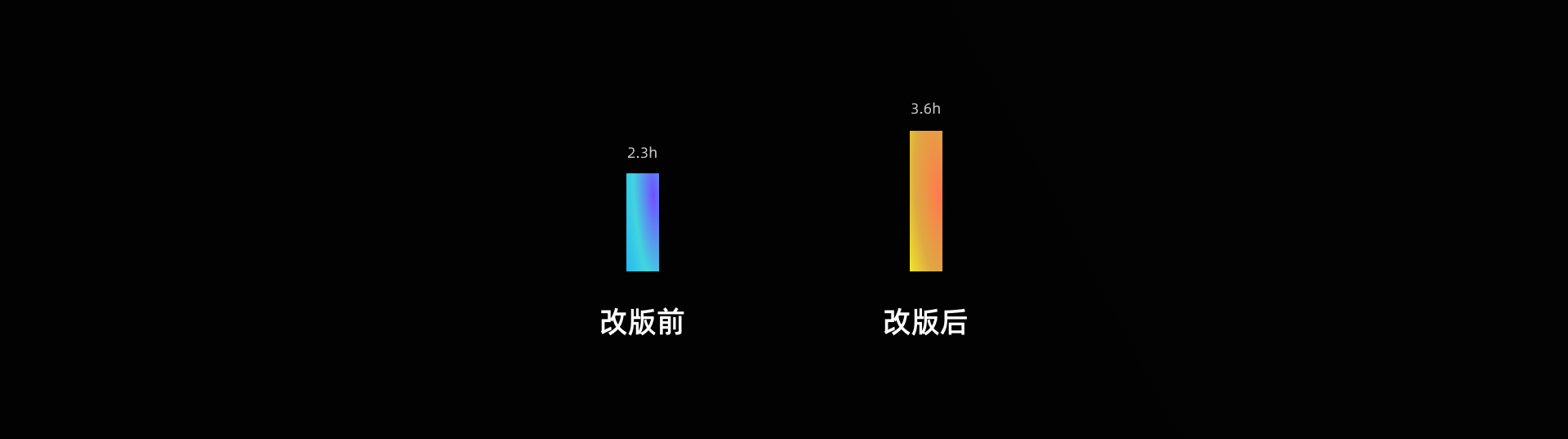
2.1.6 使用时长
产品的视觉、交互体验等会直接影响用户的,设计的好坏可能直接影响用户对产品的整体兴趣,所以通过体验设计上的优化是可能解决一部分使用时长的问题的。
我们可以通过对比改版前后使用时长,也可以作为印证我们价值的一方面。
2.1.7 用户行为记录
我们可以通过后台埋点,统计出用户的行为记录,是否和我们预期一致。如果和我们的预期越吻合,说明我们的设计是符合用户心智的,如果差别过大,可能需要继续进行分析、访谈等。
2.1.8 总结
单个指标的数据往往不能直观说明问题,若要衡量我们的设计,往往需要找到贴合产品的指标,控制变量,客观综合地去考量。每个产品都有自己的北极星指标(OMTM),每次设计也有每次的目的,设计师还应当多自驱的去寻找问题、发现问题、分析问题、解决问题。这样才能证明自己的价值。
2.2 问卷调研
当我们的产品新功能或是改版上线后,我们可以投放问卷,去统计主观上用户的感觉。从而去衡量我们设计的效果。
这里我们通常会用到到是用户满意度(CAST)、净推荐值(NPS)、用户费力度(CES)。
2.2.1 用户满意度(CAST)
CSAT要求用户评价对特定事件/体验的满意度,大都使用的是五点量表,包括五个选择:非常满意、满意、一般、不满意、非常不满意。

统计后得出结果,非常满意和满意的用户比例越大,则可能说明我们的设计是成功的。当然用户可能经常在中等范围回答问题,所以需要我们引导用户尽可能真实的评分,否则样本带来的反馈对我们没有意义。另外,用户的满意度不代表忠诚度,用户对我们满意并不代表会忠诚于产品。
所以,CAST只是我们衡量设计的一项指标,并不能完全说明设计的好坏。此外,我们为了进一步提升产品的体验,往往会回访那些选择非常不满意或者不满意的用户,进行用户访谈,找出他们对产品不满意的地方,推进下一步改版或设计。
2.2.2 净推荐值(NPS)
净推荐值最早是由贝恩咨询企业客户忠诚度业务的创始人佛瑞德·赖克霍徳(Fred Reichheld)在2003提出,它通过测量用户的推荐意愿,从而了解用户的忠诚度。
根据愿意推荐的程度让客户在0~10之间打分并根据得分情况来判断三种用户:
推荐者Promoters(得分在9~10之间):是具有狂热忠诚度的人,他们会继续购买并引荐给其他人。
被动者Passives(得分在7~8之间):总体满意但并不狂热,将会考虑其他竞争对手的产品。
贬损者Detractors(得分在 0~6之间):使用并不满意或者对你的企业没有忠诚度。

NPS询问的是意愿而不是情感,对用户来说更容易回答,且相比于CSAT,这个指标更为直观,能够直接反应客户对产品的忠诚度。
因为NPS往往会受到很多其他因素影响,所以往往我们会配合CAST一起调研,更能说明问题。
2.2.3 用户非力度(CES)
CES是指用户在使用产品或某个功能时,所花费的成本。一般是在用户刚做完操作后询问,否则用户可能忘记自己完成操作的实际体验。

我们应该想办法减少用为解决问题而付出的使用成本。CES可以帮助我们找出可优化的方向,较低的费力度与用户留存有关,从而可以增加用户粘性。
2.2.4 总结
我们往往会同时使用这三项指标去调研,得出定量的结果后一定要继续洞察,对各项指标结果的原因进行深入探讨和挖掘。例如客户费力度,如果用户不会使用产品或者使用中出现了错误等,我们要找出原因,并且解决。
2.3 用户访谈
用户访谈可以分为:
无结构化访谈:又可以叫做深度访谈,类似焦点小组,抛出一个一个问题讨论,用户的答案和结果是无法预测的,对访谈员的要求高十分需要访谈技巧,而且文本编码难以统计处理和定量分析,访谈市场也不好控制,一般至少为1小时左右。
结构化访谈:类似于拿着问卷访谈,非常标准化,能够快统计结果进行量化分析,但是深入讨论有限。
半结构化访谈:综合前两种的形式,并且是我们最为常用的形式,即可未我们收集到定量统计进行分析,又可以深入挖掘一些问卷得不到的原因。
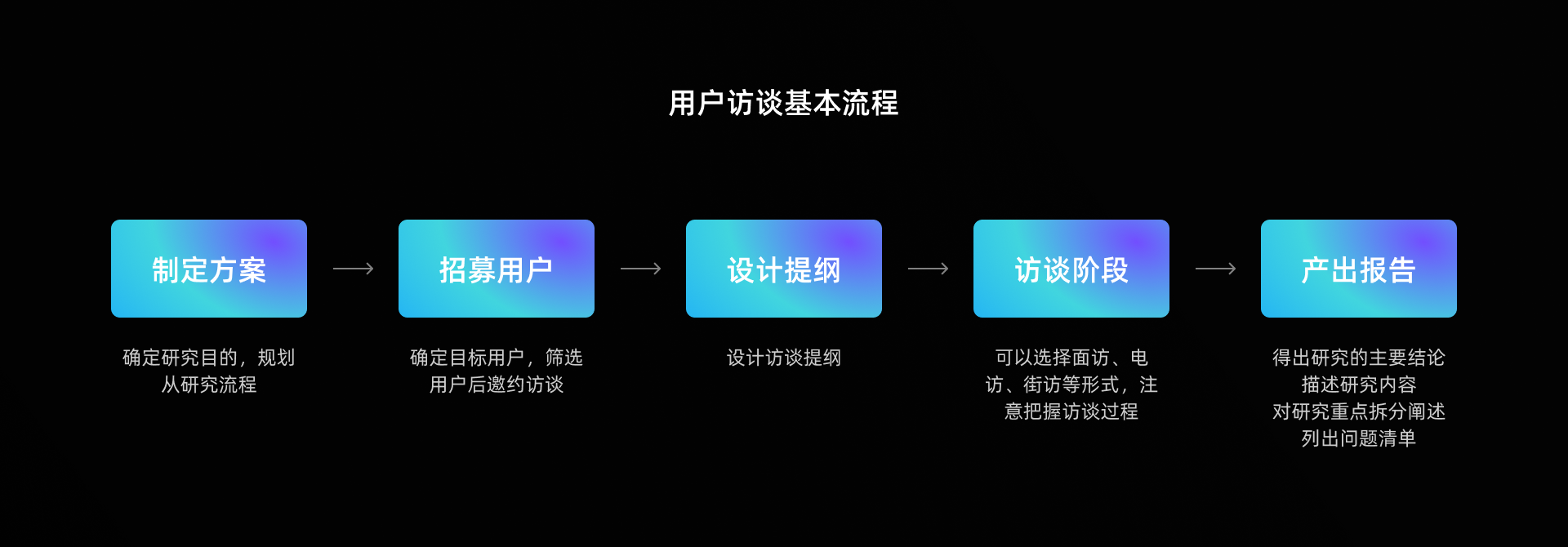
访谈的目的是为了挖掘问题背后的原因,我们一定要在访谈前做好准备,访谈中当用户不知道怎么回答时,一定要做好引导,也可以对问题进行一些话术上的转变,从而让用户表达出真实的想法。访谈后做好总结分析。

衡量我们设计或改版的好坏,有许多的指标或者是方法,重要的不是为了衡量而衡量,而是要为提升用户体验做准备,找出潜在问题并解决,才能真正的证明我们的价值。
用户体验的提升是一个长期的、变化的、复杂的过程,使用什么方法、使用哪些指标本身并不是一成不变的,更重要的是使我们的设计带来对用户、业务、产品多方面的价值。